目录
目录
1.K8S介绍
2.让数据持久化
3.K8S存储方案
4.K8S的一些组件和功能
5.你知道哪些K8S方面的资源
6.K8S对资源管理对象的监控
7.K8S监控使用什么 有哪些组件
8.Prometheus 的监控体系
9.pod健康状态的检查和探针的区别
10.集群内、外部的pod怎么访问
11.ingress数据链路怎么走向
12.pod重启策略
13.POD状态
14.POD里有哪些东西
不同node节点pod通讯的过程能讲一下嘛
15.简述Kubernetes 创建一个Pod的主要流程?
16.pod的能达到多少
17.node资源限制
18.用户访问服务的流程
19.k8s添加新的node节点
20.K8S集群网络
21.kube-proxy中使用ipvs与iptables的比较
22.压缩镜像
23.namespace怎么使用 namespace之间怎么协做
24.mq做过哪些运维工作
25.一般怎么部署mq
26.ELK日志收集是怎样的链路
27.日志有哪些操作
Calico插件你们了解过么 里面有哪些模式
1.K8S介绍
Kubernetes是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes能够进行应用的自动化部署和扩缩容。在Kubernetes中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes积累了作为Google生产环境运行工作负载15年的经验,并吸收了来自于社区的最佳想法和实践。Kubernetes经过这几年的快速发展,形成了一个大的生态环境,Google在2014年将Kubernetes作为开源项目。Kubernetes的关键特性包括:
- 自动化装箱:在不牺牲可用性的条件下,基于容器对资源的要求和约束自动部署容器。同时,为了提高利用率和节省更多资源,将关键和最佳工作量结合在一起。
- 自愈能力:当容器失败时,会对容器进行重启;当所部署的Node节点有问题时,会对容器进行重新部署和重新调度;当容器未通过监控检查时,会关闭此容器;直到容器正常运行时,才会对外提供服务。
- 水平扩容:通过简单的命令、用户界面或基于CPU的使用情况,能够对应用进行扩容和缩容。
- 服务发现和负载均衡:开发者不需要使用额外的服务发现机制,就能够基于Kubernetes进行服务发现和负载均衡。
- 自动发布和回滚:Kubernetes能够程序化的发布应用和相关的配置。如果发布有问题,Kubernetes将能够回归发生的变更。
- 保密和配置管理:在不需要重新构建镜像的情况下,可以部署和更新保密和应用配置。
- 存储编排:自动挂接存储系统,这些存储系统可以来自于本地、公共云提供商(例如:GCP和AWS)、网络存储(例如:NFS、iSCSI、Gluster、Ceph、Cinder和Floker等)。
2.让数据持久化
利用NFS-[pv/pvc]实现k8s持久化存储
上面创建了一个pv 挂在了所有的nginx日志目录是有问题的, nginx日志目录应该单独存储,单独存储nginx日志设置:可手动创建多个pvc进行挂在或者进行 volumeClaimTemplates: 自动创建pvc进行挂在。
3.K8S存储方案
pv与pvc
4.K8S的一些组件和功能
etcd:保存了整个集群的状态
APIServer:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
controller-manager:负责维护集群核心对象的状态,比如故障检测、自动扩展、滚动更新
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
kubelet:负责维持容器的生命周期,同时也负责Volume和网络的管理
kube-proxy:负责为Server提供cluster内部的服务发现和负载均衡
5.你知道哪些K8S方面的资源
1、创建pod资源
2、ReplicationController资源
3、deployment资源
4、service资源
6.K8S对资源管理对象的监控
metrics-server是集群核心监控数据的聚合器,metrics-server提供了/apis/metrics.k8s.io接口,通过这个接口,用户就可以调用集群的资源使用情况。集群中的节点上的kubelet都内置了cAdvisor服务(专门用于采集集群节点上所有资源情况)。只是cAdvisor缺少了merics-server,merics-server能提供一个统一的api接口。该api接口通过使用k8s中的kube-aggregator代理后端来开启一个访问入口。这个代理程序是集群自动开启的。
- Metrics-Server是集群核心监控数据的聚合器,用来替换之前的heapster。
- 容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务,有了Metrics-Server之后,用户就可以通过标准的 Kubernetes API 来访问到这些监控数据。
- Metrics API 只可以查询当前的度量数据,并不保存历史数据。
- Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 维护。
- 必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet Summary API 获取数据。
7.K8S监控使用什么 有哪些组件
Prometheus
Prometheus Server: 普罗米修斯的主服务器,端口号9090
NodeEXporter: 负责收集Host硬件信息和操作系统信息,端口号9100
cAdvisor:负责收集Host上运行的容器信息,端口号占用8080
Grafana:负责展示普罗米修斯监控界面,端口号3000
altermanager:等待接收prometheus发过来的告警信息,altermanager再发送给定义的收件人
8.Prometheus 的监控体系
系统层监控(需要监控的数据)
CPU、Load、Memory、swap、disk i/o、process 等
网络监控:网络设备、工作负载、网络延迟、丢包率等
中间件及基础设施类监控
消息中间件:kafka、redis、RocketMQ 等消息代理/中间件
WEB 服务器容器:tomcat、weblogic、apache、php、spring 系列
数据库/缓存数据库:MySQL、PostgreSQL、MogoDB、es、redis
应用层监控
用于衡量应用程序代码状态和性能
-
白盒监控:自省指标,等待被下载
-
黑盒监控:基于探针的监控方式,不会主动干预、影响数据
-
业务层监控
用于衡量应用程序的价值
-
如电商业务的销售量,QPS、dau 日活、转化率等。
-
业务接口:登入数量,注册数、订单量、搜索量和支付量。
9.pod健康状态的检查和探针的区别
Liveness 和 Readiness
LivenessProbe:指示容器是否正在运行,容器存活探针,失败,kublet杀死容器,根据restartPolicy值选择是否重启。如果容器不提供存活探针默认为Success
ReadinessProbe:指示容器是否准备好服务请求,若失败断点控制器将从Pod匹配的所有service的端点中删除该Pod的IP地址,初始化完成之前状态默认为Faliure。如果容器不提供就绪探针默认为Success
10.集群内、外部的pod怎么访问

外部 NodePort、LoadBalancer和Ingress
它们都是将集群外部流量导入到集群内的方式,只是实现方式不同。
简单理解:绑定域名访问,进行路由规则设定
11.ingress数据链路怎么走向
答: Kubernetes的Ingress资源对象,用于将不同URL的访问请求转发到后端不同的
Service,以实现HTTP层的业务路由机制。
Kubernetes使用了Ingress策略和Ingress Controller,两者结合并实现了一个完整的Ingress负载均衡器。使用Ingress进行负载分发时,Ingress Controller基于Ingress规则将客户端请求直接转发到Service对应的后端Endpoint ( Pod)上,从而跳过kube-proxy的转发功能,kube-proxy不再起作用,全过程为:ingress controller + ingress 规则---> services。
同时当Ingress Controller提供的是对外服务,则实际上实现的是边缘路由器的功能。
在Kubernetesv 1.1版中添加的Ingress用于从集群外部到集群内部Service的HTTP和HTTPS路由,流量从Internet到Ingress再到Services最后到Pod上,通常情况下,Ingress部署在所有的Node节点上。
Ingress可以配置提供服务外部访问的URL、负载均衡、终止SSL,并提供基于域名的虚拟主机。但Ingress不会暴露任意端口或协议。
12.pod重启策略
1、Pending
Pod创建已经提交给k8s,但是因为某种原因不能顺利创建,例如下载镜像慢,调度不成功等
故障分析:
Pending 说明 Pod 还没有调度到某个 Node 上面。可以通过 kubectl describe pod <pod-name> 命令查看到当前 Pod 的事件,进而判断为什么没有调度。可能的原因包括资源不足,集群内所有的Node都不满足该Pod请求的CPU、内存、GPU等资源
2、Running
Pod已经绑定到一个节点上了,并且已经创建了所有容器。只是有一个容器正在运行,或者在启动中,这个是属于POD的正常状态
3、Waiting
容器无法启动,需要检查是否打包了正确的镜像或者是否配置了正确的容器参数
故障分析:
镜像拉取失败,比如配置了镜像错误、Kubelet无法访问镜像、私有镜像的密钥配置错误、镜像太大,拉取超时等CNI网络错误,一般需要检查 CNI 网络插件的配置,比如无法配置Pod、无法分配IP地址,可以通过通过kubectl describe pod <pod-name>命令查看到当前Pod的事件
4、ImagePullBackOff
这也是我们测试环境常见的,通常是镜像拉取失败。
故障分析:
这种情况可以使用 docker pull <image> 来验证镜像是否可以正常拉取。或者docker images | grep <images>查看镜像是否存在(系统有时会因为资源问题自动删除一部分镜像)
4、CrashLoopBackOff
CrashLoopBackOff状态说明容器曾经启动了,但可能又异常退出了,可能是健康检查失败,容器进程退出等问题
故障分析:
此时可以先查看一下容器的日志,可以使用kubectl logs kubectl logs --previous这个命令来查看
5、Error
通常处于Error状态说明Pod启动过程中发生了错误
故障分析:
依赖的 ConfigMap、Secret 或者 PV 等不存在,请求的资源超过了管理员设置的限制,比如超过了LimitRange等违反集群的安全策略,比如违反了 PodSecurityPolicy等容器无权操作集群内的资源,比如开启RBAC后,需要为ServiceAccount配置角色绑定
6、Unkown
由于某中原因apiserver无法获取到Pod的状态。通常是由于Master与pod所在的主机失去连接了
故障分析:
从v1.5开始,Kubernetes不会因为Node失联而删除其上正在运行的Pod,而是将其标记为Terminating或Unknown状态,想要删除这些状态的 Pod 有三种方法
1)从集群中删除该Node。使用公有云时,kube-controller-manager 会在VM删除后自动删除对应的Node。而在物理机部署的集群中,需要管理员手动删除 Node(如 kubectl delete node <node-name>。
2)Node恢复正常。Kubelet会重新跟kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些Pod。
3)用户强制删除。用户可以执行 kubectl delete pods <pod> --grace-period=0 --force 强制删除 Pod。除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
7、Evicted
出现这种情况,多见于系统内存或硬盘资源不足,可df-h查看docker存储所在目录的资源使用情况,如果百分比大于85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
清除状态为Evicted的pod:
kubectl get pods | grep Evicted | awk '{print $1}' | xargs kubectl delete pod
删除所有状态异常的pod:
kubectl delete pods $(kubectl get pods | grep -v Running | awk '{print $1}')
最后我们整理下,常用的排障命令基本都是一下这些命令
kubectl get pod <pod-name> -o yaml 查看 Pod 的配置是否正确
kubectl describe pod <pod-name> 查看 Pod 的事件
kubectl logs <pod-name> [-c <container-name>] 查看容器日志
kubectl exec -it <pod-name> -- /bin/bash #进入容器查看
13.POD状态
Pending: API Server已经创建该Pod,且 Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
Running: Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
Succeeded: Pod内所有容器均成功执行退出,且不会重启。
Failed: Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
Unknown:由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
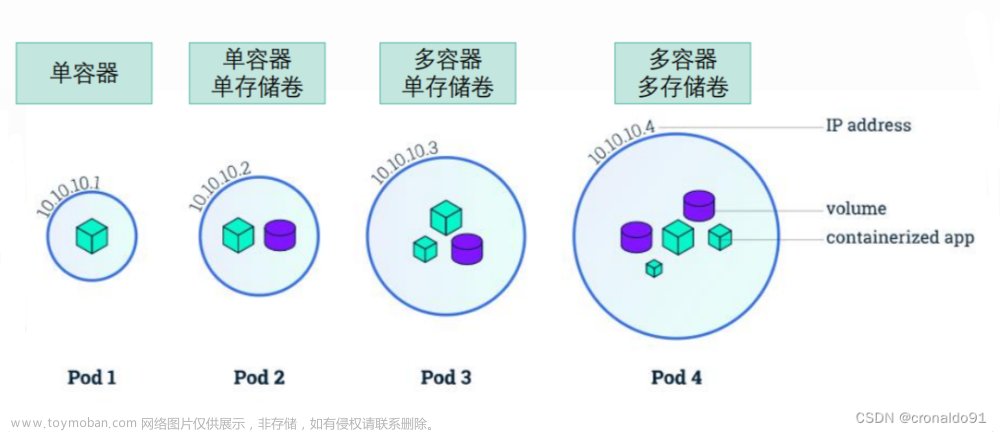
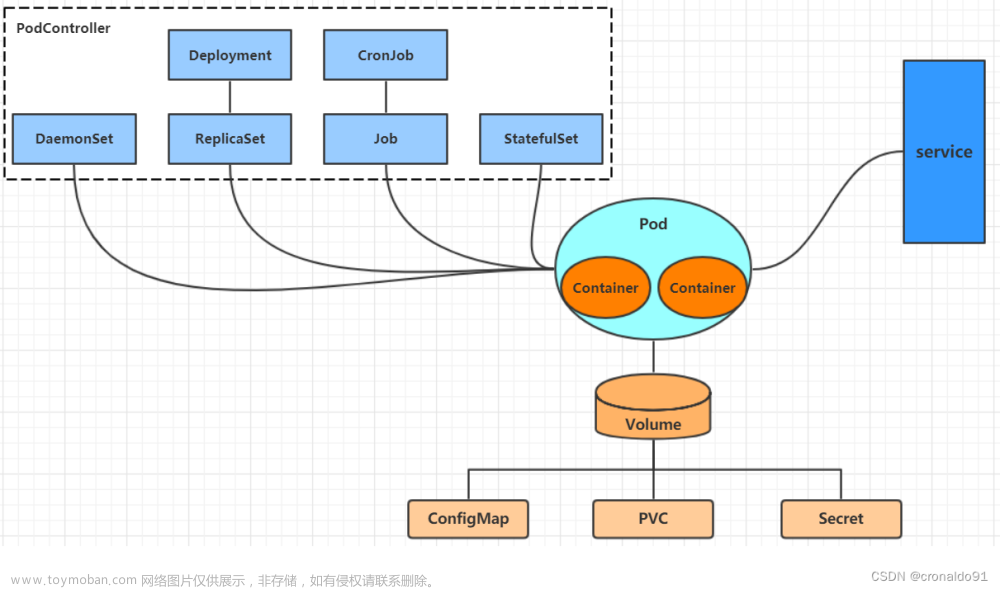
14.POD里有哪些东西
Pod 中的容器又能分三类:基础容器(pause);初始化容器;应用容器。
基础容器(pause):给 pod 中的所有应用容器提供网络和存储资源的共享;提供 init 进程。管理整个pod 里的容器组的生命周期
初始化容器(init 容器):是在应用容器之前完成所有 init 容器的启动,多个init容器是串行启动。每个 - Init容器都必须在下一个Init容器启动之前成功完成启动。
应用容器:提供应用程序业务。并行启动。
不同node节点pod通讯的过程能讲一下嘛
借助于cni(网络) 插件,我们使用的是flannel calico cannel
不同节点直接pod通讯
首先,定义两个节点 主机A POD-A 主机B POD-B
① POD-A首先会发送给docker 0 网桥(网关)
② docker 0会转发给flannel0网桥
PS:详细话术docker 0(网桥会被flannel 0 网桥以钩子函数的方式获取到转发信息)
③ flannel 0 会转发给flanneld (后台进程),flanned会到ETCD中查看ETCD维护的路由表条目/信息,确认往哪去发送
ETCD-路由表有哪些flanneld需要知道的信息
获取到pod-b所在的node节点 ——》主机B(MAC和IP)
获取到主机A如何到主机B,从哪个物理网卡通过 (宿主机)
④ flanned 会在转发给宿主机的物理网卡
⑤ 物理网卡会以UDP的方式转发数据包
(数据包中除了主机A和主机B的源IP和目标IP之外,还会将POD-A和POD-B的源/目标IP封装在UDP协议之后)
主机B接收到
① 首先解封装,发现源MAC/IP地址是找自己的(主机MAC/IP地址)
② UDP 转发过来,解封装之后,发现了封装在UDP内部的 POD-IP(源/目标)
③ 主机B的物理网卡就会发送给flanned进行处理
④ 而flanned会查询ETCD中维护的路由表信息,发现是自己的pod(需要确认找的是哪个docker网桥)
⑤ flanned 会发送给自己的flannel0网桥,flannel网桥再发送给对应的docker (0)网桥
⑥ docker 网桥(网关),会把这个数据包发送给对应的POD-B
15.简述Kubernetes 创建一个Pod的主要流程?
1.用户通过kubectl命名发起请求。
2.apiserver通过对应的kubeconfig进行认证,认证通过后将yaml中的Pod 信息存到etcd。
3.Controller-Manager通过apiserver的 watch接口发现了Pod信息的更新,执行该资源所依赖的拓扑结构整合,整合后将对应的信息交给apiserver,apiserver写到etcd,此时Pod已经可以被调度了。
4.Scheduler同样通过apiserver的watch接口更新到Pod可以被调度,通过算法给Pod分配节点,并将pod和对应节点绑定的信息交给apiserver,apiserver 写到etcd,然后将Pod交给kubelet。
5.kubelet收到 Pod后,调用CNI接口给Pod创建Pod网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载。
16.pod的能达到多少
一个node有7个
17.node资源限制
资源的限制类型
资源类型:
• CPU 的单位是核心数,内存的单位是字节。
• 一个容器申请0.5个CPU,就相当于申请1个CPU的一半,你也可以加个后缀 m 表示千分之一的概念。比如说100m的CPU,100豪的CPU和0.1个CPU都是一样的。
内存单位:
• K、M、G、T、P、E #通常是以1000为换算标准的。
• Ki、Mi、Gi、Ti、Pi、Ei #通常是以1024为换算标准的
内存限制 CPU限制 为namespace设置资源限制
18.用户访问服务的流程
1.DNS解析:客户端用户从浏览器输入www.baidu.com网站网址后回车,系统会查询本地hosts文件及DNS缓存信息,查找是否存在网址对应的IP解析记录。如果有就直接获取到IP地址,然后访问网站,一般第一次请求时,DNS缓存是没有解析记录的;
2.TCP连接:通过dns解析拿到ip地址后,就可以通过ip向服务器发送http请求了,因为http是工作在第七层应用层,tcp是工作在第四层传输层,所以发生http请求之前,还会进行tcp的三次握手。
3.发送HTTP请求:http的请求报文,主要包括,请求行,请求头部,空行,请求主体
4.服务器处理请求并返回HTTP报文
5.浏览器解析渲染页面
6.连接结束
19.k8s添加新的node节点
1、初始化系统
2、关闭防火墙,SELINUX,关闭SWAP分区,配置IPTABLES,建立对应的目录,添加用户,调整内核参数,安装必要的软件等等
3、添加docker仓库配置
4、从原有的node节点上拷贝执行文件、服务
5、在master节点上创建token
6、master服务器 签证证
20.K8S集群网络
Calico 是一套开源的网络和网络安全方案,用于容器、虚拟机、宿主机之前的网络连接,可以用在kubernetes、OpenShift、DockerEE、OpenStrack等PaaS或IaaS平台上。
Calico 组件概述
-
Felix:calico的核心组件,运行在每个节点上。主要的功能有接口管理、路由规则、ACL规则和状态报告-
接口管理:Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。 -
路由规则:Felix负责主机之间路由信息写到linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。 -
ACL规则:Felix负责将ACL策略写入到linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。 -
状态报告:Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。
-
-
Etcd:保证数据一致性的数据库,存储集群中节点的所有路由信息。为保证数据的可靠和容错建议至少三个以上etcd节点。 -
Orchestrator plugin:协调器插件负责允许kubernetes或OpenStack等原生云平台方便管理Calico,可以通过各自的API来配置Calico网络实现无缝集成。如kubernetes的cni网络插件。 -
Bird:BGP客户端,Calico在每个节点上的都会部署一个BGP客户端,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。当Felix将路由插入到Linux内核FIB中时,BGP客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量。 -
BGP Router Reflector:大型网络仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,所有节点需要 N^2 个连接,为了解决这个规模问题,可以采用BGP 的 Router Reflector的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。 -
Calicoctl: calico 命令行管理工具。
更优的资源利用
二层网络通讯需要依赖广播消息机制,广播消息的开销与 host 的数量呈指数级增长,Calico 使用的三层路由方法,则完全抑制了二层广播,减少了资源开销。
另外,二层网络使用 VLAN 隔离技术,天生有 4096 个规格限制,即便可以使用 vxlan 解决,但 vxlan 又带来了隧道开销的新问题。而 Calico 不使用 vlan 或 vxlan 技术,使资源利用率更高。
可扩展性
Calico 使用与 Internet 类似的方案,Internet 的网络比任何数据中心都大,Calico 同样天然具有可扩展性。
简单而更容易 debug
因为没有隧道,意味着 workloads 之间路径更短更简单,配置更少,在 host 上更容易进行 debug 调试。
更少的依赖
Calico 仅依赖三层路由可达。
可适配性
Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
21.kube-proxy中使用ipvs与iptables的比较
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙 而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模 扩张。
与iptables相比,IPVS拥有以下明显优势: 为大型集群提供了更好的可扩展性和性能; 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等); 支持服务器健康检查和连接重试等功能; 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
22.压缩镜像
优化方法1:不需要输出的指令丢入/dev/null (需要确定命令执行的是正确的)
优化方法2:减少RUN构建
优化方法3:多阶段构建(使用FROM命令生成多个镜像,将指定的镜像做为其他镜像的基础镜像环境来构建)
优化方法4: 使用更为轻量级的linux 发行版本
23.namespace怎么使用 namespace之间怎么协做
把名字改成自己想要的名字 主机可以自动实现连接
24.mq做过哪些运维工作
MQ集群的日常监控 zabbix监控MQ集群
短信报警:
如果MQ集群的队列数量超过100000就会发短信报警;或者MQ的服务出现故障也会发送短信报警
2:面监控:
登录zabbix监控页面查看是否有报警;
3:zabbix系统自带的管理页面查看:
使用admin账户登录zabbix系统自带的管理页面
4:此处的ready就是MQ集群整体所有的未消费消息数量,如果需要看具体那个队列堆积数量比较大
消息队列的优缺点
优点
上面已经说过了,系统解耦,异步调用,流量削峰。
缺点
①系统可用性降低:系统引入的外部依赖越多,系统要面对的风险越高,拿场景一来说,本来ABCD四个系统配合的好好的,没啥问题,但是你偏要弄个MQ进来插一脚,虽然好处挺多,但是万一MQ挂掉了呢,那样你系统不也就挂掉了。
②系统复杂程度提高:非要加个MQ进来,如何保证没有重复消费呢?如何处理消息丢失的情况?怎么保证消息传递的顺序?问题太多。
③一致性的问题:A系统处理完再传递给MQ就直接返回成功了,用户以为你这个请求成功了,但是,如果在BCD的系统里,BC两个系统写库成功,D系统写库失败了怎么办,这样就导致数据不一致了。
所以。消息队列其实是一套非常复杂的架构,你在享受MQ带来的好处的同时,也要做各种技术方案把MQ带来的一系列的问题解决掉,等一切都做好之后,系统的复杂程度硬生生提高了一个等级。
25.一般怎么部署mq
1、下载文件
2、创建namespace
3、创建持久化pv
4、访问测试
26.ELK日志收集是怎样的链路
- AppServer 是一个类似于 Nginx、Apache 的集群,其日志信息由 Logstash 来收集
- 往往为了减少网络问题所带来的瓶颈,会把 Logstash 服务放入前者的集群内,减少网络的消耗
- Logstash 把收集到的日志数据格式化后输出转存至 ES 数据库内(这是一个将日志进行集中化管理的过程)
- 随后,Kibana 对 ES 数据库内格式化后日志数据信息进行索引和存储
- 最后,Kibana 把其展示给客户端
27.日志有哪些操作
一.日志查看
1、进入日志文件所在的文件目录,比如:
cd /opt/tomcat7/logs
2、通过命令打开日志,分析需求场景打开需要的日志
比如:
tail -f catalina.out
3、常用命令一:tail
比如:
tail -f test.log (循环查看文件内容)
4、按照行号查询:cat(过滤出关键字附近的日志)
cat -n test.log |grep “订单号”
然后使用 head -n 20 查看查询结果里的向前20条记录
5、按照时间日期查询,(查询出一段时间内的记录)
sed -n ‘/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p’ test.log
查看该段时间内的日志
但是前提是用方法4试一下查询的哪个其实时间是不是存在
二.日志查找
1、命令模式下输入“/字符串”,例如“/Section 3”。
2、如果查找下一个,按“n”即可。
要自当前光标位置向上搜索,请使用以下命令:
/pattern Enter
其中,pattern表示要搜索的特定字符序列。
要自当前光标位置向下搜索,请使用以下命令:
?pattern Enter
三.日志清除
使用echo命令清空日志文件
echo -n “” > /server/tomcat/logs/catalina.out ==>要加上"-n"参数,默认情况下会"\n",也就是回车符
du -h /server/tomcat/logs/catalina.out
使用echo命令清空tomcat日志文件测试实例:
[root@zdz ~]# echo -n “” > /server/tomcat/logs/catalina.out
[root@zdz ~]# du -h /server/tomcat/logs/catalina.out
0 /server/tomcat/logs/catalina.out文章来源:https://www.toymoban.com/news/detail-585180.html
Calico插件你们了解过么 里面有哪些模式
Cni ipip模式BGP模式文章来源地址https://www.toymoban.com/news/detail-585180.html
到了这里,关于k8s面试题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!