基本特性
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点(简单理解为集群中的一个服务器),集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
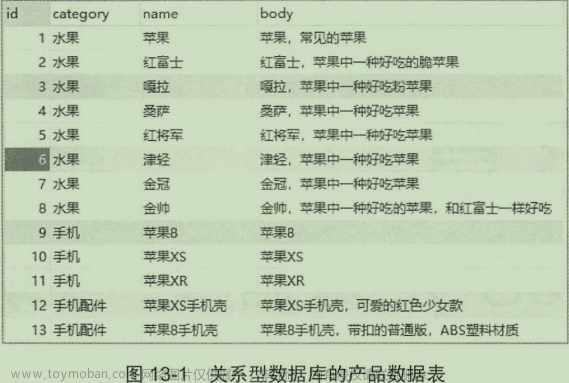
(4)Index:索引(简单理解就是一个数据库),包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(5)Type:类型(简单理解就是一张表),每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
(6)Document&field:文档(就是一行数据),es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
(7)shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
tips:
1.一个 Elasticsearch 集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识
2.Elasticsearch 的配置文件中可以通过 node.master、node.data 来设置节点类型
node.master:表示节点是否具有成为主节点的资格
node.data:表示节点是否存储数据
主节点管理集群,调度资源,数据节点存储数据,响应查询。如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了,实际工作中建议不要这样设置。
作用
Elasticsearch的强大之处在于搜索和分析
1.搜索
Elasticsearch 提供一种简单、一致的 REST API,用于管理你的集群以及索引和搜索数据。
Elasticsearch REST API 支持结构化查询、全文查询以及结合二者的复杂查询。结构化查询类似于你在 SQL 中构造的查询类型。例如,你可以在职员索引中搜索性别和年龄字段,并按雇佣日期字段对匹配项进行排序。全文查询,查找查询字符串匹配的所有文档,且返回按相关性——他们与搜索词语匹配程度——排序的文档。
除了搜索单个词语,你也可以执行短语搜索、相似性搜索和前缀搜索,甚至于地理空间或者其他数字数据搜索, Elasticsearch 在优化数据结构中索引非文本数据用于支持高性能地理和数字查询。
2.分析
Elasticsearch 聚合使你能够构建数据的复杂摘要,并深入了解关键度量、模式和趋势。聚合使你能回答以下类似的问题,而不是仅仅找到众所周知的“大海捞针”:
大海中有多少针?
针的平均长度是多少?
按制造商分类,针的平均长度是多少?
过去六个月,每个月加了多少针?
你也可以使用聚合去回答更多微妙的问题,比如:
你最受欢迎的针制造商是谁?
是否有特别或者异常的针束?
因为聚合借用了用于搜索的相同数据结构,所以他们也非常快。这使得你能实时分析和可视化数据。你的报告和仪表盘随着你的数据变化而更新,以便你可以基于最新的信息采取行动。
此外,聚合随着搜索请求一起运行。你可以搜索文档、过滤结果以及在单个请求中同时对同样的数据实时地执行分析。由于聚合是在特定搜索的上下文中计算的,你不仅能展示70号针的数量,你还能展示匹配你的用户搜索标准——比如不粘的绣花针——的 70 号针数量。
集群
多个es节点通过集群配置结合而成的分布式系统。你可以通过向集群添加服务器(节点)来增加容量,Elasticsearch 自动分布你的数据和查询到所有可用节点,并自动平衡多节点集群以提供规模和高可用性。
一个 Elasticsearch 索引只是一个或多个物理分片的逻辑组,其中每个分片实际上是一个独立索引。通过将索引中的文档分布 在多个分片上,并将这些分片分布在多个节点上,Elasticsearch 能确保冗余,这既能防止硬盘损坏也能在节点添加到集群时 增加查询容量。随着集群的伸缩,Elasticsearch 自动迁移分片以重新平衡集群
集群中最重要的是主分片和副本。一个索引的数据通常会被分成若干个分片,散列在不同的es节点上。索引中的每个文档都属于一个主分片。一个副本分片是一个主分片的精确复制。主分片和副本不能在同一个节点上,即A节点的副本在且仅在集群中任意非A节点。副本提供了数据冗余复制,以防止硬件故障,并能提供读取服务以提高整体效率——如搜索或者检索文档。
索引中的主分片的数量是索引创建时固定的,但副本分片数量可以随时更改而不会中断索引或者查询操作。文章来源:https://www.toymoban.com/news/detail-585565.html
ES集群和Redis集群的区别
往Redis集群插入数据首先要启动集群模式,连接到集群模式才能操作否则会报错,插入的数据会经过哈希计算槽位,路由到某个具体主节点再写入,各主节点之间数据是独立的,因此Redis集群数据的总量等于各主节点数据量之和。但是es有所不同,往es集群插入文档只要连接任意节点即可,插入的文档会被分成若干个数据分片散列在不同的节点上,同时每个主分片都会精确复制一份副分片用做备份恢复,相同数据的主副分片不能在同一个节点,因此es集群就无法对各自独立节点操作,只要集群配置一生效,查询插入哪怕一条数据都是整个集群多个节点的综合结果,而非在某一个节点就能完成。文章来源地址https://www.toymoban.com/news/detail-585565.html
到了这里,关于elasticsearch基本特性及集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![搜索引擎(大数据检索)论述[elasticsearch原理相关]](https://imgs.yssmx.com/Uploads/2024/01/402964-1.png)