我说个数:一个月5篇基于Fast Segment Anything的改进的论文就会出现哈哈哈哈。
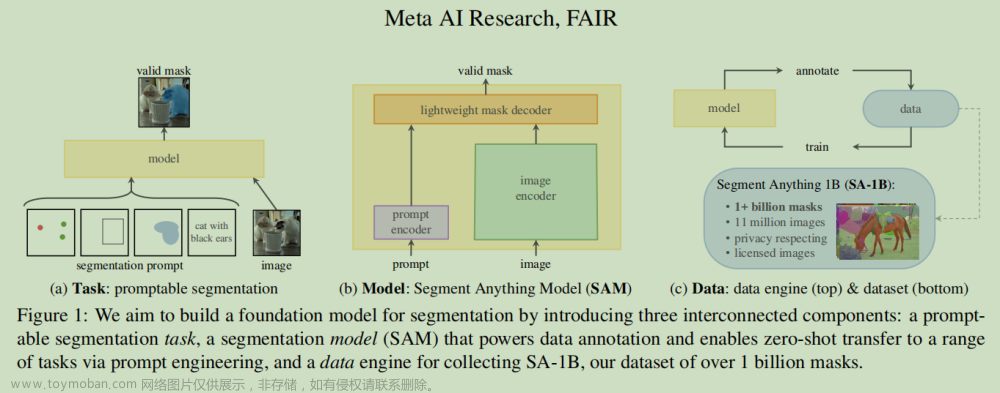
1.介绍
1.1 挑战
SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求,这给其实际部署带来了障碍
1.2 任务解耦
将分段任意任务解耦为两个顺序阶段,分别是是实例分段和提示引导选择。
- 第一阶段取决于基于卷积神经网络(CNN)的检测器的实现。它生成图像中所有实例的分割掩码。
- 在第二阶段,它输出与提示相对应的感兴趣区域。
1.3 核心贡献
首次将CNN检测器应用于Segment Anything任务
2.方法
提出的方法FastSAM的概述。该方法包括两个阶段,即所有实例分割(All-instance Segmentation )和提示引导选择(Prompt-guided Selection)。前一阶段是基础,第二阶段本质上是面向任务的后处理。

2.1 All-instance Segmentation 所有实例分割
2.1.1 YOLOv8
模型架构需要懂一点点yolov8的知识,可以参考详细解读YOLOv8的改进模块.
其实主要的改进就两点:
- YOLOv8的主干网和颈部模块用C2f模块取代了YOLOv5的C3模块。
- 头模块采用解耦结构,将分类头和检测头分离,并从基于锚转向无锚
2.1.2 YOLOv8-seg
将YOLACT原理应用于实例分割。主要负责了Fast Segment Anything中实例分割部分的工作。
2.2 Prompt-guided Selection 提示引导选择
第二阶段是使用各种提示来识别感兴趣的特定对象。它主要涉及点提示、框提示和文本提示的使用
2.2.1 Point prompt
将选定的点与从第一阶段获得的各种mask进行匹配。
2.2.2 Box prompt
长方体提示涉及在选定长方体和与第一阶段中的各种遮罩相对应的边界框之间执行并集交集(IoU)匹配。其目的是用所选框识别具有最高IoU分数的掩码,从而选择感兴趣的对象
2.2.3 Text prompt
在文本提示的情况下,使用CLIP[31]模型提取文本的相应文本嵌入。然后确定相应的图像嵌入,并使用相似性度量将其与每个掩模的内在特征相匹配。然后选择与文本提示的图像嵌入具有最高相似性得分的掩码
2.3 下游任务
以零样本边缘检测方法为例
2.3.1 零样本边缘检测方法
从FastSAM的所有实例分割阶段的结果中选择掩码概率图。之后,将Sobel滤波[33]应用于所有掩码概率图,以生成边缘图。最后,我们以边缘NMS[6]步骤结束

虽然没有sam那么多细节,但是也基本上相当了
2.4 特点
2.4.1 缺点
- 低质量的小型分割掩模具有大的置信度分数。
因为置信度分数被定义为YOLOv8的bbox分数,它与口罩质量没有强烈的相关性。
修改网络以预测掩码IoU或其他质量指标
- 一些微小物体的掩码往往接近正方形。大型对象的掩码在边界框的边界上可能有一些伪影。
这就是YOLACT方法的弱点。
提高掩模原型的能力或重新制定掩模生成器,该问题有望得到解决。
3.代码
3.1 demo测试

左边是SAM,右边是fast SAM,还是能比较明显的感受到线条的平滑程度上有一定的区别。
3.2回顾一下SAM
SAM将图片,提示都使用嵌入形式送入transformer

SAM流程图
3.3 推理代码

我更愿意将Fast Segment Anything称为是yolo的扩展应用,主要由yolov8-seg分割出实例之后进行后处理。
后处理 = prompt处理 + 绘图等
3.3.1 prompt

文章来源地址https://www.toymoban.com/news/detail-586895.html
box_prompt:bbox和所有实例iou
point_prompt:检查point是否实例内
text_prompt:将实例剪裁后送入clip进行检索文章来源:https://www.toymoban.com/news/detail-586895.html
到了这里,关于【论文笔记】Fast Segment Anything的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[自注意力神经网络]Segment Anything(SAM)论文阅读](https://imgs.yssmx.com/Uploads/2024/02/423006-1.png)