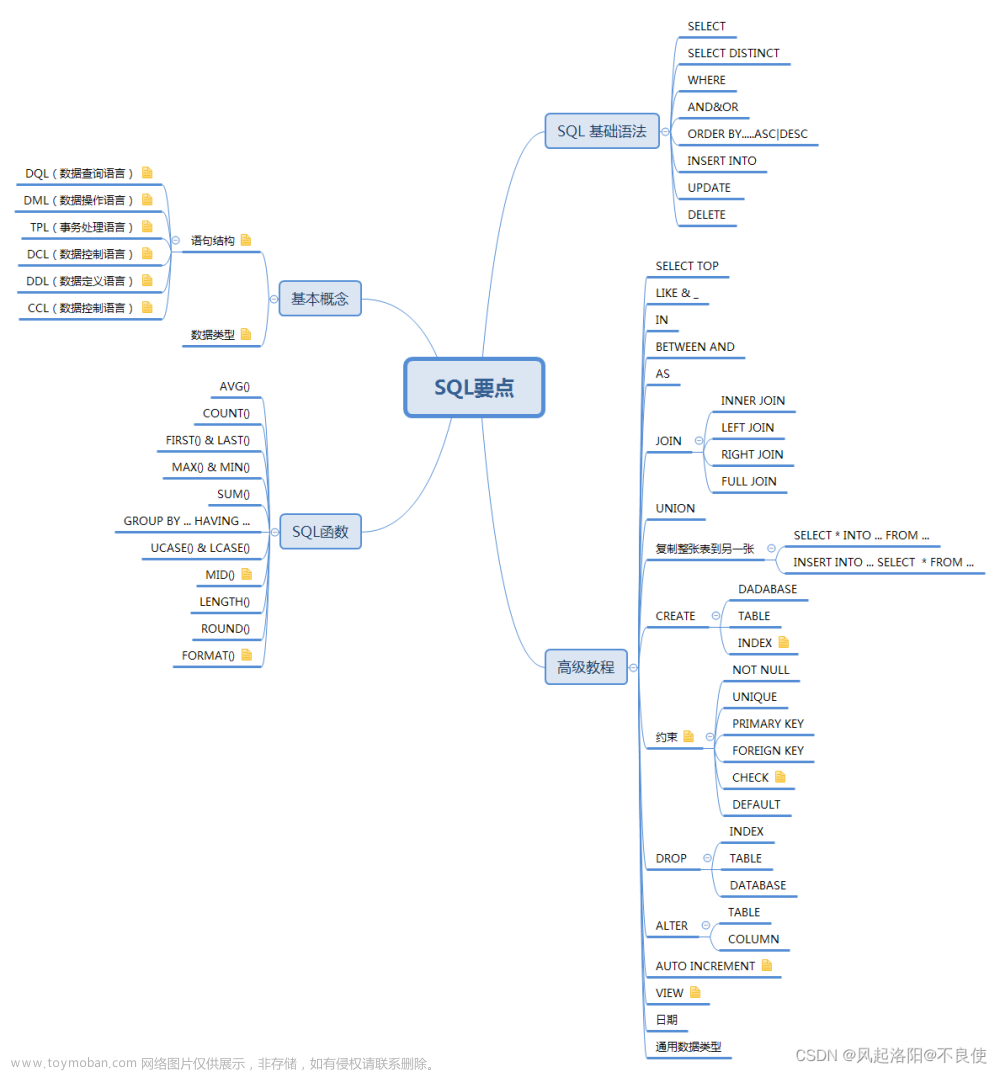
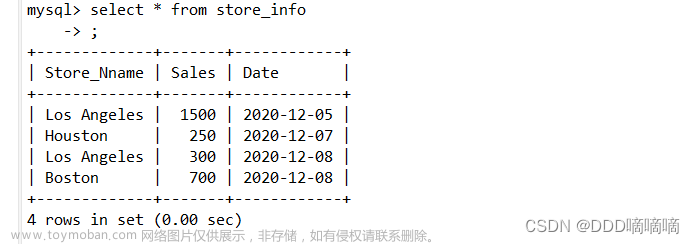
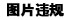查询重复的数据可以使用SQL中的GROUP BY和HAVING子句。以下是一个示例查询,可以检查名为table_name的表中是否有重复的column_name列的值:
SELECT
column_name,
COUNT(*)
FROM
table_name
GROUP BY
column_name
HAVING
COUNT(*) > 1;
该查询将按照column_name列的值进行分组,并计算每个值的出现次数。然后使用HAVING子句过滤出现次数大于1的组,这些组中的行即为重复数据。
请注意,上述查询仅检查一个列的重复数据。如果您想要检查多个列的组合是否重复,请在GROUP BY子句中包含这些列的名称。例如:文章来源:https://www.toymoban.com/news/detail-588917.html
SELECT
column_name1,
column_name2,
COUNT(*)
FROM
table_name
GROUP BY
column_name1,
column_name2
HAVING
COUNT(*) > 1;
该查询将按照column_name1和column_name2列的值进行分组,并计算每个组的出现次数。然后使用HAVING子句过滤出现次数大于1的组,这些组中的行即为重复数据。文章来源地址https://www.toymoban.com/news/detail-588917.html
到了这里,关于【常用SQL】MySQL查询重复的数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!