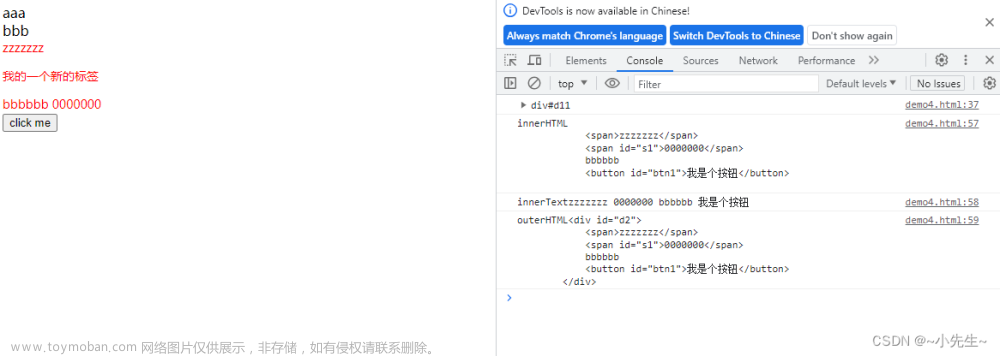
方法1:.text
直接定位元素
直接使用xpath路径定位元素,最后使用.text获取元素中文本
- 注意!!: 此时text_translation取.text 之前 类型为WebElement
from selenium import webdriver
driver = webdriver.Chrome(executable_path='你的chromedriver.exe所在路径')
text_translation = driver.find_element_by_xpath('//span[@class="VIiyi"]/span/span').text
方法2:text()
使用etree.HTML (提前导入模块from lxml import etree)文章来源:https://www.toymoban.com/news/detail-590250.html
etree.HTML先解析当前页面资源,再路径定位元素时,路径最后添加/text()获取文本,取文本列表中第一个元素[0]文章来源地址https://www.toymoban.com/news/detail-590250.html
- 注意!!: 此时text_translation取[0] 之前 类型为list,list输出为[‘hello’]
from selenium import webdriver
from lxml import etree
driver = webdriver.Chrome(executable_path='你的chromedriver.exe所在路径')
source = etree.HTML(driver.page_source)
text_translation = source.xpath('//span[@class="VIiyi"]/span/span/text()')[0]
到了这里,关于selenium获取html元素中的文本内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!