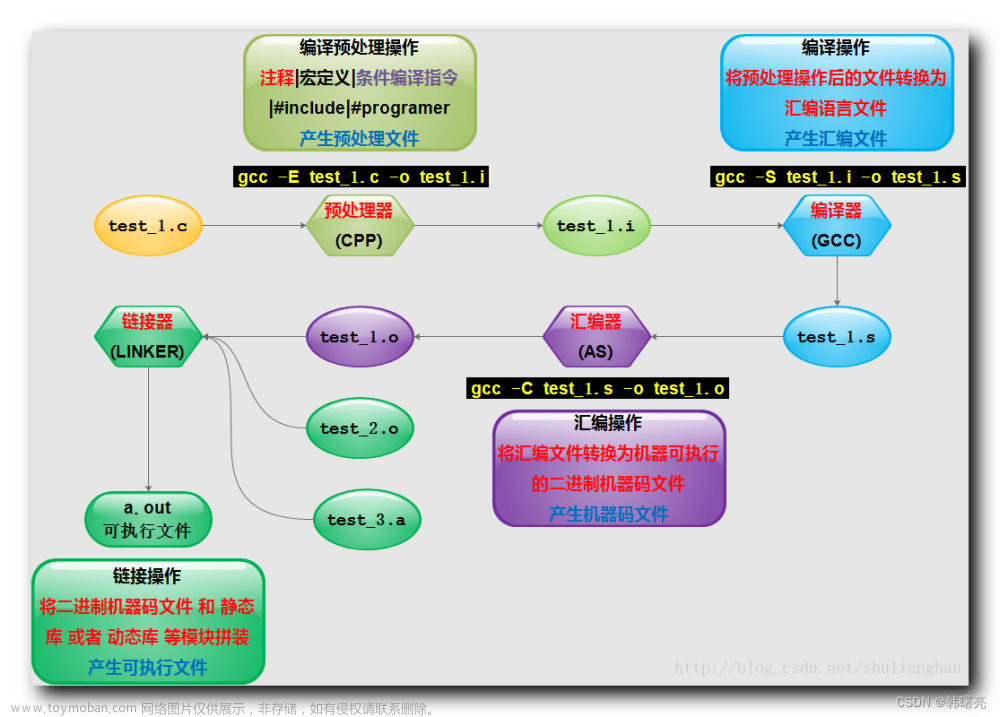
参考博客:IOS开发基础——属性关键字(copy strong weak等)
先来看看常用的属性关键字有哪些:
- 内存管理有关的关键字:
weak,assign,strong,retain,copy - 线程安全有关的的关键字:
nonatomic,atomic - 访问权限有关的的关键字:
readonly,readwrite(只读,可读写) - 修饰变量的关键字:
const,static,extern - 这些都是我们在日常的开发中常用到的一些关键字。关于他们的详细用法以及作用,在下面进行详细的分析讲解。
线程安全的关键字
nonatomic关键字
nonatomic:非原子操作,不加锁,线程执行快,但是多个线程访问同一个属性可能产生crash
atomic关键字
atomic原子操作:加锁,保证setter和getter存取方法的线程安全(仅仅对setter和getter方法加锁)。因为线程加锁,别的线程访问当前属性的时候会先执行完属性当前的操作。
注意:atomic只针对属性的 getter/setter 方法进行加锁,所以安全只是针对getter/setter方法来说,并不是整个线程安全,因为一个属性并不只有 setter/getter 方法,例:(如果一个线程正在getter 或者 setter时,有另外一个线程同时对该属性进行release操作,如果release先完成,会造成crash)
内存管理有关的的关键字:(weak,assign,strong,retain,copy)
关键字weak
同样经常用于修饰OC对象类型的数据,修饰的对象在释放后,指针地址会自动被置为nil,这是一种弱引用。
注意:在ARC环境下,为避免循环引用,往往会把delegate属性用weak修饰;在MRC下使用assign修饰。当一个对象不再有strong类型的指针指向它的时候,它就会被释放,即使还有weak型指针指向它,那么这些weak型指针也将被清除。
关键字assign
经常用于非指针变量,用于基础数据类型 (例如NSInteger)和C数据类型(int, float, double, char, 等),另外还有id类型。用于对基本数据类型进行复制操作,不更改引用计数。也可以用来修饰对象,但是,被assign修饰的对象在释放后,指针的地址还是存在的,也就是说指针并没有被置为nil,成为野指针。
注意:之所以可以修饰基本数据类型,因为基本数据类型一般分配在栈上,栈的内存会由系统自动处理,不会造成野指针
以及:在MRC下常见的id delegate往往是用assign方式的属性而不是retain方式的属性,为了防止delegation两端产生不必要的循环引用。例如:对象A通过retain获取了对象B的所有权,这个对象B的delegate又是A, 如果这个delegate是retain方式的,两个都是强引用,互相持有,那基本上就没有机会释放这两个对象了。
weak 和 assign 的区别:
- 修饰的对象:
weak修饰oc对象类型的数据,assign用来修饰是非指针变量。 - 引用计数:
weak和assign都不会增加引用计数。 - 释放:
weak修饰的对象释放后,指针地址自动设置为 nil,assign修饰的对象释放后指针地址依然存在,成为野指针。 - 修饰
delegate在MRC使用assign,在ARC使用weak。
retain的源码流程:
ALWAYS_INLINE id
objc_object::rootRetain(bool tryRetain, objc_object::RRVariant variant)
{
// 如果是 Tagged Pointer 则直接返回 this (Tagged Pointer 不参与引用计数管理,它的内存在栈区,由系统处理)
if (slowpath(isTaggedPointer())) return (id)this;
// 临时变量,标记 SideTable 是否加锁
bool sideTableLocked = false;
// 临时变量,标记是否需要把引用计数迁移到 SideTable 中
bool transcribeToSideTable = false;
// 记录 objc_object 之前的 isa
isa_t oldisa;
// 记录 objc_object 修改后的 isa
isa_t newisa;
// 似乎是原子性操作,读取 &isa.bits。(&为取地址)
oldisa = LoadExclusive(&isa.bits);
if (variant == RRVariant::FastOrMsgSend) {
// These checks are only meaningful for objc_retain()
// They are here so that we avoid a re-load of the isa.
// 这些检查仅对objc_retain()有意义
// 它们在这里,以便我们避免重新加载isa。
if (slowpath(oldisa.getDecodedClass(false)->hasCustomRR())) {
ClearExclusive(&isa.bits);
if (oldisa.getDecodedClass(false)->canCallSwiftRR()) {
return swiftRetain.load(memory_order_relaxed)((id)this);
}
return ((id(*)(objc_object *, SEL))objc_msgSend)(this, @selector(retain));
}
}
if (slowpath(!oldisa.nonpointer)) {
// a Class is a Class forever, so we can perform this check once
// outside of the CAS loop
if (oldisa.getDecodedClass(false)->isMetaClass()) {
ClearExclusive(&isa.bits);
return (id)this;
}
}
// 循环结束的条件是 slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits))
// StoreExclusive 函数,如果 &isa.bits 与 oldisa.bits 的内存内容相同,则返回 true,并把 newisa.bits 复制到 &isa.bits,
// 否则返回 false,并把 &isa.bits 的内容加载到 oldisa.bits 中。
// 即 do-while 的循环条件是指,&isa.bits 与 oldisa.bits 内容不同,如果它们内容不同,则一直进行循环,
// 循环的最终目的就是把 newisa.bits 复制到 &isa.bits 中。
// return __c11_atomic_compare_exchange_weak((_Atomic(uintptr_t) *)dst,
// &oldvalue, value, __ATOMIC_RELAXED, __ATOMIC_RELAXED)
// _Bool atomic_compare_exchange_weak( volatile A *obj, C* expected, C desired );
// 定义于头文件 <stdatomic.h>
// 原子地比较 obj 所指向对象的内存的内容与 expected 所指向的内存的内容,若它们相等,则以 desired 替换前者(进行读修改写操作)。
// 否则,将 obj 所指向的实际内存内容加载到 *expected (进行加载操作)。
do {
// 默认不需要转移引用计数到 SideTable
transcribeToSideTable = false;
// 赋值给 newisa(第一次进来时 &isa.bits, oldisa.bits, newisa.bits 三者是完全相同的)
newisa = oldisa;
// 如果 newisa 不是优化的 isa (元类的 isa 是原始的 isa (Class cls))
if (slowpath(!newisa.nonpointer)) {
// 在 mac、arm64e 下不执行任何操作,只在 arm64 下执行 __builtin_arm_clrex();
// 在 arm64 平台下,清除对 &isa.bits 的独占访问标记。
ClearExclusive(&isa.bits);
// 如果需要 tryRetain 则调用 sidetable_tryRetain 函数,并根据结果返回 this 或者 nil。
// 执行此行之前是不需要在当前函数对 SideTable 加锁的
// sidetable_tryRetain 返回 false 表示对象已被标记为正在释放,
// 所以此时再执行 retain 操作是没有意义的,所以返回 nil。
if (tryRetain) return sidetable_tryRetain() ? (id)this : nil;
// 如果不需要 tryRetain 则调用 sidetable_retain()
else return sidetable_retain(sideTableLocked);
}
// don't check newisa.fast_rr; we already called any RR overrides
// 不要检查 newisa.fast_rr; 我们已经调用所有 RR 的重载。
// 如果 tryRetain 为真并且 objc_object 被标记为正在释放 (newisa.deallocating),则返回 nil
if (slowpath(newisa.isDeallocating())) {
ClearExclusive(&isa.bits);
// SideTable 处于加锁状态
if (sideTableLocked) {
ASSERT(variant == RRVariant::Full);
// 进行解锁
sidetable_unlock();
}
// 需要 tryRetain
if (slowpath(tryRetain)) {
return nil;
} else {
return (id)this;
}
}
// 下面就是 isa 为 nonpointer,并且没有被标记为正在释放的对象
uintptr_t carry;
// bits extra_rc 自增
// x86_64 平台下:
// # define RC_ONE (1ULL<<56)
// uintptr_t extra_rc : 8
// extra_rc 内容位于 56~64 位
newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry); // extra_rc++
// 如果 carry 为 true,表示要处理引用计数溢出的情况
if (slowpath(carry)) {
// newisa.extra_rc++ overflowed
// 如果 variant 不为 Full,
// 则调用 rootRetain_overflow(tryRetain) 它的作用就是把 variant 传为 Full
// 再次调用 rootRetain 函数,目的就是 extra_rc 发生溢出时,我们一定要处理
if (variant != RRVariant::Full) {
ClearExclusive(&isa.bits);
return rootRetain_overflow(tryRetain);
}
// Leave half of the retain counts inline and
// prepare to copy the other half to the side table.
// 将 retain count 的一半留在 inline,并准备将另一半复制到 SideTable.
if (!tryRetain && !sideTableLocked) sidetable_lock();
// 整个函数只有这里把 sideTableLocked 置为 true
sideTableLocked = true;
// 标记需要把引用计数转移到 SideTable 中
transcribeToSideTable = true;
// x86_64 平台下:
// uintptr_t extra_rc : 8
// # define RC_HALF (1ULL<<7) 二进制表示为: 0b 1000,0000
// extra_rc 总共 8 位,现在把它置为 RC_HALF,表示 extra_rc 溢出
newisa.extra_rc = RC_HALF;
// 把 has_sidetable_rc 标记为 true,表示 extra_rc 已经存不下该对象的引用计数,
// 需要扩张到 SideTable 中
newisa.has_sidetable_rc = true;
}
} while (slowpath(!StoreExclusive(&isa.bits, &oldisa.bits, newisa.bits)));
if (variant == RRVariant::Full) {
if (slowpath(transcribeToSideTable)) {
// Copy the other half of the retain counts to the side table.
// 复制 retain count 的另一半到 SideTable 中。
sidetable_addExtraRC_nolock(RC_HALF);
}
// 如果 tryRetain 为 false 并且 sideTableLocked 为 true,则 SideTable 解锁
if (slowpath(!tryRetain && sideTableLocked)) sidetable_unlock();
} else {
ASSERT(!transcribeToSideTable);
ASSERT(!sideTableLocked);
}
// 返回 this
return (id)this;
}

我们根据图来看一下retain的步骤:
- 第1步:若对象为
TaggedPointer小对象,无需进行内存管理,直接返回; - 第2步:若对象的isa没有经过优化,即
!newisa.nonpointer成立,由于tryRetain=false,直接进入sidetable_retain方法,此方法本质是直接操作散列表,最后让目标对象的引用计数+1; - 第3步:判断对象是否正在释放,若正在正在释放,则执行dealloc流程,释放弱引用表和引用计数表;
- 第4步:若对象的isa经过了优化,则执行
newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry),即isa的位域extra_rc+1,且通过变量carry来判断位域extra_rc是否已满,如果位域extra_rc已满则执行newisa.extra_rc = RC_HALF,即将extra_rc满状态的一半拿出来存到extra_rc位域中,然后将另一半存储到散列表中,执行sidetable_addExtraRC_nolock(RC_HALF)函数;
release的源码流程:
ALWAYS_INLINE bool objc_object::rootRelease(bool performDealloc, bool handleUnderflow)
{
if (isTaggedPointer()) return false;
bool sideTableLocked = false;
isa_t oldisa;
isa_t newisa;
retry:
do {
oldisa = LoadExclusive(&isa.bits);
newisa = oldisa;
if (slowpath(!newisa.nonpointer)) {
// 未优化 isa
ClearExclusive(&isa.bits);
if (sideTableLocked) sidetable_unlock();
// 入参是否要执行 Dealloc 函数,如果为 true 则执行 SEL_dealloc
return sidetable_release(performDealloc);
}
// extra_rc --
newisa.bits = subc(newisa.bits, RC_ONE, 0, &carry); // extra_rc--
if (slowpath(carry)) {
// donot ClearExclusive()
goto underflow;
}
// 更新 isa 值
} while (slowpath(!StoreReleaseExclusive(&isa.bits,
oldisa.bits, newisa.bits)));
if (slowpath(sideTableLocked)) sidetable_unlock();
return false;
underflow:
// 处理下溢,从 side table 中借位或者释放
newisa = oldisa;
// 如果使用了 sidetable_rc
if (slowpath(newisa.has_sidetable_rc)) {
if (!handleUnderflow) {
// 调用本函数处理下溢
ClearExclusive(&isa.bits);
return rootRelease_underflow(performDealloc);
}
// 从 sidetable 中借位引用计数给 extra_rc
size_t borrowed = sidetable_subExtraRC_nolock(RC_HALF);
if (borrowed > 0) {
// extra_rc 是计算额外的引用计数,0 即表示被引用一次
newisa.extra_rc = borrowed - 1; // redo the original decrement too
bool stored = StoreReleaseExclusive(&isa.bits,
oldisa.bits, newisa.bits);
// 保存失败,恢复现场,重试
if (!stored) {
isa_t oldisa2 = LoadExclusive(&isa.bits);
isa_t newisa2 = oldisa2;
if (newisa2.nonpointer) {
uintptr_t overflow;
newisa2.bits =
addc(newisa2.bits, RC_ONE * (borrowed-1), 0, &overflow);
if (!overflow) {
stored = StoreReleaseExclusive(&isa.bits, oldisa2.bits,
newisa2.bits);
}
}
}
// 如果还是保存失败,则还回 side table
if (!stored) {
sidetable_addExtraRC_nolock(borrowed);
goto retry;
}
sidetable_unlock();
return false;
}
else {
// Side table is empty after all. Fall-through to the dealloc path.
}
}
// 没有使用 sidetable_rc ,或者 sidetable_rc 计数 == 0 的就直接释放
// 如果已经是释放中,抛个过度释放错误
if (slowpath(newisa.deallocating)) {
ClearExclusive(&isa.bits);
if (sideTableLocked) sidetable_unlock();
return overrelease_error();
// does not actually return
}
// 更新 isa 状态
newisa.deallocating = true;
if (!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)) goto retry;
if (slowpath(sideTableLocked)) sidetable_unlock();
// 执行 SEL_dealloc 事件
__sync_synchronize();
if (performDealloc) {
((void(*)(objc_object *, SEL))objc_msgSend)(this, SEL_dealloc);
}
return true;
}

- 第1步:若对象为
TaggedPointer小对象,不需要做内存管理操作,直接返回; - 第2步:若对象的
isa没有经过优化,即!newisa.nonpointer成立,直接进入sidetable_release方法,此方法本质是直接操作散列表,最后让目标对象的引用计数-1; - 第3步:判断是引用计数是否为0,如果是0则执行
dealloc流程 - 第4步:若对象的isa经过优化,则执行
newisa.bits = subc(newisa.bits, RC_ONE, 0, &),即对象的isa位域extra_rc-1;且通过变量carry标识对象的isa的extra_rc是否为0, 如果对象的isa的extra_rc=0,则去访问散列表,判断对象在散列表中是否存在引用计数; - 第5步:如果sidetable的引用计数为0,对象进行dealloc流程
关键字strong:
用于修饰一些OC对象类型的数据如:(NSNumber,NSString,NSArray、NSDate、NSDictionary、模型类等),它被一个强指针引用着,是一个强引用。在ARC的环境下等同于retain,这一点区别于weak。它是一我们通常所说的指针拷贝(浅拷贝),内存地址保持不变,只是生成了一个新的指针,新指针和引用对象的指针指向同一个内存地址,没有生成新的对象,只是多了一个指向该对象的指针。
注意:由于使用的是一个内存地址,当该内存地址存储的内容发生变更的时候,会导致属性也跟着变更:
__strong
表示引用为强引用。在ARC模式下,只要一个变量有__strong标识了,就标识拥有了赋值的对象,不管赋值的对象是怎么来的。也可理解为只要见到__strong标识,编译器就会给那些不是你持有的对象自动加上retain,并且在变量超出作用域后自动调用了一次release。
void objc_storeStrong(id *location, id obj)
{
id prev = *location;
if (obj == prev) {
return;
}
objc_retain(obj);
*location = obj;
objc_release(prev);
}
关键字copy:
同样用于修饰OC对象类型的数据,同时在MRC手动内存管理时期,用来修饰block,因为block需要从栈区copy到堆区,在现在的ARC时代,系统自动给我们做了这个操作,所一现在使用strong或者copy来修饰block都是可以的。copy和strong相同点在于都是属于强引用,都会是属性的计数加一,但是copy和strong不同点在于,它所修饰的属性当引用一个属性值时,是内存拷贝(深拷贝),就是在引用是,会生成一个新的内存地址和指针地址来,和引用对象完全没有相同点,因此它不会因为引用属性的变更而改变。
copy与strong的区别(深拷贝 浅拷贝):
- 浅拷贝:指针拷贝,内存地址不变呢,指针地址不相同。
- 深拷贝:内存拷贝,内存地址不同,指针地址也不相同。
声明两个copy属性,两个strong属性,分别为可变和不可变类型:
@property(nonatomic,strong)NSString * Strstrong;
@property(nonatomic,copy)NSString * Strcopy;
@property(nonatomic,copy)NSMutableString * MutableStrcopy;
@property(nonatomic,strong)NSMutableString * MutableStrstrong;
对属性进行赋值,并打印结果:
NSString * OriginalStr = @"我已经开始测试了";
//对 不可变对象赋值 无论是 strong 还是 copy 都是原地址不变,内存地址都为(0x10c6d75c0),生成一个新指针指向对象(浅拷贝)
self.Strcopy = OriginalStr;
self.Strstrong = OriginalStr;
self.MutableStrcopy = OriginalStr;
self.MutableStrstrong = OriginalStr;
NSLog(@"\n 内容值: rangle=>%@\n normal:copy=>%@=====strong=>%@\n Mutable:copy=>%@=====strong=>%@",OriginalStr,_Strcopy,_Strstrong,_MutableStrcopy,_MutableStrstrong);
NSLog(@"\n 内存地址:rangle=>%p\n normal:copy=>%p=====strong=>%p\n Mutable:copy=>%p=====strong=>%p",OriginalStr,_Strcopy,_Strstrong,_MutableStrcopy,_MutableStrstrong);
NSLog(@"\n 指针地址:rangle=>%p\n normal:copy=>%p=====strong=>%p\n Mutable:copy=>%p=====strong=>%p",&OriginalStr,&_Strcopy,&_Strstrong,&_MutableStrcopy,&_MutableStrstrong);

由上面可以看出,strong修饰的对象,在引用一个对象的时候,内存地址都是一样的,只有指针地址不同,copy修饰的对象也是如此。为什么呢?不是说copy修饰的对象是生成一个新的内存地址嘛?这里为什么内存地址还是原来的呢?
因为,对不可变对象赋值,无论是strong还是copy,都是一样的,原内存地址不变,生成了新的指针地址。
然后我们试试用 可变对象 对属性进行赋值:
NSMutableString * OriginalMutableStr = [NSMutableString stringWithFormat:@"我已经开始测试了"];
self.Strcopy = OriginalMutableStr;
self.Strstrong = OriginalMutableStr;
self.MutableStrcopy = OriginalMutableStr;
self.MutableStrstrong = OriginalMutableStr;

在上面的结果可以看出,strong修饰的属性内存地址依然没有改变,但是copy修饰的属性内存值产生了变化。由此得出结论:
对可变对象赋值 strong 是原地址不变,引用计数+1(浅拷贝)。 copy是生成一个新的地址和对象,生成一个新指针指向新的内存地址(深拷贝)
我们来测试一下此时修改一下OriginalMutableStr的值,看看结果:
[OriginalStr appendFormat:@"改变了"];
输出结果:
看到 strong 修饰的属性,跟着进行了改变
当改变了原有值的时候,由于OriginalStr是可变类型,是在原有内存地址上进行修改,无论是指针地址和内存地址都没有改变,只是当前内存地址所存放的数据进行改变。由于 strong 修饰的属性虽然指针地址不同,但是指针是指向原内存地址的,所以会跟着 OriginalStr 的改变而改变。
不同于strong,copy修饰的类型不仅指针地址不同,而且指向的内存地址也和OriginalStr 不一样,所以不会跟着 OriginalStr 的改变而改变。
注意:
- 使用self.Strcopy 和 _Strcopy 来赋值也是两个不一样的结果,因为后者没有调用 set 方法,而 copy 和 strong 之所以会产生差别就是因为在 set 方法中,copy修饰的属性:调用了 _Strcopy = [Strcopy copy] 方法。
- copy也分为 copy 和 mutableCopy,在对容器对象和非容器对象操作的时候也是有区别,下面来分析下:
多种copy模式:copy 和 mutableCopy 对 容器对象 进行操作
在对容器对象(NSArray)进行copy操作时,分为多种:
- copy:仅仅进行了指针拷贝
- mutableCopy:进行内容拷贝这里的单层指的是完成了NSArray对象的深copy,而未对其容器内对象进行处理使用(NSArray对象的内存地址不同,但是内部元素的内存地址不变)
[arr mutableCopy];
- 双层深拷贝:这里的双层指的是完成了NSArray对象和NSArray容器内对象的深copy(为什么不是完全,是因为无法处理NSArray中还有一个NSArray这种情况)使用:
[[NSArray alloc] initWithArray:arr copyItems:YES];
- 完全深拷贝:完美的解决NSArray嵌套NSArray这种情形,可以使用归档、解档的方式可以使用:
[NSKeyedUnarchiver unarchiveObjectWithData:[NSKeyedArchiver archivedDataWithRootObject:testArr]];
线程安全有关的的关键字:(nonatomic,atomic)
- 关键字nonatomic
nonatomic非原子操作:(不加锁,线程执行快,但是多个线程访问同一个属性时,结果无法预料) - 关键字atomic
atomic原子操作:加锁,保证 getter 和 setter 存取方法的线程安全(仅对setter和getter方法加锁)。
因为线程枷锁的原因,在别的线程来读写这个属性之前,会先执行完当前的操作。
例如:
线程A调用了某一属性的setter方法,在方法还未完成的情况下,线程B调用了该属性的getter方法,那么只有在执行完A线程的setter方法以后才执行B线程的getter操作。当几个线程同时调用同一属性的 setter 和 getter方法时,会得到一个合法的值,但是get的值不可控(因为线程执行的顺序不确定)。
注意:
atomic只针对属性的 getter/setter 方法进行加锁,所以安全只是针对getter/setter方法来说,并不是整个线程安全,因为一个属性并不只有 setter/getter 方法,例:(如果一个线程正在getter 或者 setter时,有另外一个线程同时对该属性进行release操作,如果release先完成,会造成crash)
在这里我们用一个之前学Tagged Pointer对象时的例子:
//@property (nonatomic, strong) NSString *name;
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
for (int i = 0; i < 1000; i++) {
dispatch_async(queue, ^{
self.name = [NSString stringWithFormat:@"addasdsaadss"];
});
}
结果会造成程序崩溃:
我们将属性的关键字改一下看看
//@property (atomic, strong) NSString *name;
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
for (int i = 0; i < 1000; i++) {
dispatch_async(queue, ^{
self.name = [NSString stringWithFormat:@"addasdsaadss"];
});
}
程序就可以正常运行,相当于atomic加了一个锁。
修饰变量的关键字:(const,static,extern)
常量const
常量修饰符,表示不可变,可以用来修饰右边的基本变量和指针变量(放在谁的前面修饰谁(基本数据变量p,指针变量p))。
常用写法例如:
const 类型 * 变量名a:可以改变指针的指向,不能改变指针指向的内容。 const放 号的前面约束参数,表示a只读。只能修改地址a,不能通过a修改访问的内存空间
int x = 12;
int new_x = 21;
const int *px = &x;
px = &new_x; // 改变指针px的指向,使其指向变量y
类型 * const 变量名:可以改变指针指向的内容,不能改变指针的指向。 const放后面约束参数,表示a只读,不能修改a的地址,只能修改a访问的值,不能修改参数的地址
int y = 12;
int new_y = 21;
int * const py = &y;
(*py) = new_y; // 改变px指向的变量x的值
常量(const)和宏定义(define)的区别:
使用宏和常量所占用的内存差别不大,宏定义的是常量,常量都放在常量区,只会生成一份内存
缺点:
- 编译时刻:宏是预编译(编译之前处理),const是编译阶段。导致使用宏定义过多的话,随着工程越来越大,编译速度会越来越慢
- 宏不做检查,不会报编译错误,只是替换,const会编译检查,会报编译错误。
优点:
- 宏能定义一些函数,方法。 const不能。
常量 static
static关键字的三个作用:
- 可以修饰局部变量,将局部变量存储到静态存储区。
- 可以修饰全局变量,限定全局变量只能在当前源文件中访问。
- 可以修饰函数,限定该函数只能在当前源文件调用。
常量 extern
只是用来获取全局变量(包括全局静态变量)的值,不能用于定义变量。先在当前文件查找有没有全局变量,没有找到,才会去其他文件查找(优先级)。
static与const联合使用
声明一个静态的全局只读常量。开发中声明的全局变量,有些不希望外界改动,只允许读取。
iOS中staic和const常用使用场景,是用来代替宏,把一个经常使用的字符串常量,定义成静态全局只读变量.
// 开发中经常拿到key修改值,因此用const修饰key,表示key只读,不允许修改。
static NSString * const key = @"name";
// 如果 const修饰 *key1,表示*key1只读,key1还是能改变。
static NSString const *key1 = @"name";
__autoreleasing关键字
提到这,就不得不再说一说autoreleasing了:
int main(int argc, const char * argv[]) {
@autoreleasepool {
__autoreleasing id obj = [[NSObject alloc] init];
}
return 0;
}
打开汇编看看:
@autoreleasepool{}关键字通过编译器转换成objc_autoreleasePoolPush和objc_autoreleasePoolPop这一对方法。__autoreleasing 修饰符转换成objc_autorelease,将obj加入自动释放池中。
编译器对自动释放池的处理逻辑大致分成:
- 由
objc_autoreleasePoolPush作为自动释放池作用域的第一个函数。 - 使用
objc_autorelease将对象加入自动释放池。 - 由
objc_autoreleasePoolPop作为自动释放池作用域的最后一个函数。
接下来看一下objc_autoreleasePoolPush 和 objc_autoreleasePoolPop 的实现:
void *objc_autoreleasePoolPush(void) {
// 调用了AutoreleasePoolPage中的push方法
return AutoreleasePoolPage::push();
}
void objc_autoreleasePoolPop(void *ctxt) {
// 调用了AutoreleasePoolPage中的pop方法
AutoreleasePoolPage::pop(ctxt);
}
下面分析一下AutoreleasePoolPage的实现
AutoreleasePoolPage
class AutoreleasePoolPage {
# define EMPTY_POOL_PLACEHOLDER ((id*)1)
// 哨兵对象
# define POOL_BOUNDARY nil
static pthread_key_t const key = AUTORELEASE_POOL_KEY;
static uint8_t const SCRIBBLE = 0xA3; // 0xA3A3A3A3 after releasing
// AutoreleasePoolPage的大小,通过宏定义,可以看到是4096字节
static size_t const SIZE =
#if PROTECT_AUTORELEASEPOOL
PAGE_MAX_SIZE; // must be multiple of vm page size
#else
PAGE_MAX_SIZE; // size and alignment, power of 2
//4096
#endif
static size_t const COUNT = SIZE / sizeof(id);
// 对当前AutoreleasePoolPage 完整性的校验,就是用来判断对象是否完成初始化的一个标志
magic_t const magic;
// 指向下一个即将产生的autoreleased对象的存放位置(当next == begin()时,表示AutoreleasePoolPage为空;当next == end()时,表示AutoreleasePoolPage已满
id *next;
// 当前线程,表明与线程有对应关系
pthread_t const thread;
// 指向父节点,第一个节点的 parent 值为 nil;
AutoreleasePoolPage * const parent;
// 指向子节点,最后一个节点的 child 值为 nil;
AutoreleasePoolPage *child;
// 代表深度,第一个page的depth为0,往后每递增一个page,depth会加1;
uint32_t const depth;
// 表示high water mark(最高水位标记)
uint32_t hiwat;
};
大致流程
- 当进入
@autoreleasepool作用域时,objc_autoreleasePoolPush方法被调用,runtime会向当前的AutoreleasePoolPage中添加一个nil对象作为哨兵对象,并返回该哨兵对象的地址; - 对象调用
autorelease方法,会被加入到对应的的AutoreleasePoolPage中去,next指针类似一个游标,不断变化,记录位置。如果加入的对象超出一页的大小,便会自动加一个新页。 - 当离开
@autoreleasepool作用域时,objc_autoreleasePoolPop(哨兵对象地址)方法被调用,其会从当前page的next指标的上一个元素开始查找, 直到最近一个哨兵对象, 依次向这个范围中的对象发送release消息
因为哨兵对象的存在,自动释放池的嵌套也是满足的,不管是嵌套还是被嵌套的自动释放池,找自己对应的哨兵对象就行了
源码流程分析
push 函数
// 哨兵对象定义
#define POOL_BOUNDARY nil
static inline void *push()
{
id *dest;
if (slowpath(DebugPoolAllocation)) {
// Each autorelease pool starts on a new pool page.
dest = autoreleaseNewPage(POOL_BOUNDARY);
} else {
// 添加一个哨兵对象到自动释放池
dest = autoreleaseFast(POOL_BOUNDARY);
}
...
return dest;
}
//向自动释放池中添加对象
static inline id *autoreleaseFast(id obj)
{
// 获取hotPage: 当前正在使用的Page
AutoreleasePoolPage *page = hotPage();
// 如果有page 并且 page没有被占满
if (page && !page->full()) {
// 添加一个对象
return page->add(obj);
} else if (page) {
// 添加一个对象
return autoreleaseFullPage(obj, page);
} else {
// 如果没有page,则创建一个page
return autoreleaseNoPage(obj);
}
}
// 创建一个新的page,并将当前page->child指向新的page,将对象添加进去
id *autoreleaseFullPage(id obj, AutoreleasePoolPage *page)
{
...
do {
if (page->child) page = page->child;
else page = new AutoreleasePoolPage(page);
} while (page->full());
setHotPage(page);
return page->add(obj);
}
// 创建一个新的page
id *autoreleaseNoPage(id obj)
{
...
AutoreleasePoolPage *page = new AutoreleasePoolPage(nil);
setHotPage(page);
...
// Push the requested object or pool.
return page->add(obj);
}
//压栈的函数(省略了不必要的部分)
//压栈操作,将对象加入AutoreleasePoolPage,然后移动栈顶指针
id *add(id obj) {
id *ret = next;
*next++ = obj;
return ret;
}
pop函数
static inline void pop(void *token) // token指针指向栈顶的地址
{
//使用pageForPointer获取当前token所在的AutoreleasePoolPage
AutoreleasePoolPage *page;
id *stop;
page = pageForPointer(token); // 通过栈顶的地址找到对应的page
stop = (id *)token;
if (DebugPoolAllocation && *stop != POOL_SENTINEL) {
// This check is not valid with DebugPoolAllocation off
// after an autorelease with a pool page but no pool in place.
_objc_fatal("invalid or prematurely-freed autorelease pool %p; ",
token);
}
if (PrintPoolHiwat) printHiwat(); // 记录最高水位标记
//调用releaseUntil方法释放栈中的对象、直到stop,stop就是传递的参数,一般为哨兵对象
page->releaseUntil(stop); // 从栈顶开始操作出栈,并向栈中的对象发送release消息,直到遇到第一个哨兵对象
// memory: delete empty children
// 删除空掉的节点
if (DebugPoolAllocation && page->empty()) {
// special case: delete everything during page-per-pool debugging
AutoreleasePoolPage *parent = page->parent;
page->kill();
setHotPage(parent);
} else if (DebugMissingPools && page->empty() && !page->parent) {
// special case: delete everything for pop(top)
// when debugging missing autorelease pools
page->kill();
setHotPage(nil);
}
//调用child的kill方法,releaseUntil把page里的对象进行了释放,但是page本身也会占据很多空间,要通过kill()来处理
//如果当前page小于一半满,则把当前页的所有孩子都杀掉,否则,留下一个孩子,从孙子开始杀。
else if (page->child) {
// hysteresis: keep one empty child if page is more than half full
if (page->lessThanHalfFull()) {
page->child->kill();
}
else if (page->child->child) {
page->child->child->kill();
}
}
}
将上方代码简化之后如下:
static inline void pop(void *token) {
//使用pageForPointer获取当前token所在的AutoreleasePoolPage
AutoreleasePoolPage *page = pageForPointer(token);
id *stop = (id *)token;
//调用releaseUntil方法释放栈中的对象、直到stop,stop就是传递的参数,一般为哨兵对象
page->releaseUntil(stop);
//调用child的kill方法,releaseUntil把page里的对象进行了释放,但是page本身也会占据很多空间,要通过kill()来处理
//如果当前page小于一半满,则把当前页的所有孩子都杀掉,否则,留下一个孩子,从孙子开始杀。
if (page->child) {
if (page->lessThanHalfFull()) {
page->child->kill();
} else if (page->child->child) {
page->child->child->kill();
}
}
}
该流程分为两步:
- page->releaseUntil(stop),对栈顶(page->next)到stop地址(POOL_SENTINEL)之间的所有对象调用objc_release(),进行引用计数减1
- 清空page对象page->kill()
weak基本原理
weak基础
weak是弱引用,所引用对象的计数器不会加一,并在引用对象被释放的时候自动被设置为nil。
weak表其实是一个hash(哈希)表 (字典也是hash表),Key是所指对象的地址,Value是weak指针的地址集合。 它用于解决循环引用问题。
Runtime维护了一个weak表,用于存储指向某个对象的所有weak指针。weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址(这个地址的值是所指对象指针的地址,就是地址的地址)集合(当weak指针的数量小于等于4时,是数组, 超过时,会变成hash表)。
weak 的实现原理可以概括以下三步:
- 初始化时:runtime会调用objc_initWeak函数,初始化一个新的weak指针指向对象的地址。
- 添加引用时:objc_initWeak函数会调用 objc_storeWeak() 函数, objc_storeWeak() 的作用是更新指针指向,创建对应的弱引用表。
- 释放时,调用clearDeallocating函数。clearDeallocating函数首先根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,清理对象的记录。
SideTable
struct SideTable {
// 保证原子操作的自旋锁
spinlock_t slock;
// 引用计数的 hash 表
RefcountMap refcnts;
// weak 引用全局 hash 表
weak_table_t weak_table;
SideTable() {
memset(&weak_table, 0, sizeof(weak_table));
}
~SideTable() {
_objc_fatal("Do not delete SideTable.");
}
void lock() { slock.lock(); }
void unlock() { slock.unlock(); }
void reset() { slock.reset(); }
// Address-ordered lock discipline for a pair of side tables.
template<HaveOld, HaveNew>
static void lockTwo(SideTable *lock1, SideTable *lock2);
template<HaveOld, HaveNew>
static void unlockTwo(SideTable *lock1, SideTable *lock2);
}
slock是为了防止竞争选择的自旋锁
refcnts 是协助对象的 isa 指针的 extra_rc 共同引用计数的变量(对于对象结果,在后文提到)
接着我们来看一下SideTable中的这三个成员变量:
1.spinlock_t slock 自旋锁
锁是线程同步时的一个重要工具
操作系统中有五大锁(操作系统还没有学到这地方,先写着基础概念,后续会有博客详细介绍):
- 信号量:
整型信号量S,S<=0表示该资源已被占用,S>0表示该资源可用,pv操作进行访问
记录型信号量 s.value > 0 表示该资源可用的数目;< 0表示在等待链表中已经阻塞的数目
AND型信号量,AND型信号量是指同时需要多个资源且每种占用一个资源时的信号量操作。
信号量集 对应有多种资源,相当于记录型的集合 - 互斥量:和二元信号量类似,唯一不同的是,互斥量的获取和释放必须是在同一个线程中进行的。如果一个线程去释放一个不是其所占有的信号量是无效的。而信号量是可以由其他线程释放的。
- 临界区:并发执行的进程中,访问临界资源的必须互斥执行的程序段叫临界区
- 读写锁:解决读者写者问题产生的锁
- 条件变量:条件变量相当于一种通知机制。多个线程可以设置等待该条件变量,而一旦另外的线程设置了该条件变量(相当于唤醒条件变量)后,多个等待的线程就可以继续执行了
自旋锁
说到自旋锁就要谈到互斥锁:
- 相同点:都能保证同一时间只有一个线程访问共享资源。都能保证线程安全。
- 不同点:
- 互斥锁:如果共享数据已经有其他线程加锁了,线程会进入休眠状态等待锁。一旦被访问的资源被解锁,则等待资源的线程会被唤醒。
- 自旋锁:如果共享数据已经有其他线程加锁了,线程会以死循环的方式等待锁,一旦被访问的资源被解锁,则等待资源的线程会立即执行。
自旋锁的效率高于互斥锁。但是我们要注意由于自旋时不释放CPU,因而持有自旋锁的线程应该尽快释放自旋锁,否则等待该自旋锁的线程会一直在哪里自旋,这就会浪费CPU时间。
在操作引用计数的时候对SideTable加锁,避免数据错误
关于锁的知识可以看看之前写的博客:
【iOS】—— iOS中的相关锁
2.RefcountMap

typedef objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap;
其中DenseMap 又是一个模板类:
template<typename KeyT, typename ValueT,
bool ZeroValuesArePurgeable = false,
typename KeyInfoT = DenseMapInfo<KeyT> >
class DenseMap : public DenseMapBase<DenseMap<KeyT, ValueT,
ZeroValuesArePurgeable, KeyInfoT>, KeyT, ValueT, KeyInfoT,
ZeroValuesArePurgeable> {
...
BucketT *Buckets;
unsigned NumEntries;
unsigned NumTombstones;
unsigned NumBuckets;
...
}
比较重要的成员有这几个:
1.ZeroValuesArePurgeable 默认值是 false, 但 RefcountMap 指定其初始化为 true. 这个成员标记是否可以使用值为 0 (引用计数为 1) 的桶. 因为空桶存的初始值就是 0, 所以值为 0 的桶和空桶没什么区别. 如果允许使用值为 0 的桶, 查找桶时如果没有找到对象对应的桶, 也没有找到墓碑桶, 就会优先使用值为 0 的桶.
2.Buckets 指针管理一段连续内存空间, 也就是数组, 数组成员是 BucketT 类型的对象, 我们这里将 BucketT 对象称为桶(实际上这个数组才应该叫桶, 苹果把数组中的元素称为桶应该是为了形象一些, 而不是哈希桶中的桶的意思). 桶数组在申请空间后, 会进行初始化, 在所有位置上都放上空桶(桶的 key 为 EmptyKey 时是空桶), 之后对引用计数的操作, 都要依赖于桶.
桶的数据类型实际上是 std::pair, 类似于 swift 中的元祖类型, 就是将对象地址和对象的引用计数(这里的引用计数类似于isa, 也是使用其中的几个 bit 来保存引用计数, 留出几个 bit 来做其它标记位)组合成一个数据类型.
BucketT 的定义如下:
typedef std::pair<KeyT, ValueT> BucketT;
3.NumEntries 记录数组中已使用的非空的桶的个数.
4.NumTombstones, Tombstone 直译为墓碑, 当一个对象的引用计数为0, 要从桶中取出时, 其所处的位置会被标记为 Tombstone. NumTombstones 就是数组中的墓碑的个数. 后面会介绍到墓碑的作用.
5.NumBuckets 桶的数量, 因为数组中始终都充满桶, 所以可以理解为数组大小.
inline uint64_t NextPowerOf2(uint64_t A) {
A |= (A >> 1);
A |= (A >> 2);
A |= (A >> 4);
A |= (A >> 8);
A |= (A >> 16);
A |= (A >> 32);
return A + 1;
}
这是对应 64 位的提供数组大小的方法, 需要为桶数组开辟空间时, 会由这个方法来决定数组大小. 这个算法可以做到把最高位的 1 覆盖到所有低位. 例如 A = 0b10000, (A >> 1) = 0b01000, 按位与就会得到 A = 0b11000, 这个时候 (A >> 2) = 0b00110, 按位与就会得到 A = 0b11110. 以此类推 A 的最高位的 1, 会一直覆盖到高 2 位、高 4 位、高 8 位, 直到最低位. 最后这个充满 1 的二进制数会再加 1, 得到一个 0b1000…(N 个 0). 也就是说, 桶数组的大小会是 2^n.
RefcountMap 的工作逻辑(代码分析在最后)
1.通过计算对象地址的哈希值, 来从 SideTables 中获取对应的 SideTable. 哈希值重复的对象的引用计数存储在同一个 SideTable 里.
2.SideTable 使用 find() 方法和重载 [] 运算符的方式, 通过对象地址来确定对象对应的桶. 最终执行到的查找算法是 LookupBucketFor().
3.查找算法会先对桶的个数进行判断, 如果桶数为 0 则 return false 回上一级调用插入方法. 如果查找算法找到空桶或者墓碑桶, 同样 return false 回上一级调用插入算法, 不过会先记录下找到的桶. 如果找到了对象对应的桶, 只需要对其引用计数 + 1 或者 - 1. 如果引用计数为 0 需要销毁对象, 就将这个桶中的 key 设置为 TombstoneKey
value_type& FindAndConstruct(const KeyT &Key) {
BucketT *TheBucket;
if (LookupBucketFor(Key, TheBucket))
return *TheBucket;
return *InsertIntoBucket(Key, ValueT(), TheBucket);
}
4.插入算法会先查看可用量, 如果哈希表的可用量(墓碑桶+空桶的数量)小于 1/4, 则需要为表重新开辟更大的空间, 如果表中的空桶位置少于 1/8 (说明墓碑桶过多), 则需要清理表中的墓碑. 以上两种情况下哈希查找算法会很难查找正确位置, 甚至可能会产生死循环, 所以要先处理表, 处理表之后还会重新分配所有桶的位置, 之后重新查找当前对象的可用位置并插入. 如果没有发生以上两种情况, 就直接把新的对象的引用计数放入调用者提供的桶里.
图解:
墓碑的作用:
- 如果 c 对象销毁后将下标 2 的桶设置为空桶而不置为墓碑桶的话, 此时为 e 对象增加引用计数, 根据哈希算法查找到下标为 2 的桶时, 就会直接插入, 无法为已经在下标为 4 的桶中的 e 增加引用计数,但是我们正常的流程中c 对象销毁后下标 2的桶将会被置为墓碑桶,这样的话,在对e对象增加引用计数的时候,根据哈希算法找到下标为2的桶时,就会将2跳过,往后继续查找,直至找到e对象所对应的桶为止,或者直至找到空桶新建一个存e对象的桶
- 如果此时初始化了一个新的对象 f, 根据哈希算法查找到下标为 2 的桶时发现桶中放置了墓碑, 此时会记录下来下标 2. 接下来继续哈希算法查找位置, 查找到空桶时, 就证明表中没有对象 f, 此时 f 使用记录好的下标 2 的墓碑桶而不是查找到的空桶, 就可以利用到已经释放的位置,保证哈希表中前面部分都是被利用或者待利用的状态。
查找某对象对应桶的源码如下:
bool LookupBucketFor(const LookupKeyT &Val,
const BucketT *&FoundBucket) const {
...
if (NumBuckets == 0) { //桶数是0
FoundBucket = 0;
return false; //返回 false 回上层调用添加函数
}
...
unsigned BucketNo = getHashValue(Val) & (NumBuckets-1); //将哈希值与数组最大下标按位与
unsigned ProbeAmt = 1; //哈希值重复的对象需要靠它来重新寻找位置
while (1) {
const BucketT *ThisBucket = BucketsPtr + BucketNo; //头指针 + 下标, 类似于数组取值
//找到的桶中的 key 和对象地址相等, 则是找到
if (KeyInfoT::isEqual(Val, ThisBucket->first)) {
FoundBucket = ThisBucket;
return true;
}
//找到的桶中的 key 是空桶占位符, 则表示可插入
if (KeyInfoT::isEqual(ThisBucket->first, EmptyKey)) {
if (FoundTombstone) ThisBucket = FoundTombstone; //如果曾遇到墓碑, 则使用墓碑的位置
FoundBucket = FoundTombstone ? FoundTombstone : ThisBucket;
return false; //找到空占位符, 则表明表中没有已经插入了该对象的桶
}
//如果找到了墓碑
if (KeyInfoT::isEqual(ThisBucket->first, TombstoneKey) && !FoundTombstone)
FoundTombstone = ThisBucket; // 记录下墓碑
//这里涉及到最初定义 typedef objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap, 传入的第三个参数 true
//这个参数代表是否可以清除 0 值, 也就是说这个参数为 true 并且没有墓碑的时候, 会记录下找到的 value 为 0 的桶
if (ZeroValuesArePurgeable &&
ThisBucket->second == 0 && !FoundTombstone)
FoundTombstone = ThisBucket;
//用于计数的 ProbeAmt 如果大于了数组容量, 就会抛出异常
if (ProbeAmt > NumBuckets) {
_objc_fatal("...");
}
BucketNo += ProbeAmt++; //本次哈希计算得出的下表不符合, 则利用 ProbeAmt 寻找下一个下标
BucketNo&= (NumBuckets-1); //得到新的数字和数组下标最大值按位与
}
}
向某对象的引用计数桶插入代码如下
BucketT *InsertIntoBucketImpl(const KeyT &Key, BucketT *TheBucket) {
unsigned NewNumEntries = getNumEntries() + 1; //桶的使用量 +1
unsigned NumBuckets = getNumBuckets(); //桶的总数
if (NewNumEntries*4 >= NumBuckets*3) { //使用量超过 3/4
this->grow(NumBuckets * 2); //数组大小 * 2做参数, grow 中会决定具体数值
//grow 中会重新布置所有桶的位置, 所以将要插入的对象也要重新确定位置
LookupBucketFor(Key, TheBucket);
NumBuckets = getNumBuckets(); //获取最新的数组大小
}
//如果空桶数量少于 1/8, 哈希查找会很难定位到空桶的位置
if (NumBuckets-(NewNumEntries+getNumTombstones()) <= NumBuckets/8) {
//grow 以原大小重新开辟空间, 重新安排桶的位置并能清除墓碑
this->grow(NumBuckets);
LookupBucketFor(Key, TheBucket); //重新布局后将要插入的对象也要重新确定位置
}
assert(TheBucket);
//找到的 BucketT 标记了 EmptyKey, 可以直接使用
if (KeyInfoT::isEqual(TheBucket->first, getEmptyKey())) {
incrementNumEntries(); //桶使用量 +1
}
else if (KeyInfoT::isEqual(TheBucket->first, getTombstoneKey())) { //如果找到的是墓碑
incrementNumEntries(); //桶使用量 +1
decrementNumTombstones(); //墓碑数量 -1
}
else if (ZeroValuesArePurgeable && TheBucket->second == 0) { //找到的位置是 value 为 0 的位置
TheBucket->second.~ValueT(); //测试中这句代码被直接跳过并没有执行, value 还是 0
} else {
// 其它情况, 并没有成员数量的变化(官方注释是 Updating an existing entry.)
}
return TheBucket;
}
weak部分——weak_table_t
weak_table_t在SideTable结构体中,储存对象弱引用指针的Hash表,weak功能实现的核心数据结构
首先我们来看一下weak_table_t结构体的源码:
struct weak_table_t {
weak_entry_t *weak_entries;//连续地址空间的头指针,数组
size_t num_entries;//数组中已占用位置的个数
uintptr_t mask;//数组下标最大值(即数组大小 -1)
uintptr_t max_hash_displacement;//最大哈希偏移值
};
weak_table 是一个哈希表的结构, 根据 weak 指针指向的对象的地址计算哈希值, 哈希值相同的对象按照下标 +1 的形式向后查找可用位置, 是典型的闭散列算法. 最大哈希偏移值即是所有对象中计算出的哈希值和实际插入位置的最大偏移量, 在查找时可以作为循环的上限。
weak_table结构图:
weak_entry_t 的成员
struct weak_entry_t {
DisguisedPtr<objc_object> referent; //对象地址
union { //这里又是一个联合体, 苹果设计的数据结构的确很棒
struct {
// 因为这里要存储的又是一个 weak 指针数组, 所以苹果继续选择采用哈希算法
weak_referrer_t *referrers; //指向 referent 对象的 weak 指针数组
uintptr_t out_of_line_ness : 2; //这里标记是否超过内联边界, 下面会提到
uintptr_t num_refs : PTR_MINUS_2; //数组中已占用的大小
uintptr_t mask; //数组下标最大值(数组大小 - 1)
uintptr_t max_hash_displacement; //最大哈希偏移值
};
struct {
//这是一个取名叫内联引用的数组
weak_referrer_t inline_referrers[WEAK_INLINE_COUNT]; //宏定义的值是 4
};
};
// weak_entry_t 的赋值操作,直接使用 memcpy 函数拷贝 other 内存里面的内容到 this 中,
// 而不是用复制构造函数什么的形式实现,应该也是为了提高效率考虑的...
weak_entry_t& operator=(const weak_entry_t& other) {
memcpy(this, &other, sizeof(other));
return *this;
}
// 返回 true 表示使用 referrers 哈希数组 false 表示使用 inline_referrers 数组保存 weak_referrer_t
bool out_of_line() {
return (out_of_line_ness == REFERRERS_OUT_OF_LINE);
}
// weak_entry_t 的构造函数
// newReferent 是原始对象的指针,
// newReferrer 则是指向 newReferent 的弱引用变量的指针。
// 初始化列表 referent(newReferent) 会调用: DisguisedPtr(T* ptr) : value(disguise(ptr)) { } 构造函数,
// 调用 disguise 函数把 newReferent 转化为一个整数赋值给 value。
weak_entry_t(objc_object *newReferent, objc_object **newReferrer)
: referent(newReferent)
{
// 把 newReferrer 放在数组 0 位,也会调用 DisguisedPtr 构造函数,把 newReferrer 转化为整数保存
inline_referrers[0] = newReferrer;
// 循环把 inline_referrers 数组的剩余 3 位都置为 nil
for (int i = 1; i < WEAK_INLINE_COUNT; i++) {
inline_referrers[i] = nil;
}
}
}
我们通过对象的地址, 可以在 weak_table_t 中找到对应的 weak_entry_t, weak_entry_t 中保存了所有指向这个对象的 weak 指针
苹果在 weak_entry_t 中又使用了一个共用体, 第一个结构体中 out_of_line_ness 占用 2bit, num_refs 在 64 位环境下占用了 62bit, 所以实际上两个结构体都是 32 字节, 共用一段地址. 当指向这个对象的 weak 指针不超过 4 个, 则直接使用数组 inline_referrers, 省去了哈希操作的步骤, 如果 weak 指针个数超过了 4 个, 就要使用第一个结构体中的哈希表.
weak_table的大概逻辑
- 在 ARC 下, 编译器会自动添加管理引用计数的代码, weak 指针赋值的时候, 编译器会调用
storeWeak来赋值, 若 weak 指针有指向的对象, 那么会先调用weak_unregister_no_lock()方法来从原有的表中先删除这个 weak 指针, 然后再调用weak_register_no_lock()来向对应的表中插入这个 weak 指针 - 查找时先用被指向对象的地址来计算哈希值, 从
SideTables()中找到对应的SideTable, 再进一步使用这个对象地址来从SideTable的weak_table中找到对应的weak_entry_t. 最终要进行操作的就是这个weak_entry_t. - 如果这个对象的 weak 指针不超过 4 个, 则直接操作
inline_referrers数组, 否则会为referrers数组申请内存, 采用哈希算法来管理表. - 删除旧的 weak 指针时, 会使用原本指向的对象的地址来查找对应的
weak_entry_t, 从中删除这个 weak 指针. 如果删除之后 weak 指针数组为空, 则销毁这个weak_entry_t, 原有位置置空, 原本被指向对象的 isa 指针的 weak 引用标记位 0. - 添加新的 weak 指针时, 如果查找到对应的
weak_entry_t, 则将 weak 指针插入到 referrers 数组中. 如果没找到则创建一个weak_entry_t配置好后插入weak_table_t的数组中.
weak的重要实现方法
objc_initWeak 函数
初始化开始时,会调用 objc_initWeak 函数,初始化新的 weak 指针指向对象的地址。当我们初始化 weak 变量时,runtime 会调用 NSObject.m 中的 objc_initWeak,而 objc_initWeak 函数里面的实现如下:
id objc_initWeak(id *location, id newObj) {
// 查看对象实例是否有效,无效对象直接导致指针释放
if (!newObj) {
*location = nil;
return nil;
}
// 这里传递了三个 Bool 数值
// 使用 template 进行常量参数传递是为了优化性能
return storeWeakfalse/*old*/, true/*new*/, true/*crash*/>
(location, (objc_object*)newObj);
}
然后我们看一下objc_initWeak()传入的两个参数代表什么:
-
location:__weak指针的地址,存储指针的地址,这样便可以在最后将其指向的对象置为nil。 -
newObj:所引用的对象。即例子中的p。
通过上面代码可以看出,objc_initWeak()函数首先判断指针指向的类对象是否有效,无效直接返回;否则通过 storeWeak() 被注册为一个指向 value 的 _weak 对象
objc_initWeak 函数里面会调用 objc_storeWeak() 函数,objc_storeWeak() 函数的作用是用来更新指针的指向,创建弱引用表。
objc_initWeak函数有一个前提条件:就是object必须是一个没有被注册为__weak对象的有效指针。而value则可以是nil,或者指向一个有效的对象。
objc_storeWeak()
// HaveOld: true - 变量有值
// false - 需要被及时清理,当前值可能为 nil
// HaveNew: true - 需要被分配的新值,当前值可能为 nil
// false - 不需要分配新值
// CrashIfDeallocating: true - 说明 newObj 已经释放或者 newObj 不支持弱引用,该过程需要暂停
// false - 用 nil 替代存储
template bool HaveOld, bool HaveNew, bool CrashIfDeallocating>
static id storeWeak(id *location, objc_object *newObj) {
// 该过程用来更新弱引用指针的指向
// 初始化 previouslyInitializedClass 指针
Class previouslyInitializedClass = nil;
id oldObj;
// 声明两个 SideTable
// ① 新旧散列创建
SideTable *oldTable;
SideTable *newTable;
// 获得新值和旧值的锁存位置(用地址作为唯一标示)
// 通过地址来建立索引标志,防止桶重复
// 下面指向的操作会改变旧值
retry:
if (HaveOld) {
// 更改指针,获得以 oldObj 为索引所存储的值地址
oldObj = *location;
oldTable = &SideTables()[oldObj];
} else {
oldTable = nil;
}
if (HaveNew) {
// 更改新值指针,获得以 newObj 为索引所存储的值地址
newTable = &SideTables()[newObj];
} else {
newTable = nil;
}
// 加锁操作,防止多线程中竞争冲突
SideTable::lockTwoHaveOld, HaveNew>(oldTable, newTable);
// 避免线程冲突重处理
// location 应该与 oldObj 保持一致,如果不同,说明当前的 location 已经处理过 oldObj 可是又被其他线程所修改
if (HaveOld && *location != oldObj) {
SideTable::unlockTwoHaveOld, HaveNew>(oldTable, newTable);
goto retry;
}
// 防止弱引用间死锁
// 并且通过 +initialize 初始化构造器保证所有弱引用的 isa 非空指向
if (HaveNew && newObj) {
// 获得新对象的 isa 指针
Class cls = newObj->getIsa();
// 判断 isa 非空且已经初始化
if (cls != previouslyInitializedClass &&
!((objc_class *)cls)->isInitialized()) {
// 解锁
SideTable::unlockTwoHaveOld, HaveNew>(oldTable, newTable);
// 对其 isa 指针进行初始化
_class_initialize(_class_getNonMetaClass(cls, (id)newObj));
// 如果该类已经完成执行 +initialize 方法是最理想情况
// 如果该类 +initialize 在线程中
// 例如 +initialize 正在调用 storeWeak 方法
// 需要手动对其增加保护策略,并设置 previouslyInitializedClass 指针进行标记
previouslyInitializedClass = cls;
// 重新尝试
goto retry;
}
}
// ② 清除旧值
if (HaveOld) {
weak_unregister_no_lock(&oldTable->weak_table, oldObj, location);
}
// ③ 分配新值
if (HaveNew) {
newObj = (objc_object *)weak_register_no_lock(&newTable->weak_table,
(id)newObj, location,
CrashIfDeallocating);
// 如果弱引用被释放 weak_register_no_lock 方法返回 nil
// 在引用计数表中设置若引用标记位
if (newObj && !newObj->isTaggedPointer()) {
// 弱引用位初始化操作
// 引用计数那张散列表的weak引用对象的引用计数中标识为weak引用
newObj->setWeaklyReferenced_nolock();
}
// 之前不要设置 location 对象,这里需要更改指针指向
*location = (id)newObj;
}
else {
// 没有新值,则无需更改
}
SideTable::unlockTwoHaveOld, HaveNew>(oldTable, newTable);
return (id)newObj;
}
storeWeak 方法的实现代码虽然有些长,但是并不难以理解。下面我们来分析下该方法的实现:
-
storeWeak方法实际上是接收了3个参数,分别是haveOld、haveNew和crashIfDeallocating,这三个参数都是以模板的方式传入的,是三个bool类型的参数。 分别表示weak指针之前是否指向了一个弱引用,weak指针是否需要指向一个新的引用,若果被弱引用的对象正在析构,此时再弱引用该对象是否应该crash。 - 该方法维护了
oldTable和newTable分别表示旧的引用弱表和新的弱引用表,它们都是SideTable的hash表。 - 如果
weak指针之前指向了一个弱引用,则会调用weak_unregister_no_lock方法将旧的weak指针地址移除(前提是weak指针会指向一个新的对象)。 - 如果weak指针需要指向一个新的引用,则会调用
weak_register_no_lock方法将新的weak指针地址添加到弱引用表中。 - 调用
setWeaklyReferenced_nolock方法修改weak新引用的对象的bit标志位(优化版isa指针的标记是否被弱引用的成员变量)
向weak_entry_t中添加新指向的对象时的方法是weak_register_no_lock
weak_register_no_lock
id
weak_register_no_lock(weak_table_t *weak_table, id referent_id,
id *referrer_id, bool crashIfDeallocating)
{
objc_object *referent = (objc_object *)referent_id;
objc_object **referrer = (objc_object **)referrer_id;
// 如果referent为nil 或 referent 采用了TaggedPointer计数方式,直接返回,不做任何操作
if (!referent || referent->isTaggedPointer()) return referent_id;
// 确保被引用的对象可用(没有在析构,同时应该支持weak引用)
bool deallocating;
if (!referent->ISA()->hasCustomRR()) {
deallocating = referent->rootIsDeallocating();
}
else {
BOOL (*allowsWeakReference)(objc_object *, SEL) =
(BOOL(*)(objc_object *, SEL))
object_getMethodImplementation((id)referent,
SEL_allowsWeakReference);
if ((IMP)allowsWeakReference == _objc_msgForward) {
return nil;
}
deallocating =
! (*allowsWeakReference)(referent, SEL_allowsWeakReference);
}
// 正在析构的对象,不能够被弱引用
if (deallocating) {
if (crashIfDeallocating) {
_objc_fatal("Cannot form weak reference to instance (%p) of "
"class %s. It is possible that this object was "
"over-released, or is in the process of deallocation.",
(void*)referent, object_getClassName((id)referent));
} else {
return nil;
}
}
// now remember it and where it is being stored
// 在 weak_table中找到referent对应的weak_entry,并将referrer加入到weak_entry中
weak_entry_t *entry;
if ((entry = weak_entry_for_referent(weak_table, referent))) { // 如果能找到weak_entry,则讲referrer插入到weak_entry中
append_referrer(entry, referrer); // 将referrer插入到weak_entry_t的引用数组中
}
else { // 如果找不到,就新建一个
weak_entry_t new_entry(referent, referrer);
weak_grow_maybe(weak_table);
weak_entry_insert(weak_table, &new_entry);
}
// Do not set *referrer. objc_storeWeak() requires that the
// value not change.
return referent_id;
}
该方法需要传进四个参数,它们代表的意义如下:
-
weak_table:weak_table_t结构类型的全局的弱引用表。 -
referent_id:weak指针。 -
*referrer_id:weak指针地址。 -
crashIfDeallocating: 若果被弱引用的对象正在析构,此时再弱引用该对象是否应该crash。
这个方法的大概流程:
- 如果
referent为nil 或referent采用了TaggedPointer计数方式,直接返回,不做任何操作。 - 如果对象正在析构,则抛出异常。
- 如果对象不能被
weak引用,直接返回nil。 - 如果对象没有再析构且可以被
weak引用,则调用weak_entry_for_referent方法根据弱引用对象的地址从弱引用表中找到对应的weak_entry,如果能够找到则调用append_referrer方法向其中插入weak指针地址。否则新建一个weak_entry。
weak_entry的方法weak_entry_for_referent的源码实现:
weak_entry_for_referent
static weak_entry_t *
weak_entry_for_referent(weak_table_t *weak_table, objc_object *referent)
{
assert(referent);
weak_entry_t *weak_entries = weak_table->weak_entries;
if (!weak_entries) return nil;
size_t begin = hash_pointer(referent) & weak_table->mask; // 这里通过 & weak_table->mask的位操作,来确保index不会越界
size_t index = begin;
size_t hash_displacement = 0;
while (weak_table->weak_entries[index].referent != referent) {
index = (index+1) & weak_table->mask;
if (index == begin) bad_weak_table(weak_table->weak_entries); // 触发bad weak table crash
hash_displacement++;
if (hash_displacement > weak_table->max_hash_displacement) { // 当hash冲突超过了可能的max hash 冲突时,说明元素没有在hash表中,返回nil
return nil;
}
}
return &weak_table->weak_entries[index];
}
接着我们来看一下向weak_entry中添加元素的方法append_referrer的源码实现:
append_referrer
static void append_referrer(weak_entry_t *entry, objc_object **new_referrer)
{
if (! entry->out_of_line()) { // 如果weak_entry 尚未使用动态数组,走这里
// Try to insert inline.
//尝试插入内联引用的数组
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i] == nil) {
entry->inline_referrers[i] = new_referrer;
return;
}
}
// 如果inline_referrers的位置已经存满了,则要转型为referrers,做动态数组。
// Couldn't insert inline. Allocate out of line.
weak_referrer_t *new_referrers = (weak_referrer_t *)
calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t));
// This constructed table is invalid, but grow_refs_and_insert
// will fix it and rehash it.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
new_referrers[i] = entry->inline_referrers[I];
}
entry->referrers = new_referrers;
entry->num_refs = WEAK_INLINE_COUNT;
entry->out_of_line_ness = REFERRERS_OUT_OF_LINE;
entry->mask = WEAK_INLINE_COUNT-1;
entry->max_hash_displacement = 0;
}
// 对于动态数组的附加处理:
assert(entry->out_of_line()); // 断言: 此时一定使用的动态数组
if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) { // 如果动态数组中元素个数大于或等于数组位置总空间的3/4,则扩展数组空间为当前长度的一倍
return grow_refs_and_insert(entry, new_referrer); // 扩容,并插入
}
// 如果不需要扩容,直接插入到weak_entry中
// 注意,weak_entry是一个哈希表,key:w_hash_pointer(new_referrer) value: new_referrer
// 细心的人可能注意到了,这里weak_entry_t 的hash算法和 weak_table_t的hash算法是一样的,同时扩容/减容的算法也是一样的
size_t begin = w_hash_pointer(new_referrer) & (entry->mask); // '& (entry->mask)' 确保了 begin的位置只能大于或等于 数组的长度
size_t index = begin; // 初始的hash index
size_t hash_displacement = 0; // 用于记录hash冲突的次数,也就是hash再位移的次数
while (entry->referrers[index] != nil) {
hash_displacement++;
index = (index+1) & entry->mask; // index + 1, 移到下一个位置,再试一次能否插入。(这里要考虑到entry->mask取值,一定是:0x111, 0x1111, 0x11111, ... ,因为数组每次都是*2增长,即8, 16, 32,对应动态数组空间长度-1的mask,也就是前面的取值。)
if (index == begin) bad_weak_table(entry); // index == begin 意味着数组绕了一圈都没有找到合适位置,这时候一定是出了什么问题。
}
if (hash_displacement > entry->max_hash_displacement) { // 记录最大的hash冲突次数, max_hash_displacement意味着: 我们尝试至多max_hash_displacement次,肯定能够找到object对应的hash位置
entry->max_hash_displacement = hash_displacement;
}
// 将ref存入hash数组,同时,更新元素个数num_refs
weak_referrer_t &ref = entry->referrers[index];
ref = new_referrer;
entry->num_refs++;
}
这段代码首先确定是使用定长数组还是动态数组,如果是使用定长数组,则直接将weak指针地址添加到数组即可,如果定长数组已经用尽,则需要将定长数组中的元素转存到动态数组中。
接着我们来看一下weak指针移除弱引用,需要清除weak_entry时调用的方法:weak_unregister_no_lock,方法里面将旧的weak指针地址移除了。
weak_unregister_no_lock
void
weak_unregister_no_lock(weak_table_t *weak_table, id referent_id,
id *referrer_id)
{
//对象的地址
objc_object *referent = (objc_object *)referent_id;
//weak指针地址
objc_object **referrer = (objc_object **)referrer_id;
weak_entry_t *entry;
if (!referent) return;
if ((entry = weak_entry_for_referent(weak_table, referent))) { // 查找到referent所对应的weak_entry_t
remove_referrer(entry, referrer); // 在referent所对应的weak_entry_t的hash数组中,移除referrer
// 移除元素之后, 要检查一下weak_entry_t的hash数组是否已经空了
bool empty = true;
if (entry->out_of_line() && entry->num_refs != 0) {
empty = false;
}
else {
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i]) {
empty = false;
break;
}
}
}
if (empty) { // 如果weak_entry_t的hash数组已经空了,则需要将weak_entry_t从weak_table中移除
weak_entry_remove(weak_table, entry);
}
}
// Do not set *referrer = nil. objc_storeWeak() requires that the
// value not change.
}
大概流程:
- 首先,它会在weak_table中找出referent对应的weak_entry_t
- 在weak_entry_t中移除referrer
- 移除元素后,判断此时weak_entry_t中是否还有元素 (empty==true?)
- 如果此时weak_entry_t已经没有元素了,则需要将weak_entry_t从weak_table中移除
当对象释放时,所有weak引用它的指针又是如何自动设置为nil的呢?
dealloc
当对象的引用计数为0时,底层会调用_objc_rootDealloc方法对对象进行释放,而在_objc_rootDealloc方法里面会调用rootDealloc方法。如下是rootDealloc方法的代码实现:
inline void
objc_object::rootDealloc()
{
if (isTaggedPointer()) return; // fixme necessary?
if (fastpath(isa.nonpointer &&
!isa.weakly_referenced &&
!isa.has_assoc &&
!isa.has_cxx_dtor &&
!isa.has_sidetable_rc))
{
assert(!sidetable_present());
free(this);
}
else {
object_dispose((id)this);
}
}
大概流程:
- 首先判断对象是否是
Tagged Pointer,如果是则直接返回。 - 如果对象是采用了优化的
isa计数方式,且同时满足对象没有被weak引用!isa.weakly_referenced、没有关联对象!isa.has_assoc、没有自定义的C++析构方法!isa.has_cxx_dtor、没有用到SideTable来引用计数!isa.has_sidetable_rc则直接快速释放。 - 如果不能满足2中的条件,则会调用
object_dispose方法。
接着我们来看一下object_dispose方法的源码:
object_dispose
void *objc_destructInstance(id obj)
{
if (obj) {
// Read all of the flags at once for performance.
bool cxx = obj->hasCxxDtor();
bool assoc = obj->hasAssociatedObjects();
// This order is important.
if (cxx) object_cxxDestruct(obj);
if (assoc) _object_remove_associations(obj, /*deallocating*/true);
obj->clearDeallocating();
}
return obj;
}
如果有自定义的C++析构方法,则调用C++析构函数。如果有关联对象,则移除关联对象并将其自身从Association Manager的map中移除。调用clearDeallocating 方法清除对象的相关引用。
接着我们来分析清除对象的相关引用的方法clearDeallocating。
clearDeallocating
inline void
objc_object::clearDeallocating()
{
if (slowpath(!isa.nonpointer)) {
// Slow path for raw pointer isa.
sidetable_clearDeallocating();
}
else if (slowpath(isa.weakly_referenced || isa.has_sidetable_rc)) {
// Slow path for non-pointer isa with weak refs and/or side table data.
clearDeallocating_slow();
}
assert(!sidetable_present());
}
clearDeallocating中有两个分支,先判断对象是否采用了优化isa引用计数,如果没有的话则需要调用sidetable_clearDeallocating方法清理对象存储在SideTable中的引用计数数据。如果对象采用了优化isa引用计数,则判断是否有使用SideTable的辅助引用计数(isa.has_sidetable_rc)或者有weak引用(isa.weakly_referenced),符合这两种情况中一种的,调用clearDeallocating_slow 方法。
下面来看一下sidetable_clearDeallocating方法和clearDeallocating_slow方法
sidetable_clearDeallocating
void
objc_object::sidetable_clearDeallocating()
{
SideTable& table = SideTables()[this];
// clear any weak table items
// clear extra retain count and deallocating bit
// (fixme warn or abort if extra retain count == 0 ?)
//清除所有弱表项
//清除额外的保留计数和释放位
//(如果额外保留计数==0,则修复警告或中止)
table.lock();
RefcountMap::iterator it = table.refcnts.find(this);
if (it != table.refcnts.end()) {
if (it->second & SIDE_TABLE_WEAKLY_REFERENCED) {
weak_clear_no_lock(&table.weak_table, (id)this);
}
table.refcnts.erase(it);
}
table.unlock();
}
clearDeallocating_slow
NEVER_INLINE void
objc_object::clearDeallocating_slow()
{
assert(isa.nonpointer && (isa.weakly_referenced || isa.has_sidetable_rc));
SideTable& table = SideTables()[this]; // 在全局的SideTables中,以this指针为key,找到对应的SideTable
table.lock();
if (isa.weakly_referenced) { // 如果obj被弱引用
weak_clear_no_lock(&table.weak_table, (id)this); // 在SideTable的weak_table中对this进行清理工作
}
if (isa.has_sidetable_rc) { // 如果采用了SideTable做引用计数
table.refcnts.erase(this); // 在SideTable的引用计数中移除this
}
table.unlock();
}
上面两个方法都调用了weak_clear_no_lock来做weak_table的清理工作。
weak_clear_no_lock
void
weak_clear_no_lock(weak_table_t *weak_table, id referent_id)
{
objc_object *referent = (objc_object *)referent_id;
weak_entry_t *entry = weak_entry_for_referent(weak_table, referent); // 找到referent在weak_table中对应的weak_entry_t
if (entry == nil) {
/// XXX shouldn't happen, but does with mismatched CF/objc
//printf("XXX no entry for clear deallocating %p\n", referent);
return;
}
// zero out references
weak_referrer_t *referrers;
size_t count;
// 找出weak引用referent的weak 指针地址数组以及数组长度
if (entry->out_of_line()) {
referrers = entry->referrers;
count = TABLE_SIZE(entry);
}
else {
referrers = entry->inline_referrers;
count = WEAK_INLINE_COUNT;
}
for (size_t i = 0; i < count; ++i) {
objc_object **referrer = referrers[i]; // 取出每个weak ptr的地址
if (referrer) {
if (*referrer == referent) { // 如果weak ptr确实weak引用了referent,则将weak ptr设置为nil,这也就是为什么weak 指针会自动设置为nil的原因
*referrer = nil;
}
else if (*referrer) { // 如果所存储的weak ptr没有weak 引用referent,这可能是由于runtime代码的逻辑错误引起的,报错
_objc_inform("__weak variable at %p holds %p instead of %p. "
"This is probably incorrect use of "
"objc_storeWeak() and objc_loadWeak(). "
"Break on objc_weak_error to debug.\n",
referrer, (void*)*referrer, (void*)referent);
objc_weak_error();
}
}
}
weak_entry_remove(weak_table, entry); // 由于referent要被释放了,因此referent的weak_entry_t也要移除出weak_table
}
最后再来看一下weak指针销毁的方法:
void
objc_destroyWeak(id *location)
{
(void)storeWeak<DoHaveOld, DontHaveNew, DontCrashIfDeallocating>
(location, nil);
}
该处调用storeWeak方法之后,由于没有指向新的对象,若我们的weak指针原来已经指向一个对象的话就会到:weak_unregister_no_lock中来将旧的weak指针地址移除掉置为nil。
简单概括一下dealloc过程:
1、从weak表中,以dealloc对象为key,找到对应的weak_entry_t。
2、将weak_entry_t中的所有附有weak修饰符变量的地址,赋值为nil。
3、将weak表中该对象移除。
总结
-
weak的原理在于底层维护了一张weak_table_t结构的hash表,key是所指对象的地址,value是weak指针的地址数组。 -
weak关键字的作用是弱引用,所引用对象的计数器不会加1,并在引用对象被释放的时候自动被设置为nil。 - 对象释放时,调用
clearDeallocating函数根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,最后清理对象的记录。
问题
1. weak修饰的释放则自动被置为nil的实现原理
-
Runtime维护着一个Weak表,用于存储指向某个对象的所有Weak指针 -
Weak表是Hash表,Key是所指对象的地址,Value是Weak指针地址的数组 - 在对象被回收的时候,经过层层调用,会最终触发下面的方法将所有
Weak指针的值设为nil。* runtime源码,objc-weak.m的arr_clear_deallocating函数 -
weak指针的使用涉及到Hash表的增删改查,有一定的性能开销.
2. 请简单说明并比较以下关键词:strong, weak, assign, copy
-
strong表示指向并拥有该对象。其修饰的对象引用计数会增加1。该对象只要引用计数不为 0 则不会被销毁。当然强行将其设为 nil 可以销毁它。 -
weak表示指向但不拥有该对象。其修饰的对象引用计数不会增加。无需手动设置,该对象会自行在内存中销毁。 -
assign主要用于修饰基本数据类型,如NSInteger和CGFloat,这些数值主要存在于栈上。 -
weak一般用来修饰对象,assign一般用来修饰基本数据类型。原因是assign修饰的对象被释放后,指针的地址依然存在,造成野指针,在堆上容易造成崩溃。而栈上的内存系统会自动处理,不会造成野指针。 -
copy与strong类似。不同之处是strong的复制是多个指针指向同一个地址,而copy的复制每次会在内存中拷贝一份对象,指针指向不同地址。copy一般用在修饰有可变对应类型的不可变对象上,如NSString,NSArray,NSDictionary。 -
Objective-C中,基本数据类型的默认关键字是atomic,readwrite,assign;普通属性的默认关键字是atomic,readwrite,strong。
3. 请说明并比较以下关键词:__weak,__block
-
__weak与weak基本相同。前者用于修饰变量(variable),后者用于修饰属性(property)。__weak主要用于防止block中的循环引用。 -
__block也用于修饰变量。它是引用修饰,所以其修饰的值是动态变化的,即可以被重新赋值的。__block用于修饰某些block内部将要修改的外部变量。 -
__weak和__block的使用场景几乎与block息息相关。而所谓block,就是Objective-C对于闭包的实现。闭包就是没有名字的函数,或者理解为指向函数的指针。
4. runtime 如何实现 weak 属性?
runtime 如何实现 weak 属性具体流程大致分为 3 步:文章来源:https://www.toymoban.com/news/detail-590558.html
- 1、初始化时:
runtime会调用objc_initWeak函数,初始化一个新的weak指针指向对象的地址。 - 2、添加引用时:
objc_initWeak函数会调用objc_storeWeak()函数,objc_storeWeak()的作用是更新指针指向(指针可能原来指向着其他对象,这时候需要将该weak指针与旧对象解除绑定,会调用到weak_unregister_no_lock(),如果指针指向的新对象非空,则创建对应的弱引用表,将weak指针与新对象进行绑定,会调用到weak_register_no_lock。在这个过程中,为了防止多线程中竞争冲突,会有一些锁的操作。 - 3、释放时:调用
clearDeallocating函数,clearDeallocating函数首先根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,最后清理对象的记录。
5.浅拷贝和深拷贝的区别?
- 浅拷贝只是对 内存地址的复制,两个指针指向同一个地址,增加被拷贝对象的引用计数,没有发生新的内存分配。
- 深拷贝:目标对象指针和源对象指针,指向两片内容相同的内存空间。
- 2个特点:不会增加被拷贝对象的引用计数,产生了新内存分配,出现了2块内存。
-
- 浅拷贝增加引用计数,不产生新的内存。
-
- 深拷贝不增加引用计数,会新分配内存
6.NSMutableArray用copy修饰会出现什么问题?
出现调用可变方法不可控问题,会导致程序崩溃。给Mutable 被声明为copy修饰的属性赋值, 过程描述如下:文章来源地址https://www.toymoban.com/news/detail-590558.html
- 如果赋值过来的是
NSMutableArray对象,会对可变对象进行copy操作,拷贝结果是不可变的,那么copy后就是NSArray - 如果赋值过来的是
NSArray对象, 会对不可变对象进行copy操作,拷贝结果仍是不可变的,那么copy之后仍是NSArray。 - 所以不论赋值过来的是什么对象,只要对
NSMutableArray进行copy操作,返回的对象都是不可变的。 - 那原来属性声明的是
NSMutableArray,可能会调用了add或者remove方法,拷贝后的结果是不可变对象,所以一旦调用这些方法就会程序崩溃(crash)
7.如何理解的atomic的线程安全呢,有没有什么隐患?
- 保证
setter和getter存取方法的线程安全(仅仅对setter和getter方法加锁)。 -
atomic对一个数组,进行赋值或获取,是可以保证线程安全的。但是如果进行数组进行操作,比如给数据加对象或移除对象,是不在atomic的保证范围。
到了这里,关于【iOS】—— 属性关键字及weak关键字底层原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!