一、多表关系
-
一对多或者多对一
- 案例:部门与员工的关系
- 关系:一个部门对应多个员工,一个员工对应一个部门(不考虑跨部门的特殊情况)
- 实现:在多的一方建立外键,指向一的一方的主键,这里员工表是多的的一方,部门表是一的一方

文章来源地址https://www.toymoban.com/news/detail-591396.html
-
多对多
- 案例:学生与课程的关系
- 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
- 实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

-
一对一
- 案例:用户与用户详情的关系
- 关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表,其他详情字段放在另外一张表中,艺体生操作效率
- 实现:在任意一方加入外键,关联另外一方的主键,并且设置为唯一的(unique)
- 说明:这个是外键user_id需要加一个约束保证其唯一,从而保证一个详情只能对应一个用户。

二、多表查询
2.1、概述:
多表查询指从多张数据表中查询数据
2.2、分类:
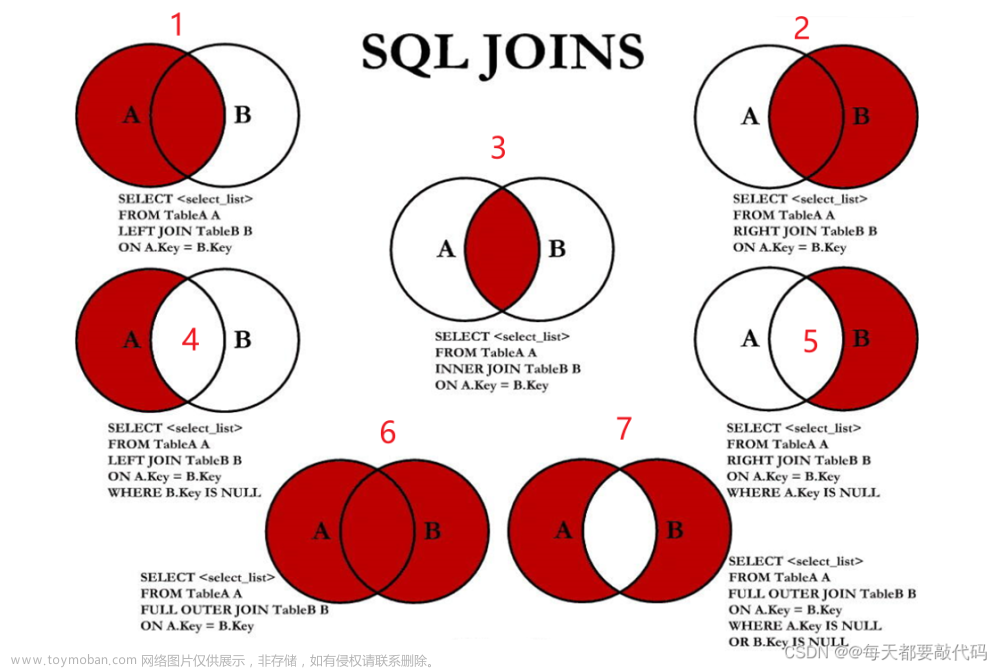
-
- 连接查询
- 内连接:相当于查询A、B交集部分数据
- 外连接
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,已经两张表交集部分数据:
- 自连接:当前表与自身的连接查询,连接必须使用表别名
- 子查询
- 联合查询
- 连接查询
三、示例数据表结构及数据
3.1、emp:员工表结构及数据
mysql> select * from emp; +----+--------+------+--------------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------------+--------+------------+-----------+---------+ | 1 | 张三 | 43 | 董事长 | 48000 | 2017-07-20 | NULL | 5 | | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | | 8 | 静静 | 27 | 人事 | 5000 | 2021-07-11 | 1 | NULL | +----+--------+------+--------------+--------+------------+-----------+---------+ 8 rows in set (0.00 sec)
3.2、dept:部门表结构及数据
mysql> select * from dept; +----+-----------+ | id | name | +----+-----------+ | 1 | 研发部 | | 2 | 市场部 | | 3 | 财务部 | | 4 | 销售部 | | 5 | 总经办 | | 6 | 人事部 | +----+-----------+ 6 rows in set (0.00 sec)
3.3、score1:成绩表1结构及数据
mysql> select * from score1; +----+--------+-------+ | id | name | score | +----+--------+-------+ | 1 | 张三 | 94 | | 2 | 李四 | 93 | | 3 | 王五 | 87 | | 4 | 赵六 | 71 | +----+--------+-------+ 4 rows in set (0.00 sec)
文章来源:https://www.toymoban.com/news/detail-591396.html
3.4、score2:成绩表2结构及数据
mysql> select * from score2; +----+--------+-------+ | id | name | score | +----+--------+-------+ | 1 | 张三 | 94 | | 2 | 李四 | 97 | | 3 | 王五 | 91 | | 4 | 赵六 | 82 | +----+--------+-------+ 4 rows in set (0.00 sec)
四、内连接
4.1、概述:
内连接查询的是两张表的交集的部分
4.2、内连接查询语法
4.2.1 隐式内连接
select 字段列表 from 表1,表2 where 条件...;
4.2.2 显示内连接 inner可以省略不写
select 字段列表 from 表1 [inner] join 表2 on 连接条件...;
4.3、案例
案例1:查询每个员工的姓名,及关联的部门的名称(隐式内连接实现)
mysql> select emp.name,dept.name as dept_name from emp,dept where emp.dept_id = dept.id; +--------+-----------+ | name | dept_name | +--------+-----------+ | 张三 | 总经办 | | 李四 | 研发部 | | 问问 | 研发部 | | 芳芳 | 研发部 | | 珊珊 | 研发部 | | 娜娜 | 财务部 | | 咔咔 | 财务部 | +--------+-----------+ 7 rows in set (0.00 sec)
案例2:查询每个员工的姓名,及关联的部门的名称(显示内连接实现)
mysql> select emp.name,dept.name as dept_name from emp inner join dept on emp.dept_id = dept.id; +--------+-----------+ | name | dept_name | +--------+-----------+ | 张三 | 总经办 | | 李四 | 研发部 | | 问问 | 研发部 | | 芳芳 | 研发部 | | 珊珊 | 研发部 | | 娜娜 | 财务部 | | 咔咔 | 财务部 | +--------+-----------+ 7 rows in set (0.00 sec)
五、外连接
5.1、左外连接
简介:相当于查询表1(左表)的所有数据,包含表1和表2交集部分的数据
select 字段列表 from 表1 left [outer] join 表2 on 条件...;
5.2、右外连接
简介:相当于查表2(右表)的所有数据,包含表1和表2交集部分的数据
select 字段列表 from 表1 right [outer] join 表2 on 条件...;
5.3、案例
案例1:查询emp表的所有数据,和对应的部门信息(左外连接)
mysql> select emp.*, dept.name as dept_name from emp left join dept on emp.dept_id = dept.id; +----+--------+------+--------------+--------+------------+-----------+---------+-----------+ | id | name | age | job | salary | entrydate | managerid | dept_id | dept_name | +----+--------+------+--------------+--------+------------+-----------+---------+-----------+ | 1 | 张三 | 43 | 董事长 | 48000 | 2017-07-20 | NULL | 5 | 总经办 | | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | 研发部 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | 研发部 | | 4 | 芳芳 | 32 | 开发 | 21000 | 2019-08-18 | 2 | 1 | 研发部 | | 5 | 珊珊 | 27 | 开发 | 15000 | 2021-04-10 | 3 | 1 | 研发部 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | 财务部 | | 7 | 咔咔 | 29 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | 财务部 | | 8 | 静静 | 27 | 人事 | 5000 | 2021-07-11 | 1 | NULL | NULL | +----+--------+------+--------------+--------+------------+-----------+---------+-----------+ 8 rows in set (0.00 sec)
说明1:查询emp表的所有数据,即emp.*
说明2:as dept_name 是给dept.name 起的别名,防止查询结果中出现两个name字段,会有歧义
说明3:from 后面的是左表,所以该语句中emp是左表
说明4:join 后面的是右表,所以该语句中的dept是右表
说明5:连接关系是emp.dept_id = dept.id
说明6:outer关键字是可以省略的,不影响结果
案例2:查询dept表的所有数据,和对应的员工信息(右外连接)
mysql> select dept.*, emp.* from emp right join dept on emp.dept_id = dept.id; +----+-----------+------+--------+------+--------------+--------+------------+-----------+---------+ | id | name | id | name | age | job | salary | entrydate | managerid | dept_id | +----+-----------+------+--------+------+--------------+--------+------------+-----------+---------+ | 1 | 研发部 | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 1 | 研发部 | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 1 | 研发部 | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 1 | 研发部 | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 2 | 市场部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | | 3 | 财务部 | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 3 | 财务部 | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | | 4 | 销售部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | | 5 | 总经办 | 1 | 张三 | 43 | 董事长 | 48000 | 2017-07-20 | NULL | 5 | | 6 | 人事部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | +----+-----------+------+--------+------+--------------+--------+------------+-----------+---------+ 10 rows in set (0.00 sec)
说明1:查询dept表的所有数据,又因为要求使用右连接,所以需要将右表作为主表,即dept要放在join关键字的后面
说明2:连接关系依然是emp.dept_id = dept.id
mysql> select dept.*, emp.* from dept left join emp on emp.dept_id = dept.id; +----+-----------+------+--------+------+--------------+--------+------------+-----------+---------+ | id | name | id | name | age | job | salary | entrydate | managerid | dept_id | +----+-----------+------+--------+------+--------------+--------+------------+-----------+---------+ | 1 | 研发部 | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 1 | 研发部 | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 1 | 研发部 | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 1 | 研发部 | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 2 | 市场部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | | 3 | 财务部 | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 3 | 财务部 | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | | 4 | 销售部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | | 5 | 总经办 | 1 | 张三 | 43 | 董事长 | 48000 | 2017-07-20 | NULL | 5 | | 6 | 人事部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | +----+-----------+------+--------+------+--------------+--------+------------+-----------+---------+ 10 rows in set (0.00 sec)
说明3:左连接和右连接其实是可以互换的,主要看表的位置
六、自连接
6.1、自连接查询语法
select 字段列表 from 表A,别名A join 表A 别名B on 条件...;
6.2、自连接查询
可以是内连接查询,也可以是外连接查询
6.3、案例
案例1:查询员工及其所属的领导的名字
mysql> select a.name, b.name from emp as a,emp as b where a.managerid = b.id; +--------+--------+ | name | name | +--------+--------+ | 李四 | 张三 | | 问问 | 李四 | | 芳芳 | 李四 | | 珊珊 | 问问 | | 娜娜 | 张三 | | 咔咔 | 娜娜 | | 静静 | 张三 | +--------+--------+ 7 rows in set (0.00 sec)
说明1:通过where 将两个表连接起来的方式,内连接方式
说明2:因为是内连接方式,所以id=1的张三,所属领导为null,就不会被查询出来
说明3:自连接必须要起别名,而且要给自己起两个别名。相互连接才行,所以自连接,就是一个表起了两个别名互相连接
案例2:查询所有员工 emp 及其领导的名字,如果员工没有领导也需要查询出来
mysql> select a.name as "员工", b.name as "领导" from emp as a left join emp as b on a.managerid = b.id; +--------+--------+ | 员工 | 领导 | +--------+--------+ | 张三 | NULL | | 李四 | 张三 | | 问问 | 李四 | | 芳芳 | 李四 | | 珊珊 | 问问 | | 娜娜 | 张三 | | 咔咔 | 娜娜 | | 静静 | 张三 | +--------+--------+ 8 rows in set (0.00 sec)
说明1:因为没有领导的也要查询出来,所以就不能使用内连接,需要使用外连接,left和right都可以
说明2:同样需要给emp起两个别名
七、联合查询
7.1、联合查询:
union / union all 就是把多次查询的结果合并起来,形成一个新的查询结果集
select 字段列表 from 表A ... union [all] select 字段列表 from 表B ...
说明1:union all 会将查询出来的两个结果集全部合并,不会去重
说明2:union 如果不带all 则会将两个结果集合并,并且去重
说明3:对于联合查询的多张表的列数和字段类型必须要保持一致
7.2、案例
案例1:现在有score1和score2两张成成绩表,将两张表中都大于90分的查找出来合并显示
分析1:先查询出来score1表中大于90的学生
mysql> select * from score1 where score>90; +----+--------+-------+ | id | name | score | +----+--------+-------+ | 1 | 张三 | 94 | | 2 | 李四 | 93 | +----+--------+-------+ 2 rows in set (0.00 sec)
分析2:在查询出来score2表中大于90的学生
mysql> select * from score2 where score>90; +----+--------+-------+ | id | name | score | +----+--------+-------+ | 1 | 张三 | 94 | | 2 | 李四 | 97 | | 3 | 王五 | 91 | +----+--------+-------+ 3 rows in set (0.00 sec)
分析3:联合查询
mysql> select * from score1 where score>90 union all select * from score2 where score>90; +----+--------+-------+ | id | name | score | +----+--------+-------+ | 1 | 张三 | 94 | | 2 | 李四 | 93 | | 1 | 张三 | 94 | | 2 | 李四 | 97 | | 3 | 王五 | 91 | +----+--------+-------+ 5 rows in set (0.00 sec)
说明1:因为使用的是union all 所以保留了所有数据
mysql> select * from score1 where score>90 union select * from score2 where score>90; +----+--------+-------+ | id | name | score | +----+--------+-------+ | 1 | 张三 | 94 | | 2 | 李四 | 93 | | 2 | 李四 | 97 | | 3 | 王五 | 91 | +----+--------+-------+ 4 rows in set (0.00 sec)
说明2:去掉了all 直接只使用了union,这个时候张三,94分重复的就只显示一次了
说明3:李四=93和李四=97,是两个不同的数据,所以不会被合并。
八、子查询
8.1、概念:
sql语句中嵌套select语句,成为嵌套查询,又称子查询
select * from t1 where column1=(select column1 from t2);
8.2、根据结果分类
-
- 标量子查询:子查询结果为单个值
- 列子查询:子查询结果为一列
- 行子查询:子查询结果为一行
- 表子查询:子查询结果为多行多列
8.3、根据位置分类
-
- where之后的子查询
- from 之后的子查询
- select之后的子查询
8.4、标量子查询
8.4.1 概念:子查询返回的结果是单个值(数字,字符串,日期等),最简单的形式,这种子查询称为标量子查询
8.4.2 常用的操作符:=, <, >, >=, <=
8.4.3 案例
案例1:查询"研发部"的所有员工信息
分析1:先查询研发部的部门id
mysql> select id from dept where name="研发部"; +----+ | id | +----+ | 1 | +----+ 1 row in set (0.00 sec) mysql>
分析2:根据研发部的部门id,查询员工信息
mysql> select * from emp where dept_id=1; +----+--------+------+--------------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------------+--------+------------+-----------+---------+ | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | +----+--------+------+--------------+--------+------------+-----------+---------+ 4 rows in set (0.01 sec)
分析3:使用标量子查询
mysql> select * from emp where dept_id = (select id from dept where name = "研发部"); +----+--------+------+--------------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------------+--------+------------+-----------+---------+ | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | +----+--------+------+--------------+--------+------------+-----------+---------+ 4 rows in set (0.00 sec)
案例2:查询珊珊入职之后的员工信息
分析1:查询“珊珊”的入职日期
mysql> select entrydate from emp where name = "珊珊"; +------------+ | entrydate | +------------+ | 2021-04-10 | +------------+ 1 row in set (0.00 sec)
分析2:查询指定日期之后的入职员工的信息
mysql> select * from emp where entrydate > "2021-04-10"; +----+--------+------+--------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------+--------+------------+-----------+---------+ | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | | 8 | 静静 | 27 | 人事 | 5000 | 2021-07-11 | 1 | NULL | +----+--------+------+--------+--------+------------+-----------+---------+ 4 rows in set (0.00 sec)
分析3:使用标量查询
mysql> select * from emp where entrydate > (select entrydate from emp where name = "珊珊"); +----+--------+------+--------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------+--------+------------+-----------+---------+ | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | | 8 | 静静 | 27 | 人事 | 5000 | 2021-07-11 | 1 | NULL | +----+--------+------+--------+--------+------------+-----------+---------+ 4 rows in set (0.00 sec)
8.5、列子查询
8.5.1 概念:子查询返回的结果是一列(可以是多行),这种子查询称为列子查询
8.5.2 常用操作符:in, not in, any, some, all
-
- in:在指定的集合范围内,多选一
- not in:不在指定的范围内
- any:子查询返回列表,有任意一个满足即可
- some:与any等同,使用some的地方都可以使用any
- all:子查询返回列表的所有值都必须满足
8.5.3 案例
案例1:查询研发部和财务部的所有员工
分析1:查询研发部和财务部的部门id
mysql> select id from dept where name="研发部" or name="财务部"; +----+ | id | +----+ | 1 | | 3 | +----+ 2 rows in set (0.00 sec)
分析2:根据部门id,查询员工信息
mysql> select * from emp where dept_id in (1,3); +----+--------+------+--------------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------------+--------+------------+-----------+---------+ | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | +----+--------+------+--------------+--------+------------+-----------+---------+ 6 rows in set (0.00 sec)
分析3:列子查询结果
mysql> select * from emp where dept_id in (select id from dept where name="研发部" or name="财务部"); +----+--------+------+--------------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------------+--------+------------+-----------+---------+ | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | +----+--------+------+--------------+--------+------------+-----------+---------+ 6 rows in set (0.01 sec)
案例2:查询比研发部工资都高的员工
分析1:查询研发部的部门id
mysql> select id from dept where name="研发部"; +----+ | id | +----+ | 1 | +----+ 1 row in set (0.00 sec)
分析2:根据研发部的id,查询出研发部所有人的工资
mysql> select salary from emp where dept_id = (select id from dept where name="研发部"); +--------+ | salary | +--------+ | 23900 | | 18000 | | 21000 | | 15000 | +--------+ 4 rows in set (0.00 sec)
分析3:比财务部所有人工资高的员工信息
mysql> select * from emp where salary > all(select salary from emp where dept_id = (select id from dept where name="研发部")); +----+--------+------+-----------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+-----------+--------+------------+-----------+---------+ | 1 | 张三 | 43 | 董事长 | 48000 | 2017-07-20 | NULL | 5 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | +----+--------+------+-----------+--------+------------+-----------+---------+ 2 rows in set (0.00 sec)
说明1:比研发部所有人的工资都高,其实就是比研发部最高人的工资还高
案例3:比研发部其中任意一人工资高的员工信息,其实就是比研发部工资最低的人工资高
分析1:查询研发部所有人的工资
mysql> select salary from emp where dept_id = (select id from dept where name="研发部"); +--------+ | salary | +--------+ | 23900 | | 18000 | | 21000 | | 15000 | +--------+ 4 rows in set (0.00 sec)
分析2:比研发部任意一人工资高的员工信息
mysql> select * from emp where salary > any(select salary from emp where dept_id = (select id from dept where name="研发部")); +----+--------+------+--------------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------------+--------+------------+-----------+---------+ | 1 | 张三 | 43 | 董事长 | 48000 | 2017-07-20 | NULL | 5 | | 2 | 李四 | 38 | 项目经理 | 23900 | 2016-08-20 | 1 | 1 | | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | +----+--------+------+--------------+--------+------------+-----------+---------+ 5 rows in set (0.00 sec)
说明1:这里的any可以替换成some
8.6、行子查询
8.6.1 概念:子查询返回的结果是一行(可以是多列),这种查询称之为行子查询
8.6.2 常用的操作符:=,!=, in, not in
8.6.3 案例
案例1:查询和芳芳在同一个岗位,并且还是同一个直属领带的员工信息
分析1:先找到芳芳的岗位和直属领导
mysql> select job, managerid from emp where name = "芳芳"; +--------+-----------+ | job | managerid | +--------+-----------+ | 开发 | 2 | +--------+-----------+ 1 row in set (0.00 sec)
分析2:在利用上面的查询信息当做条件,查询到需要的结果
mysql> select * from emp where (job,managerid) = (select job,managerid from emp where name="芳芳"); +----+--------+------+--------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------+--------+------------+-----------+---------+ | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | +----+--------+------+--------+--------+------------+-----------+---------+ 2 rows in set (0.01 sec)
说明1:这种子查询返回结果是一行数据的,就叫做行子查询
8.7、表子查询
8.7.1 概念:子查询返回的结果是多行多列,这种子查询称为表子查询
8.7.2 常用的操作符:in
8.7.3 使用场景:经常将查询到的结果当做一个临时表使用
8.7.4 案例
案例1:查询与芳芳的年龄和部门一样或者和娜娜年龄和部门一样的员工
分析1:先查询出来芳芳的和年龄和部门以及娜娜的年龄和部门
mysql> select age,dept_id from emp where name = "芳芳" or name = "娜娜"; +------+---------+ | age | dept_id | +------+---------+ | 22 | 1 | | 25 | 3 | +------+---------+ 2 rows in set (0.00 sec)
说明1:这次的查询结果仍然是一个多行多列的临时表
分析2:将上述查询结果当做条件使用
mysql> select * from emp where(age,dept_id) in (select age,dept_id from emp where name="芳芳" or name="娜娜"); +----+--------+------+--------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------+--------+------------+-----------+---------+ | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 4 | 芳芳 | 22 | 开发 | 21000 | 2019-08-18 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | +----+--------+------+--------+--------+------------+-----------+---------+ 5 rows in set (0.00 sec)
案例2:查询入职时间是“2020-01-01”之后的员工信息及部门信息
分析1:先查询入职时间是“2020-01-01”之后的员工信息
mysql> select * from emp where entrydate > "2020-01-01"; +----+--------+------+--------+--------+------------+-----------+---------+ | id | name | age | job | salary | entrydate | managerid | dept_id | +----+--------+------+--------+--------+------------+-----------+---------+ | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | | 8 | 静静 | 27 | 人事 | 5000 | 2021-07-11 | 1 | NULL | +----+--------+------+--------+--------+------------+-----------+---------+ 5 rows in set (0.00 sec)
分析2:在查询这部分员工对应的部门信息
mysql> select e.*, d.* from (select * from emp where entrydate > "2020-01-01") as e left join dept as d on e.dept_id=d.id; +----+--------+------+--------+--------+------------+-----------+---------+------+-----------+ | id | name | age | job | salary | entrydate | managerid | dept_id | id | name | +----+--------+------+--------+--------+------------+-----------+---------+------+-----------+ | 3 | 问问 | 22 | 开发 | 18000 | 2022-07-20 | 2 | 1 | 1 | 研发部 | | 5 | 珊珊 | 22 | 开发 | 15000 | 2021-04-10 | 3 | 1 | 1 | 研发部 | | 6 | 娜娜 | 25 | 财务 | 24000 | 2023-07-16 | 1 | 3 | 3 | 财务部 | | 7 | 咔咔 | 25 | 出纳 | 8000 | 2021-07-10 | 6 | 3 | 3 | 财务部 | | 8 | 静静 | 27 | 人事 | 5000 | 2021-07-11 | 1 | NULL | NULL | NULL | +----+--------+------+--------+--------+------------+-----------+---------+------+-----------+ 5 rows in set (0.00 sec)
说明1:将自查询的结果当做一张临时表,与其他的表做连接查询
到了这里,关于Mysql基础8-多表查询的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!