Flink Metrics 简介
Flink Metrics 是 Flink 集群运行中的各项指标,包含机器系统指标,比如:CPU、内存、线程、JVM、网络、IO、GC 以及任务运行组件(JM、TM、Slot、作业、算子)等相关指标。
Flink 一共提供了四种监控指标:分别为 Counter、Gauge、Histogram、Meter。
Flink 主动方式共提供了 8 种 Report。
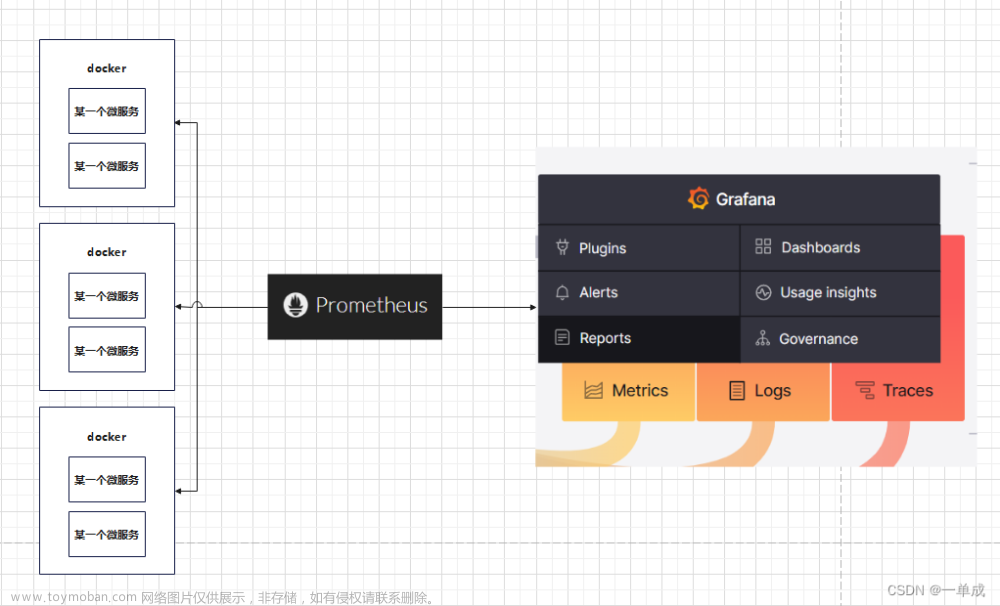
使用 PrometheusPushGatewayReporter 方式 通过 prometheus + pushgateway + grafana 组件搭建 Flink On Yarn 可视化监控。
当 用户 使用 Flink 通过 session 模式向 yarn 集群提交一个 job 后,Flink 会通过 PrometheusPushGatewayReporter 将 metrics push 到 pushgateway 的 9091 端口上,然后使用外部系统 prometheus 从 pushgateway 进行 pull 操作,将指标采集过来,通过 Grafana可视化工具展示出来。
2.1 配置 Reporter
链接:https://pan.baidu.com/s/1Bk0-3zLCK8Tn65QkIwVncw
提取码:qfob

2.1.1 导包
将 flink-metrics-prometheus_2.11-1.13.2.jar 包导入 flink-1.13.2/bin 目录下
2.1.2 配置 Reporter
选取 PrometheusPushGatewayReporter 方式,通过在官网查询 Flink 1.13.2 Metrics 的配置后,在 flink-conf.yaml 设置,配置如下:
latency.metrics.interval: 60
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: IP地址A
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: flink-metrics-ppg
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
#metrics.reporter.promgateway.groupingKey: k1=v1;k2=v2
#metrics.reporter.promgateway.interval: 60 SECONDS2.2 部署 pushgateway
Pushgateway 是一个独立的服务,Pushgateway 位于应用程序发送指标和 Prometheus 服务器之间。
Pushgateway 接收指标,然后将其作为目标被 Prometheus 服务器拉取。可以将其看作代理服务,或者与 blackbox exporter 的行为相反,它接收度量,而不是探测它们。
2.2.1 解压 pushgateway

2.2.2. 启动 pushgateway
进入到 pushgateway-1.4.1 目录下
./pushgateway &查看是否在后台启动成功
ps aux|grep pushgateway2.2.3. 登录 pushgateway webui

2.3 部署 prometheus.2.3. 登录 pushgateway webui
Prometheus(普罗米修斯)是一个最初在 SoundCloud 上构建的监控系统。
2.3.1 解压prometheus-2.30.0

2.3.2 编写配置文件
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['IP地址A:9090']
labels:
instance: 'prometheus'
- job_name: 'linux'
static_configs:
- targets: ['IP地址A:9100']
labels:
instance: 'localhost'
- job_name: 'pushgateway'
static_configs:
- targets: ['IP地址A:9091']
labels:
instance: 'pushgateway'2.3.3 启动prometheus
./prometheus --config.file=prometheus.yml &启动完后,可以通过 ps 查看一下端口
ps aux|grep prometheus2.3.4 登录prometheus webui

2.4 部署 grafana
Grafana 是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示
2.4.1 解压grafana-8.1.5

2.4.2 启动grafana-8.1.5
./bin/grafana-server web &2.4.3 登录 grafana
登录用户名和密码都是 admin

grafana 配置中文教程:
Prometheus data source | Grafana documentation
2.4.4 配置数据源、创建系统负载监控
要访问 Prometheus 设置,请将鼠标悬停在配置(齿轮)图标上,然后单击数据源,然后单击 Prometheus 数据源,根据下图进行操作。

操作完成后,点击进行验证。

2.4.5 添加仪表盘
点击最左侧 + 号,选择 DashBoard,选择新建一个 pannel


至此,Flink 的 metrics 的指标展示在 Grafana 中了
使用 Lateny marker,所有需要在 flink-conf.yaml 配置参数
latency.metrics.interval
系统配置截图如下:

全链路吞吐计算方式 :
全链路吞吐 = 单位时间处理数据数量 单位时间
提交任务到Flink on Yarn集群
# -m jobmanager 的地址
# -yjm 1024 指定 jobmanager 的内存信息
# -ytm 1024 指定 taskmanager 的内存信息
bin/flink run \
-t yarn-per-job -yjm 4096 -ytm 8800 -s 96 \
--detached -c com.threeknowbigdata.datastream.XgboostModelPrediction \
examples/batch/WordCount.jar \
输入14911,点击Load
这个14911是一个其他人发布的一个Dashboard。这个id是从Grafana官方提供的Dashboard网站 https://grafana.com/grafana/dashboards/ 里找到的。以后要添加其他类型的比如flink或者mysql监控报表,都可以从这个网站找到。
如果成功就可以看到如下界面,默认都是折叠的文章来源:https://www.toymoban.com/news/detail-592000.html
 文章来源地址https://www.toymoban.com/news/detail-592000.html
文章来源地址https://www.toymoban.com/news/detail-592000.html
到了这里,关于Flink Metrics监控 pushgateway搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!