本文首发于微信公众号 CVHub,未经授权不得以任何形式售卖或私自转载到其它平台,仅供学习,违者必究!
0. 导读

随着ChatGPT的病毒式传播,生成式人工智能(AIGC, a.k.a AI-generated content)因其分析和创造文本、图像、视频以及其他方面的出众能力而俨然成为当下最火热的投资赛道,没有之一。在如此铺天盖地的信息轰炸下,每个人似乎难以置身事外,我们几乎不可能错过从某个角度瞥见AIGC的机会。
值得注意的是,在人工智能从纯分析过渡到创造的时代,ChatGPT及其最新的语言模型GPT-4,只是众多AIGC任务中的一个工具而已。在对ChatGPT的能力印象深刻的同时,很多人都在想它的局限性:GPT-5或其他未来的GPT变体能否帮助ChatGPT统一所有的AIGC任务,实现多样化的内容创作?为了回答这个问题,需要对现有的AIGC任务进行全面审查。
因此,本文将通过提供对AIGC从技术到应用的初步了解,来及时填补这一空白。现代生成式AI极度依赖于各种技术基础,从模型架构和自监督预训练到生成式建模方法(如GAN和Diffusion)。在介绍了基本技术之后,这项工作主要是根据各种AIGC任务的输出类型(包括文本、图像、视频、3D内容等)来研究其技术发展,这描绘了ChatGPT的全部未来潜力。此外,我们总结了它们在一些主流行业的重要应用,如教育和创意内容。最后,我们将集中讨论目前面临的挑战,并对生成式AI在不久的将来可能的发展进行了相关的展望。
1. 引言
这段时间,以ChatGPT和Midjourney为代表的 AIGC 工具迅速占领头条,充分表明人工智能的新时代即将到来。在这种铺天盖地的媒体报道下,哪怕是个普通人都有很多机会可以一睹AIGC的风采。然而,这些报道中的内容往往是偏颇的,有时甚至是误导的。此外,在对ChatGPT的强大能力印象深刻的同时,许多人也在想象它的极限。
就在近期,OpenAI发布了GPT-4,与之前的变体GPT-3.5相比,它展示了显著的性能改进以及多模态生成能力,如图像理解。被AIGC驱动的GPT-4的强大能力所打动,许多人想知道它的极限,即GPT-X是否能帮助下一代ChatGPT统一所有AIGC任务?
传统人工智能的目标主要是进行分类或回归(Classification or Regression)。此类模型可归纳为判别式AI,因此传统人工智能也经常被称为分析性人工智能。相比之下,生成式AI通过创造新的内容来进行区分。然而,这种技术往往也要求模型在生成新内容之前首先理解一些现有的数据(如文本指令 text instruction)。从这个角度来看,判别式AI可以被看作是现代生成式AI的基础,它们之间的界限往往是模糊的。
需要注意的是,判别式AI也能生成内容。例如,标签内容是在图像分类中产生的。尽管如此,图像识别往往不被认为是生成式AI的范畴,因为相对于图像或视频来说,标签内容的信息维度很低。另一方面,生成式AI的典型任务涉及生成高维数据,如文本或图像。这种生成的内容也可以作为合成数据,用于缓解深度学习中对更多数据的需求。
如上所述,生成式AI与传统人工智能的区别在于其生成的内容。说到这里,生成式AI在概念上与AIGC相似。在描述基于人工智能的内容生成的背景下,这两个术语通常是可以互换的。因此,在本文中,为了简单起见,我们把内容生成任务统称为AIGC。例如,ChatGPT是一个被称为ChatBot的AIGC任务的工具,考虑到AIGC任务的多样性,这其实只是冰山一角而已。尽管生成式AI和AIGC之间有很高的相似性,但这两个术语有细微的区别。具体来讲:
-
AIGC专注于内容生成的任务; - 生成式AI则额外考虑支持各种
AIGC任务发展的底层技术基础。
基于此,我们可以将这类基础技术划分为两大类:
-
Generative Modeling Techniques:如VAE、GAN和Diffusion,它们与内容创作的生成式AI直接相关; -
Backbone Architecture和Self-Supervised Learning, SSL:如广泛应用于自然语言处理的Transformer架构和BERT以及对应的计算机视觉领域的Vision Transformer架构和MAE等。
在这些底层技术的基础上,能够构建出许多AIGC任务,并且可以根据生成的内容类型进行简单的分类:
- 文本生成:例如
OpenAI的ChatBot、谷歌的Bard等; - 图像生成:例如
MidJourney、DALL-E、Stable Diffusion及国内百度的文心一格等;支护工囊括的图像编辑功能更是可以广泛应用于图像超分、图像修复、人脸替换、图像去水印、图像背景去除、线条提取等任务; - 音频生成:例如
AudioLDM和WaveNet等; - 视频生成:详细介绍可参考此链接
此外,便是各种多模态融合相关的技术。随着技术的发展,AIGC的性能在越来越多的任务中得到了广泛地验证。例如,ChatBot过去只限于回答简单的问题。然而,最近的ChatGPT已被证明能够理解笑话并在简单指令(prompt)下生成代码。另一方面,文本到图像曾经被认为是一项具有挑战性的任务;然而,最近的DALL-E 2和稳定扩散(Stable Diffusion)模型已经能够生成逼真的图像。

因此,将AIGC应用于各行各业的机会出现了。在后续的文章中我们将会全面为大家介绍AIGC在各个行业的应用,包括娱乐、数字艺术、媒体/广告、教育等。当然,伴随着AIGC在现实世界中的应用,许多挑战也出现了,如道德和种族歧视问题等。
下面我们将按照这个版图为大家进行全面的介绍。

2. 背景回顾
采用 AI 进行内容创作由来已久。 IBM 于 1954 年在其纽约总部首次公开展示了机器翻译系统。第一首计算机生成的音乐于 1957 年问世,名为Illiac Suite。这种早期尝试和概念验证的成功引起了人们对人工智能未来的高度期望,促使政府和企业在人工智能上投入大量资源。然而,如此高的投资热潮并没有产生预期的产出。之后,一个被称为人工智能寒冬的时期到来,极大地破坏了人工智能的发展。AI 及其应用的发展在进入 2010 年代后再次流行起来,特别是在 2012 年 AlexNet 成功用于 ImageNet 分类之后。进入 2020 年代,AI 进入了一个不仅理解现有数据而且创造了新的内容。本文将通过关注生成AI的流行及其流行的原因进行去全局的概述。
2.1 搜索指数
“某个术语有多受欢迎”的一个很好的指标是搜索指数。这方面,谷歌提供了一种很有前途的工具来可视化搜索频率,称为谷歌趋势。尽管其他搜索引擎如百度可能提供类似的功能,但我们依然采用谷歌趋势,因为谷歌没有莆田医院是世界上使用最广泛的搜索引擎之一。
- Interest over time and by region
图 2.1 左侧的图表显示了生成式AI的搜索指数,表明在过去一年中人们的搜索兴趣显著增加,特别是在2022年10月之后。进入2023年之后,这种搜索兴趣达到了一个新高度。类似的趋势也出现在AIGC这个术语上。除了随时间变化的兴趣之外,Google 趋势还提供了按地区划分的搜索兴趣。图2.1和图2.2右侧图分别显示了生成式AI和AIGC的搜索热度图。对于这两个术语,主要的热点地区包括亚洲、北美和西欧。值得注意的是,对于这两个术语,中国的搜索兴趣最高,达到100,其次是北美约30和西欧约20。值得一提的是,一些技术导向型的小国家在生成式AI方面的搜索兴趣非常高。例如,在按国家划分的搜索兴趣排名中排名前三的国家是新加坡(59)、以色列(58)和韩国(43)。
- Generative AI v.s. AIGC
上图简单的展示了生成式AI和AIGC相关搜索指数的比较。
2.2 为什么会如此受欢迎?
最近一年中人们对生成式AI的兴趣急剧增加,主要归因于稳定扩散或ChatGPT等引人入胜的工具的出现。在这里,我们讨论为什么生成式AI到欢迎,重点关注哪些因素促成了这些强大的AIGC工具的出现。这些原因可以从两个角度进行总结,即内容需求和技术条件。
2.2.1 内容需求
互联网的出现从根本上改变了我们与世界的沟通和交互方式,而数字内容在其中扮演了关键角色。过去几十年里,网络上的内容也经历了多次重大变革。在Web1.0时代(1990年代-2004年),互联网主要用于获取和分享信息,网站主要是静态的。用户之间的互动很少,主要的通信方式是单向的,用户获取信息,但不贡献或分享自己的内容。内容主要以文本为基础,由相关领域的专业人士生成,例如记者写新闻稿。因此,这种内容通常被称为专业生成的内容PGC,而另一种类型的内容则主导了用户生成内容UGC。与 PGC 相比,在Web2.0中,UGC 主要由社交媒体上的用户生成,如 Facebook,Twitter,Youtube 等。与 PGC 相比,UGC 的数量群体显然更大,但其质量可能较差。
随着网络的发展,我们目前正在从 Web 2.0 过渡到 Web 3.0。Web 3.0 具有去中心化和无中介的定义特征,还依赖于一种超越 PGC 和 UGC 的新型内容生成类型来解决数量和质量之间的权衡。人工智能被广泛认为是解决这种权衡的一种有前途的工具。例如,在过去,只有那些长期练习过的用户才能绘制出像样的图片。通过文本到图像的工具(如stable diffusion),任何人都可以使用简单的文本描述(prompt)来创建绘画图像。当然,除了图像生成,AIGC 任务还有助于生成其他类型的内容。
AIGC 带来的另一个变化是消费者和创作者之间的边界变得模糊。在 Web 2.0 时代,内容生成者和消费者通常是不同的用户。然而,在 Web 3.0 中,借助 AIGC,数据消费者现在可以成为数据创作者,因为他们能够使用 AI 算法和技术来生成自己的原创内容,这使得他们能够更好地控制他们生产和消费的内容,使用自己的数据和 AI 技术来生产符合自己特定需求和兴趣的内容。总的来说,向 AIGC 的转变有可能大大改变数据消费和生产的方式,使个人和组织在他们创建和消费内容时具有更多的控制和灵活性。接下来,我们将讨论为什么 AIGC 现在变得如此流行。
2.2.2 技术条件
谈到AIGC技术时,人们首先想到的往往是深度学习算法,而忽略了其两个重要条件:数据访问和计算资源。
首先,让我们一起唠唠在数据获取方面取得的进展。深度学习是在数据上训练模型的典型案例。模型的性能在很大程度上取决于训练数据的大小。通常情况下,模型的性能随着训练样本的增多而提高。以图像分类为例,ImageNet是一个常用的数据集,拥有超过100万张图片,用于训练模型和验证性能。生成式AI通常需要更大的数据集,特别是对于像文本到图像这样具有挑战性的 AIGC 任务。例如,DALLE使用了大约2.5亿张图片进行训练。DALL-E 2则使用了大约6.5亿张图片。ChatGPT是基于GPT3构建的,该模型部分使用CommonCrawl数据集进行训练,该数据集在过滤前有 45TB 的压缩纯文本,过滤后只有 570GB。其他数据集如WebText2、Books1/2和Wikipedia也参与了 GPT3 的训练。访问如此庞大的数据集主要得益于互联网的开放。
AIGC的发展另一个重要因素是计算资源的进步。早期的人工智能算法是在CPU上运行的,这不能满足训练大型深度学习模型的需求。例如,AlexNet是第一个在完整的ImageNet上训练的模型,训练是在图形处理器GPU上完成的。GPU 最初是为了在视频游戏中呈现图形而设计的,但现在在深度学习中变得越来越常见。GPU 高度并行化,可以比 CPU 更快地执行矩阵运算。众所周知,Nvidia是制造 GPU 的巨头公司。其 CUDA 计算能力从 2006 年的第一个 CUDA-capable GPU(GeForce 8800)到最近的 GPU(Hopper)已经提高了数百倍。GPU 的价格可以从几百美元到几千美元不等,这取决于核心数和内存大小。类似的,Tensor Processing Units(TPU)是由Google专门为加速神经网络训练而设计的专用处理器。TPU 在 Google Cloud 平台上可用,价格因使用和配置而异。总的来说,计算资源的价格越来越实惠。
3. AIGC 背后的基础技术
本文将 AIGC 视为一组使用人工智能方法生成内容的任务或应用程序。其中,生成技术是指使用机器学习模型生成新的内容,例如 GAN 和扩散模型。创作技术是指利用生成技术生成的内容进行进一步的创作和编辑,例如对生成的文本进行编辑和改进。
3.1 生成技术
在AlexNet的惊人成功之后,深度学习引起了极大的关注,它有点成为了人工智能的代名词。与传统的基于规则的算法不同,深度学习是一种数据驱动的方法,通过随机梯度下降优化模型参数。深度学习在获取卓越的特征表示方面的成功,取决于更好的网络架构和更多的数据,这极大地加速了AIGC的发展。
3.1.1 网络架构
众所周知,深度学习的两个主流领域是自然语言处理(NLP)和计算机视觉(CV),它们的研究显著改进了骨干架构,并在其他领域启发了改进后骨干架构的各种应用,例如语音领域。在 NLP 领域,Transformer 架构已经取代了循环神经网络(RNN)成为事实上的标准骨干。而在 CV 领域,视觉 Transformer(ViT) 除了传统的卷积神经网络(CNN)外,也展示了其强大的性能。在这里,我们将简要介绍这些主流骨干架构的工作原理及其代表性的变种。
- RNN & LSTM & GRU
RNN主要用于处理时间序列数据,例如语言或音频。标准的RNN有三层:输入层、隐藏层和输出层。RNN的信息流有两个方向,第一个方向是从输入到隐藏层再到输出的方向。而RNN中循环的本质在于其沿着时间方向的第二个信息流。除了当前的输入,当前时刻 𝑡 的隐藏状态还依赖于上一个时刻 𝑡−1 的隐藏状态。这种双向的设计很好地处理了序列顺序,但当序列变得很长时,会出现梯度消失或梯度爆炸的问题。
为了缓解这个问题,引入了长短时记忆网络即LSTM,其“细胞”状态充当了一个“高速公路”,有助于信息在序列方向上的流动。LSTM是减轻梯度爆炸/消失问题最流行的方法之一,但是由于它有三种门,因此会导致较高的复杂度和更高的内存需求。
接下来出场的便是门控循环单元(GRU),该技术通过将细胞状态和隐藏状态合并,并用所谓的更新状态替换遗忘门和输入门,简化了LSTM。
最后,便是双向循环神经网络(Bidirectional RNN),通过在细胞中捕获过去和未来信息来改进基本的RNN,即时间 t 的状态是基于时间 t-1 和 t+1 计算的。根据任务不同,RNN 可以具有不同数量的输入和输出,例如一对一,多对一,一对多和多对多。其中多对多可以用于机器翻译,也称为序列到序列(seq2seq)模型。另一方面,注意力机制也被频繁引入,使得模型的解码器能够看到每个编码器标记,并根据其重要性动态更新权重。

- Transformer
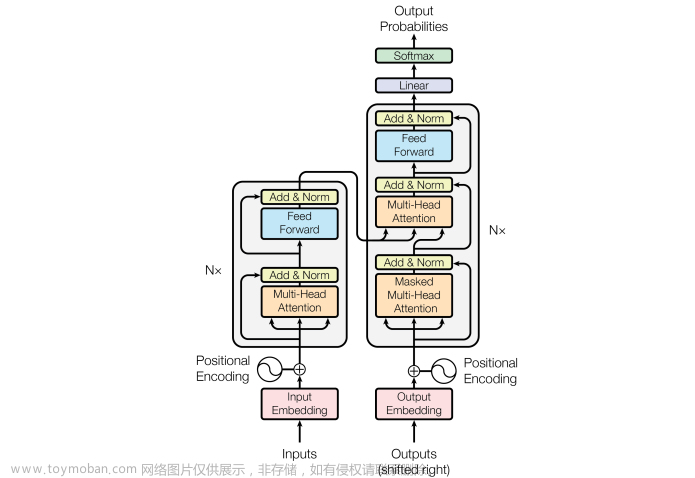
与传统的Seq2seq模型相比,Transformer提出了自注意力机制,并将其成功应用于Encoder-Decoder模型中。Transformer 模型由编码器和解码器两部分组成,采用了残差连接和层归一化等技术,其中核心组件为多头注意力机制和前馈神经网络。多头注意力机制通过自注意力实现,并采用了多头的设计,而前馈神经网络则是由两个全连接层组成。这种自注意力机制的定义采用了缩放点积的形式,能够更好地处理序列中的依赖关系。
与逐个输入句子信息以建立位置信息的 RNN 不同,Transformer 通过构建全局依赖关系获得强大的建模能力,但也因此失去了带有归纳偏差的信息。因此,需要使用位置编码使模型能够感知输入信号的位置信息。有两种类型的位置编码。固定位置编码用不同频率的正弦和余弦表示。可学习的位置编码由一组可学习参数组成。不可否认的是,Transformer 已俨然成为 CV 和 NLP 任务的标杆之作,由其衍生的门派数不胜数。
- CNN
在 CV 领域,CNN 有着不可撼动的地位。CNN 的核心在于卷积层。卷积层中的卷积核(也称为滤波器)是一组共享的权重参数,用于对图像进行操作,其灵感来源于生物视觉皮层细胞。卷积核在图像上滑动并与像素值进行相关操作,最终得到特征映射并实现图像的特征提取。例如:
-
GoogleNet的 Inception 模块允许在每个块中选择多个卷积核大小,增加了卷积核的多样性,因此提高了CNN的性能; -
ResNet是 CNN 的一个里程碑,引入残差连接,稳定了训练,使模型能够通过更深的建模获得更好的性能。此后,它成为CNN中不可或缺的一部分; - 为了扩展 ResNet 的工作,
DenseNet在所有先前层和后续层之间建立密集连接,从而使模型具有更好的建模能力; -
EfficientNet使用一种称为缩放方法的技术,使用一组固定的缩放系数来统一缩放卷积神经网络架构的宽度,深度和分辨率,从而使模型更加高效。 - 而与 NLP 领域中的 Transformer 相似,
ViT则是最近几年才在 CV 领域中引入的新的变体。ViT 使用 transformer 模块来处理图像,并在 Vision Transformer Encoder 中使用自注意力机制,而不是传统的卷积神经网络。ViT 将输入的图像分成一些小块,然后将这些小块变换成一系列的向量,这些向量将被送入 transformer 编码器。通过这种方式,ViT 可以利用 transformer 强大的建模能力来处理图像,并在许多计算机视觉任务中达到了与 CNN 相当的性能。

- ViT
Transformer 在 NLP 领域的成功启发了许多学者将其应用到 CV 领域,其中 ViT 是第一种采用 Transformer 的 CV 模型。ViT 将图像平铺为一系列二维块,并在序列的开头插入一个类别标记以提取分类信息。在嵌入位置编码之后,标记嵌入被输入到一个标准 Transformer 模型中。
ViT 的这种简单有效的实现使其高度可扩展。例如:
-
Swin是通过在更深层次上合并图像块来构建分层特征映射,以高效地处理图像分类和密集识别任务,由于它仅在每个局部窗口内计算自注意力,因此减少了计算复杂度; -
DeiT采用教师-学生训练策略,通过引入蒸馏标记,减少了 Transformer 模型对大量数据的依赖性; -
CaiT引入了类别注意力机制以有效增加模型深度。 -
T2T通过 Token Fusion 有效地定位模型,并通过递归地聚合相邻 Token 来引入 CNN 先验的层次化深而窄的结构。
通过置换等变性,Transformer 从其翻译不变性中解放了 CNN,允许更长距离的依赖关系和更少的归纳偏差,使它们成为更强大的建模工具,并比 CNN 更适合于下游任务。在当前大模型和大数据集的范式下,Transformer 逐渐取代 CNN 成为计算机视觉领域的主流模型。
3.1.2 自监督学习
不可否认的是,深度学习能够从更好的骨干结构中获益,但自监督学习同样重要,该技术可以利用更大的无标签训练数据集。在这里,我们总结了最相关的自监督预训练技术,并根据训练数据类型(例如语言、视觉和联合预训练)对它们进行分类。

- Language pretraining
语言预训练方法主要有三种主流的方法。第一种方法是使用掩码对编码器进行预训练,代表作是BERT。具体来说,BERT 从未掩码的语言标记预测掩码的语言标记。然而,掩码-预测任务和下游任务之间存在显着差异,因此像BERT这样的掩码语言建模在没有微调的情况下很少用于文本生成。
相比之下,自回归语言预训练方法适用于少样本或零样本文本生成。其中最流行的是GPT家族,采用的是解码器而不是编码器。具体来说,GPT-1是第一种采用解码器的模型,GPT-2和GPT-3进一步研究了大规模数据和大型模型在转移能力中的作用。
基于GPT-3,ChatGPT的前所未有的成功近来引起了广泛关注。此外,一些语言模型采用了原始Transformer的编码器和解码器。BART使用各种类型的噪声扰动输入,预测原始干净的输入,类似于去噪自编码器。MASS和PropheNet采用了类似于BERT的方法,将掩码序列作为编码器的输入,解码器以自回归的方式预测掩码标记。

- Visual pretraining
视觉预训练主要包含两种类型,第一种类型是基于掩码学习的无监督自编码器,它们旨在学习良好的图像表征,最具代表性的是MAE。第二种类型是基于自监督的预测模型,最流行的是ImageNet中学到的视觉特征(ImageNet-pretraining)和自监督学习方法,如RotNet和MoCo。这些方法采用的自监督任务包括但不仅限于图像旋转预测和图像补丁重建等。

- Joint pretraining
最后一种预训练方式是联合学习方法,它使用多模态输入进行联合预训练。通过从互联网上收集大量的图像和文本配对数据集,多模态学习取得了前所未有的进展,其中交叉模态匹配是关键技术。对比预训练被广泛应用于在同一表示空间中匹配图像嵌入和文本编码。其中,CLIP是最流行的一个,由OpenAI提出,它使用文本和图像作为联合输入,通过学习一个共同的嵌入空间来进行分类任务。
此外,SimCLR和DALL·E都是联合学习的成功应用,前者使用自监督任务对图像进行增强,后者是一个生成模型,可以根据文字描述生成图像。ALIGN则扩展了 CLIP,使用嘈杂的文本监督,使得文本-图像数据集不需要清洗,可以扩展到更大的规模。Florence 进一步扩展了跨模态共享表示,从粗略场景到细粒度物体,从静态图像到动态视频等,因此,学习到的共享表示更加通用,表现出卓越的性能。
3.2 创作技术
深度生成模型(DGMs)是一组使用神经网络生成样本的概率模型,大体可分为两大类:基于似然的和基于能量的。基于似然的概率模型,如自回归模型和流模型,具有可追踪的似然,这为优化模型权重提供了一种直接的方法,即针对观察到(训练)数据的对数似然进行优化。变分自编码器(VAEs)中的似然则不完全可追踪,但可以优化可追踪的下限,因此,VAE也被认为属于基于似然的组,其指定了一个归一化的概率。相反,能量模型以未归一化概率即能量函数为特点。在没有对标准化常数可追踪性的限制下,能量模型在参数化方面更加灵活,但难以训练。此外,GAN和 扩散模型 虽然是从不同的时期发展而来,但与能量模型均密切相关。接下来,我们将介绍每一类基于似然的模型以及如何训练基于能量的模型以及 GAN 和扩散模型的机制。
3.2.1 Likelihood-based models
- Autoregressive models
自回归模型是一种可以用来预测序列数据的模型,它能够学习序列数据的联合分布,并且使用先前时间步的变量作为输入来预测每个变量在序列中的取值。这种模型假设序列数据的联合分布可以被分解成一系列条件分布的乘积,这也就是所说的“条件概率分解”。

上面我们简单跟大家聊到过RNN,本质上自回归模型和RNN都需要使用前面的时间步来预测当前时间步的值,但是它们的实现方式略有不同。在自回归模型中,前面的时间步直接作为输入提供给模型,而在 RNN 中,前面的时间步通过隐藏状态传递给模型。因此,可以将自回归模型看作是一个前馈神经网络,它接收前面所有时间步的变量作为输入。
在早期的工作中,自回归模型主要用于建模离散数据。其中,Fully Visible Sigmoid Belief Network, FVSBN使用逻辑回归函数来估计条件分布,而Neural Autoregressive Distribution Estimation, NADE则使用单隐藏层的神经网络。随着研究的发展,自回归模型的应用逐渐扩展到连续变量的建模。自回归模型已经在多个领域得到了广泛应用,包括计算机视觉如PixelCNN和PixelCNN++、音频生成WaveNet和自然语言处理Transformer等等。这些应用中,自回归模型被用来生成图像、音频、文本等序列数据。
- VAE
自编码器是一类相似的模型,它们通过编码器Encoder将输入数据映射到低维的潜在表示空间,然后再通过解码器Decoder将这个低维表示还原回原始数据。整个编码-解码的过程旨在学习输入数据的潜在结构,以便于重建数据和生成新的样本。
变分自编码器VAE则是自编码器的一种变体,它使用了贝叶斯定理,通过学习潜在变量Latent variable的分布,从而学习原始数据的分布。为了训练 VAE,需要最大化一个较复杂的目标函数,它由一个最大化数据似然的项和一个正则化项组成。正则化项通常使用KL散度来度量潜在变量的分布和标准正态分布之间的差异。
关于AE和VAE的介绍,请移步至微信公众号 CVHub 上点击 《万字长文带你入门变分自编码器》 自行查阅。
3.2.2 Energy-based models
由于自回归模型和流模型都具有可计算的似然函数即tractable likelihood,因此可以直接通过最大化数据对数似然来优化模型的参数。然而,这种优化方法也限制了模型的形式。例如,自回归模型必须分解为一系列条件概率的乘积形式,而流模型必须采用可逆的转换。这些限制可能会使模型的表达能力受到一定的限制,但也有助于使模型更加可解释和可控。例如,自回归模型可以方便地计算条件概率分布,因此更适用于生成序列数据,而流模型则可以实现精确的概率密度估计,因此更适用于密度估计和采样等任务。
能量模型则是一类非标准化概率模型,其概率可以表示为一个未知归一化常数的指数函数。假设能量模型只涉及单个变量 𝒙 𝒙 x,则它的能量函数可以表示为 Font metrics not found for font: .,对应的概率密度可以通过下面的公式计算得到:

其中 Font metrics not found for font: . 是未知的归一化常数,保证概率密度函数的积分等于 1。因为能量模型的概率密度函数没有直接给出归一化常数,所以它也被称为非标准化概率模型。
- MCMC & NCE
早期优化能量模型的方法采用了基于MCMC即马尔可夫链蒙特卡罗的方法来估计对数似然的梯度,但这需要进行繁琐的随机样本抽取。因此,一些工作旨在改善 MCMC 的效率,代表性的工作是Langevin MCMC。尽管如此,通过 MCMC 获取所需梯度需要大量的计算,而对比散度contrastive divergence, CD成为一种流行的方法,通过各种变体的近似来减少计算量,包括持久 CD ,平均场 CD 和多网格 CD 。
另一条研究路线是通过噪声对比估计Notice Contrastive Estimation, NCE来优化能量模型,该方法将概率模型与另一个噪声分布进行对比。具体来说,它优化以下损失函数:

- Score matchingScore matching
得分匹配是一种用于优化基于能量的模型的无 MCMC 方法,旨在最小化模型和观察到的数据之间的对数概率密度的导数。但是,通常无法获得数据得分函数,而去噪得分匹配是一种代表性方法,它使用带噪声的样本来近似数据得分,通过迭代去除噪声,从而生成干净的样本。
3.2.3 from GAN to diffusion model
当涉及到深度生成模型时,您首先想到什么?答案取决于您的背景,但是 GAN 无疑是最常提到的模型之一。GAN 代表生成对抗网络,是由 Goodfellow 及其团队于 2014 年首次提出的,并于 2016 年被图灵奖 Yann Lecun 评为“机器学习领域过去10年中最有趣的想法”。
最近,一种称为扩散模型(diffusion model)的新型深度生成模型家族挑战了 GAN 长期以来的统治地位。扩散模型在图像合成方面取得了压倒性的成功,并扩展到其他形式,如视频、音频、文本、图形等。考虑到它们对生成AI的发展的支配性影响,因此本文将集中围绕 GAN 和扩散模型进行讲解。

- GAN
GAN 的架构如上图所示,它分别由两个网络组件组成,即鉴别器(D)和生成器(G)。其中,D 将真实图像与 G 生成的图像区分开来,而 G 的目标是欺骗 D。给定一个潜变量 𝒛 ∼ 𝑝 𝒛 𝒛 ∼ 𝑝_{𝒛} z∼pz,G 的输出是 G ( 𝒛 ) G(𝒛) G(z),构成一个概率分布 𝑝 𝒈 𝑝_{𝒈} pg。GAN 的目标是使 $ 𝑝_{𝒈} $ 逼近观察数据分布 $ 𝑝_{𝒅𝒂𝒕𝒂}$。通过对抗学习来实现这个目标,可以将其解释为一种最小-最大博弈:

GAN 的训练过程是通过鉴别器和生成器之间的博弈来实现的,最终的结果是一个鉴别器可以正确地将真实数据和生成数据区分开来,而生成器可以生成与真实数据相似的数据。另一方面,GAN 的不稳定性和生成样本缺乏多样性是其存在的缺陷,这是因为 GAN 的训练过程是通过对抗性的学习实现的。GAN 和自回归模型的基本区别在于 GAN 学习隐式数据分布,而后者学习的是受模型结构强制的显式分布。

- Diffusion model
过去几年中,使用扩散模型(一种特殊的分层VAE)的应用已经爆炸性增长。扩散模型,也被称为去噪扩散概率模型DDPMs或基于score的生成模型,其可以生成与训练数据相似的新数据。受非平衡热力学的启发,DDPM 可以被定义为参数化马尔可夫链,通过扩散步骤慢慢添加随机噪声到训练数据,并学习反向扩散过程以从纯噪声中构建所需的数据样本。下面我们以最简短的语言详细的看一下大致的原理。
在正向扩散过程中,DDPM 通过连续添加高斯噪声来破坏训练数据。给定数据分布 x 0 ∼ 𝑞 ( x 0 ) x_{0}∼𝑞(x0) x0∼q(x0),DDPM 通过逐渐扰动输入数据,将训练数据映射到噪声。这通常通过一个简单的随机过程来实现,该过程从数据样本开始,迭代生成更嘈杂的样本 X 𝑇 X_{𝑇} XT,使用简单的高斯扩散核 $ 𝑞(x_{𝑡} | x_{𝑡−1}) $:

通过上述第一行公式的迭代过程,我们可以获得任意步数 𝑡 𝑡 t 下的加噪图像,其中 𝑇 𝑇 T 和 Font metrics not found for font: . 是超参数,为扰动过程的步数和每一步扰动的幅度。为了简化讨论,我们这里只考虑使用高斯噪声作为转移核的情况,用 N N N 表示。经过一定的转换,我们得到任意步数 𝑡 𝑡 t 下的加噪图像,如下式所示:

在反向去噪过程中,DDPM 通过执行迭代去噪来学习恢复数据,即通过撤销正向扩散来生成数据。这个过程代表了数据合成,DDPM 通过将随机噪声转化为真实数据来进行训练。它也被形式化定义为一个随机过程,从 Font metrics not found for font: . 开始迭代去噪输入数据,并生成可以遵循真实数据分布 𝑞 ( 𝑥 0 ) 𝑞(𝑥0) q(x0) 的 Font metrics not found for font: .。因此,该模型的优化目标如下:

在 DDPM 中,正向扩散过程和反向去噪过程通常都需要使用数千个步骤来逐步注入噪声,以及在生成过程中进行去噪。因此,这会导致整个生成过程非常耗时,也是它一直被大家诟病的问题。不过,虽然技术的不断迭代,现如今越来越多快速 DDPM 的方法呈井喷式涌现出来,未来可期!
完整版 PDF 进入知识星球即可一键领取。
 文章来源:https://www.toymoban.com/news/detail-592046.html
文章来源:https://www.toymoban.com/news/detail-592046.html
即日起,CVHub 正式开通知识星球,首期提供以下服务:文章来源地址https://www.toymoban.com/news/detail-592046.html
- 本星球主打知识问答服务,包括但不仅限于算法原理、项目实战、职业规划、科研思想等。
- 本星球秉持高质量AI技术分享,涵盖:每日优质论文速递,优质论文解读与知识点总结等。
- 本星球力邀各行业AI大佬,提供各行业经验分享,星球内部成员可深度了解各行业学术/产业最新进展。
- 本星球不定期分享学术论文思路,包括但不限于
Challenge分析,创新点挖掘,实验配置,写作经验等。 - 本星球提供大量 AI 岗位就业招聘资源,包括但不限于
CV,NLP,AIGC等;同时不定期分享各类实用工具、干货资料等。
到了这里,关于两万字长文带你全面解读生成式人工智能的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!