近来,随着ChatGPT和GPT-4模型的不断发展,国内外互联网大厂纷纷推出了自家的大语言模型,例如谷歌的PaLM系列,MetaAI的LLaMA系列,还有国内公司和高校推出的一些大模型,例如百度的文心一言,清华的ChatGLM等模型。几乎隔几天就会有一个全新的大模型发布,但是对于研究者和开发者来讲,可能大家更关心的是在基础大模型训练、微调、推理和部署等实际落地方面上的创新。这就不得不谈到大模型底层的语言建模架构了,现如今,绝大多数大模型的基础架构,仍然使用6年前发表在NeurIPS上的Transformer。
随着模型规模和任务数量的增加,对整个Transformer模型进行微调也变得越来越昂贵。因此很多参数高效的迁移学习方法(Parameter Efficient Transfer Learning,PETL)被提出。本文来自Meta AI,提出了一种基于传统RNN架构的参数高效适应方法REcurrent ADaption(READ),具体来说,READ只需要在基础Transformer旁插入一个小型RNN网络,就可以实现高效的参数微调,模型无需再通过主干Transformer进行反向传播。作者通过一系列实验表明,READ在保持较高质量模型微调效果的同时,可以节省56%的训练显存消耗和84%的GPU使用量。

论文链接:
https://arxiv.org/abs/2305.15348

一、引言
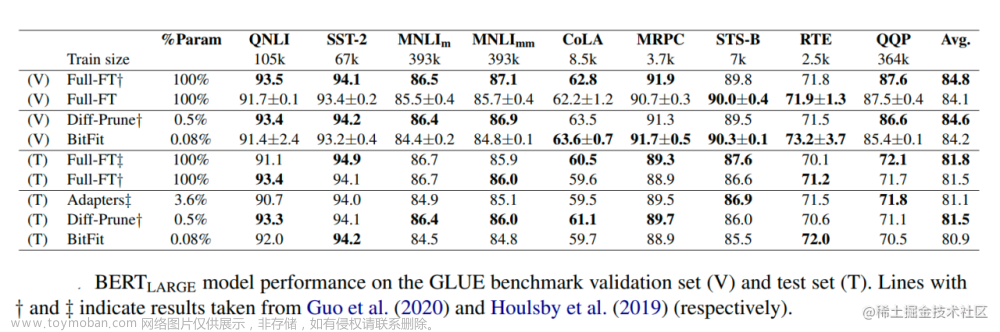
自2018年以来,大语言模型参数规模的增长速度相比GPU显存增长的速度快了近两个数量级,这使得入局大模型的门槛越来越高,配置一个足以放下大模型的“炼丹炉”的成本非常昂贵。只有少数资金的公司和机构才有能力对大模型进行训练和微调。为了降低这一门槛,PETL方法已经成为目前首选的方案,例如Adapter方法[1]通过在Transformer中插入小模块来减少模型需要更新的参数量。Soft Prompts方法[2]在模型输入embeddings后拼接小规模参数来达到类似的效果。还有受到广泛关注的Lora方法[3],通过低秩近似来最小化模型参数量,以及仅微调网络前几层中的偏执项的BitFit方法[4],下表展示了本文提出的READ方法与上述几种方法的微调代价对比结果。

从上表中看出,通过PETL方法的优化,模型的微调的成本相比完全微调已经大大降低。同时本文READ相比其他方法有着明显的优势,这得益于READ内部增加的小型RNN结构,在Transformer架构横行的今天,相对老旧的RNN展现出了强大的生命力。最近一个由华人主导的开源团队也发布了一个基于RNN架构的大语言模型RWKV[5],并且打出了与Transformer“鱼和熊掌兼得”的口号。
二、本文方法
2.1 什么是READ?
本文提出的READ主要由一个标准的RNN和一个Joiner网络组成,READ网络的整体架构如下图所示。


2. 网络在优化过程中只涉及到RNN和前馈网络(FFN),且无需更新Self-Attention层。这提高了模型整体的可用性和训练效率,READ可以在任意的Transformer结构中即插即用。
3. 由于READ的循环网络特性,模型微调的可训练参数规模不随主干网络层数的增加而增加。两者的关系呈次线性增长。
4. READ可以在不修改主干Transformer网络中间结果的情况下进行计算。
2.2 READ如何起作用?





三、实验效果
本文的实验在GLUE基准的多个自然语言任务中进行,采用的基础Transformer架构为T5模型,RNN模型也使用了包含原始RNN,LSTM和GRU等多种循环神经网络结构。
3.1 READ方法在能耗显著较低的情况下表现优于其他方法
下图展示了READ方法与其他PETL方法在GPU能耗降低情况下的性能对比,从下图左半部分我们可以看出,相比全微调(Full-tuning),READ可以将GPU使用量降低90%左右,GPU显存占用降低56%,同时模型的预测精度与原来保持一致。

虽然LoRA、BitFit或Adapter等PETL方法也可以明显减少可训练参数的数量,但它们并不能降低微调的计算成本,而这是PETL的主要优化目标。从上图右半部分我们可以看出,READ在训练过程中使用的显存占用非常小,图中主要展示了模型性能和显存占用之间的性能和空间权衡。与所有其他的baseline方法相比,READ实现了至少25%的训练显存优化,同时实现了更好的下游任务预测性能。


3.2 READ具有很强的可扩展性
如下图所示,与其他PETL方法相比,READ的可训练参数数量增长速度非常缓慢。随着T5骨干模型尺寸的增加,READ的参数数量呈现对数线性增长的趋势。这得益于READ的循环网络性质,使其微调参数规模与骨干网络层数无关,这使得READ在具体的工程实现中更适合于微调超大规模的Transformer模型。

3.3 READ在模型推理速度和显存占用方面也有很大的改进
如下图左半部分所示,READ相比其他PETL方法在模型推理阶段的显存占用更低,且推理速度也保持在一个较高的水平。此外,为了更全面地评估READ的推理显存占用,作者在下图右半部分展示了随着模型骨干网络尺寸的增加,推理显存占用的变化情况,相对于全微调方式,READ的推理显存增长几乎可以忽略不计。

四、总结
本文针对大规模Transformer模型提出了一种全新的高效参数微调方法,称为REcurrent ADaption(READ)。READ方法不仅具有轻量化的特点,还能够在准确性方面与传统微调方法相媲美。READ通过引入RNN+Joiner模块的形式,使网络在微调时无需经过主干Transformer模型,显著降低了模型微调的GPU使用量,最高可以达到84%的节省效果。此外,READ还表现出了极强的扩展性,可以在几乎所有的Transformer结构上即插即用,而无需考虑修改原有模型中复杂的自注意力层。同时相对于全微调方法,READ可以降低56%的训练显存占用,这也进一步降低了深度学习工程师微调大模型的门槛。
参考
[1] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR, 2019
[2] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
[3] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021
[4] Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models, 2022.
[5] Peng B, Alcaide E, Anthony Q, et al. RWKV: Reinventing RNNs for the Transformer Era[J]. arXiv preprint arXiv:2305.13048, 2023.文章来源:https://www.toymoban.com/news/detail-593098.html
作者:seven_文章来源地址https://www.toymoban.com/news/detail-593098.html
到了这里,关于Meta提出全新参数高效微调方案,仅需一个RNN,Transformer模型GPU使用量减少84%!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!