目录
0.xpath最新下载地址和安装教程
1.xpath安装
2.xpath基本使用
3.xpath基本语法
4.实例
(1)xpath解析本地文件
(2)xpath解析服务器响应的数据
①获取百度网站的“百度一下”四个字
②获取站长素材网站情侣图片前十页的图片
0.xpath最新下载地址和安装教程
https://blog.csdn.net/laosao_66/article/details/131752611
1.xpath安装
注意:提前安装xpath插件
(1)打开chrome浏览器
(2)点击右上角小圆点
(3)更多工具
(4)扩展程序
(5)拖拽xpath插件到扩展程序中
(6)如果crx文件失效,需要将后缀修改zip
(7)再次拖拽
(8)关闭浏览器重新打开
(9)ctrl + shift + x
(10)出现小黑框
2.xpath基本使用
xpath解析分为两种
一种是解析本地文件 方法为:etree.parse
另一种是解析服务器响应的数据 (即从response.read().decode('utf-8') 里解析,这种用的多 方法为:etree.HTML()
- (1)安装lxml库 pip install lxml ‐i https://pypi.douban.com/simple
- (2)导入lxml.etree from lxml import etree
- (3)etree.parse() 解析本地文件 html_tree = etree.parse('XX.html')
- (4)etree.HTML() 服务器响应文件 html_tree = etree.HTML(response.read().decode('utf‐8')
- (5)html_tree.xpath(xpath路径)
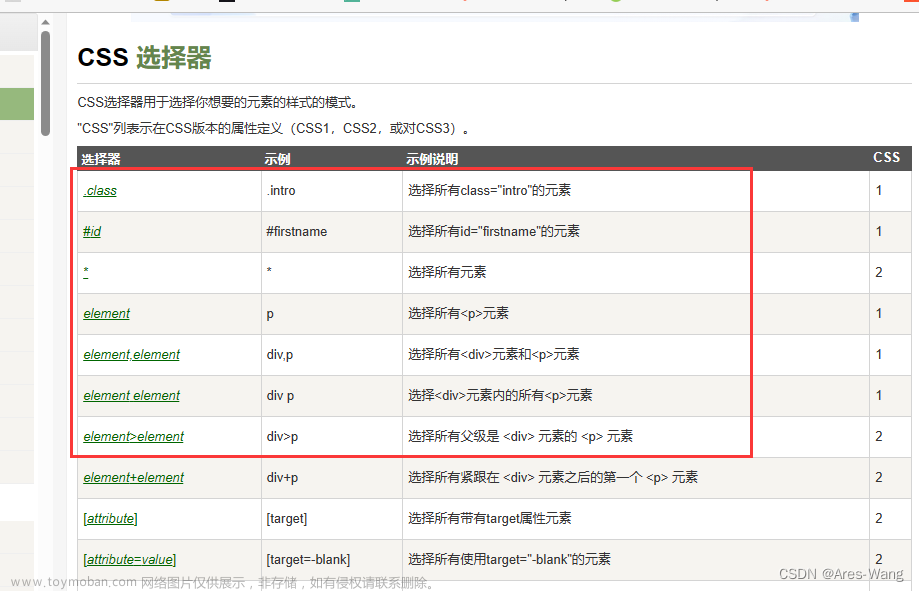
3.xpath基本语法
- 路径查询 //:查找所有子孙节点,不考虑层级关系
- / :找直接子节点
- 谓词查询 //div[@id] //div[@id="maincontent"]
- 属性查询 //@class
- 模糊查询 //div[contains(@id, "he")] //div[starts‐with(@id, "he")]
- 内容查询 //div/h1/text()
- 逻辑运算 //div[@id="head" and @class="s_down"] //title | //price
4.实例
(1)xpath解析本地文件
本地 HTML文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="11" class="c1">北京</li>
<li id="12">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
< ! -- <ul>-->
< ! -- <li>大连</li>-->
< ! -- <li>锦州</li>-->
< ! -- <li>沈阳</li>-->
< ! -- </ul>-->
</body>
</html>
xpath解析本地文件 文章来源:https://www.toymoban.com/news/detail-594969.html
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('爬虫_解析_xpath的基本使用.html')
#tree.xpath('xpath路径')
# 查找ul下面的li
li_list = tree.xpath('//body/ul/li')
# 查找所有有id的属性的li标签
# text()获取标签中的内容
li_list = tree.xpath('//ul/li[@id]/text()')
# 找到id为l1的li标签 注意引号的问题
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 查找到id为l1的li标签的class的属性值
li = tree.xpath('//ul/li[@id="l1"]/@class')
# 查询id中包含l的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查询id的值以l开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
#查询id为l1和class为c1的
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))
(2)xpath解析服务器响应的数据
①获取百度网站的“百度一下”四个字
# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers = headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath的返回值是一个列表类型的数据
result = tree.xpath('//input[@id="su"]/@value')[0]
# 这样写也可以,xpath路径可以在选中区域后右键直接copy
# result = tree.xpath('//*[@id="su"]//@value')[0]
print(result)②获取站长素材网站情侣图片前十页的图片
注:一般涉及图片的网站都会进行懒加载文章来源地址https://www.toymoban.com/news/detail-594969.html
# (1) 请求对象的定制
# (2)获取网页的源码
# (3)下载
# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url = url, headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般涉及图片的网站都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)
到了这里,关于Python爬虫学习笔记(四)————XPath解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!