目录
一、时间语义
1.1 事件时间
1.1.1 在创建表的DDL中定义
1.1.2 在数据流转换为表时定义
1.2 处理时间
1.2.1 在创建表的DDL中定义
二、窗口
2.1 分组窗口(老版本,已经弃用,未来的版本中可能会删除)
2.2 窗口表值函数 (Windowing TVFs,新版本,从1.13起)
2.2.1 滚动窗口(TUMBLE)
2.2.2 滑动窗口(HOP)
2.2.3 累积窗口(ACCUMULATE)
三、聚合
3.1 分组聚合
3.2 窗口聚合
3.3 开窗聚合(Over)
3.4 TopN
3.4.1 普通Top N
3.4.2 窗口TopN
一、时间语义
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在 Table API 和 SQL 中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的DDL 里直接定义为一个字段,也可以在 DataStream 转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。
时间属性的数据类型为TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。
按照时间语义的不同,我们可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
- 处理时间 指的是执行具体操作时的机器时间(大家熟知的绝对时间, 例如 Java的
System.currentTimeMillis()) )- 事件时间 指的是数据本身携带的时间。这个时间是在事件产生时的时间。
- 摄入时间 指的是数据进入 Flink 的时间;在系统内部,会把它当做事件时间来处理。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 或者:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);1.1 事件时间
1.1.1 在创建表的DDL中定义
在创建表的 DDL(CREATE TABLE 语句)中,可以增加一个字段,通过 WATERMARK 语句来定义事件时间属性。WATERMARK 语句主要用来定义水位线(watermark)的生成表达式,这个表达式会将带有事件时间戳的字段标记为事件时间属性,并在它基础上给出水位线的延迟时间。具体定义方式如下:
CREATE TABLE EventTable( user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...这里我们把 ts 字段定义为事件时间属性,而且基于 ts 设置了 5 秒的水位线延迟。这里的“5 秒”是以“时间间隔”的形式定义的,格式是INTERVAL <数值> <时间单位>:
INTERVAL '5' SECOND
这里的数值必须用单引号引起来,而单位用 SECOND 和 SECONDS 是等效的。
Flink 中支持的事件时间属性数据类型必须为TIMESTAMP 或者TIMESTAMP_LTZ。这里TIMESTAMP_LTZ 是指带有本地时区信息的时间戳(TIMESTAMP WITH LOCAL TIME ZONE);一般情况下如果数据中的时间戳是“年-月-日-时-分-秒”的形式,那就是不带时区信息的,可以将事件时间属性定义为TIMESTAMP 类型。
而如果原始的时间戳就是一个长整型的毫秒数,这时就需要另外定义一个字段来表示事件时间属性,类型定义为TIMESTAMP_LTZ 会更方便:
CREATE TABLE events ( user STRING,
url STRING, ts BIGINT,
ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
WATERMARK FOR ts_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);这里我们另外定义了一个字段ts_ltz,是把长整型的 ts 转换为TIMESTAMP_LTZ 得到的;进而使用 WATERMARK 语句将它设为事件时间属性,并设置 5 秒的水位线延迟。
1.1.2 在数据流转换为表时定义
事件时间属性也可以在将DataStream 转换为表的时候来定义。我们调用 fromDataStream() 方法创建表时,可以追加参数来定义表中的字段结构;这时可以给某个字段加上.rowtime() 后缀,就表示将当前字段指定为事件时间属性。这个字段可以是数据中本不存在、额外追加上去的“逻辑字段”,就像之前 DDL 中定义的第二种情况;也可以是本身固有的字段,那么这个字段就会被事件时间属性所覆盖,类型也会被转换为 TIMESTAMP。不论那种方式,时间属性字段中保存的都是事件的时间戳(TIMESTAMP 类型)。
需要注意的是,这种方式只负责指定时间属性,而时间戳的提取和水位线的生成应该之前就在 DataStream 上定义好了。由于 DataStream 中没有时区概念,因此 Flink 会将事件时间属性解析成不带时区的TIMESTAMP 类型,所有的时间值都被当作 UTC 标准时间。
// 方法一:
// 流中数据类型为二元组 Tuple2,包含两个字段;需要自定义提取时间戳并生成水位线
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),
$("ts").rowtime());// 方法二:
// 流中数据类型为三元组 Tuple3,最后一个字段就是事件时间戳
DataStream<Tuple3<String, String, Long>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 不再声明额外字段,直接用最后一个字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),
$("ts").rowtime());1.2 处理时间
相比之下处理时间就比较简单了,它就是我们的系统时间,使用时不需要提取时间戳(timestamp)和生成水位线(watermark)。因此在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
类似地,处理时间属性的定义也有两种方式:创建表 DDL 中定义,或者在数据流转换成表时定义。
1.2.1 在创建表的DDL中定义
在创建表的 DDL(CREATE TABLE 语句)中,可以增加一个额外的字段,通过调用系统内置的 PROCTIME()函数来指定当前的处理时间属性,返回的类型是TIMESTAMP_LTZ。
CREATE TABLE EventTable( user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...这里的时间属性,其实是以“计算列”(computed column)的形式定义出来的。所谓的计算列是 Flink SQL 中引入的特殊概念,可以用一个 AS 语句来在表中产生数据中不存在的列, 并且可以利用原有的列、各种运算符及内置函数。在前面事件时间属性的定义中,将 ts 字段转换成 TIMESTAMP_LTZ 类型的 ts_ltz,也是计算列的定义方式。
二、窗口
有了时间属性,接下来就可以定义窗口进行计算了。我们知道,窗口可以将无界流切割成大小有限的“桶”(bucket)来做计算,通过截取有限数据集来处理无限的流数据。在 DataStream API 中提供了对不同类型的窗口进行定义和处理的接口,而在 Table API 和 SQL 中,类似的功能也都可以实现。
2.1 分组窗口(老版本,已经弃用,未来的版本中可能会删除)
在 Flink 1.12 之前的版本中,Table API 和 SQL 提供了一组“分组窗口”(Group Window)函数,常用的时间窗口如滚动窗口、滑动窗口、会话窗口都有对应的实现;具体在 SQL 中就是调用 TUMBLE()、HOP()、SESSION(),传入时间属性字段、窗口大小等参数就可以了。以滚动窗口为例:
TUMBLE(ts, INTERVAL '1' HOUR)
这里的 ts 是定义好的时间属性字段,窗口大小用“时间间隔”INTERVAL 来定义。
在进行窗口计算时,分组窗口是将窗口本身当作一个字段对数据进行分组的,可以对组内的数据进行聚合。基本使用方式如下:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"TUMBLE_END(ts, INTERVAL '1' HOUR) as endT, " +
"COUNT(url) AS cnt " +
"FROM EventTable " +
"GROUP BY " + // 使用窗口和用户名进行分组
"user, " +
"TUMBLE(ts, INTERVAL '1' HOUR)" // 定义 1 小时滚动窗口
);这里定义了 1 小时的滚动窗口,将窗口和用户 user 一起作为分组的字段。用聚合函数COUNT()对分组数据的个数进行了聚合统计,并将结果字段重命名为cnt;用TUPMBLE_END()函数获取滚动窗口的结束时间,重命名为 endT 提取出来。
分组窗口的功能比较有限,只支持窗口聚合,所以目前已经处于弃用(deprecated)的状态。
2.2 窗口表值函数 (Windowing TVFs,新版本,从1.13起)
窗口表值函数是 Flink 定义的多态表函数(PTF),可以将表进行扩展后返回。表函数(table function)可以看作是返回一个表的函数。
目前 Flink 提供了以下几个窗口TVF:
滚动窗口(Tumbling Windows);
滑动窗口(Hop Windows,跳跃窗口);
累积窗口(Cumulate Windows);
会话窗口(Session Windows,目前尚未完全支持)
窗口表值函数可以完全替代传统的分组窗口函数。窗口 TVF 更符合 SQL 标准,性能得到了优化,拥有更强大的功能;可以支持基于窗口的复杂计算,例如窗口Top-N、窗口联结(window join)等等。当然,目前窗口 TVF 的功能还不完善,会话窗口和很多高级功能还不支持,不过正在快速地更新完善。可以预见在未来的版本中,窗口 TVF 将越来越强大,将会是窗口处理的唯一入口。
在窗口 TVF 的返回值中,除去原始表中的所有列,还增加了用来描述窗口的额外 3 个列: “窗口起始点”(window_start)、“窗口结束点”(window_end)、“窗口时间”(window_time)。起始点和结束点比较好理解,这里的“窗口时间”指的是窗口中的时间属性,它的值等于window_end - 1ms,所以相当于是窗口中能够包含数据的最大时间戳。
在 SQL 中的声明方式,与以前的分组窗口是类似的,直接调用 TUMBLE()、HOP()、CUMULATE()就可以实现滚动、滑动和累积窗口,不过传入的参数会有所不同。下面我们就分别对这几种窗口TVF 进行介绍。
先给出3种窗口的代码,使用datagen作为connetor生产数据:
public class SQLApi14_DataGen {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("create table water_sensor " +
"( " +
" id int, " +
" vc int, " +
" ts as localtimestamp, " +
" watermark for ts as ts " +
")with( " +
" 'connector' = 'datagen', " +
" 'rows-per-second' = '3', " +
//" 'fields.id.kind'='sequence', " +
//" 'fields.id.start'='1', " +
//" 'fields.id.end'='1000', " +
" 'fields.id.min'='1', " +
" 'fields.id.max'='3', " +
" 'fields.vc.min'='1', " +
" 'fields.vc.max'='1000')");
//tableEnv.sqlQuery("select * from water_sensor").execute().print();
//tableEnv.createTemporaryView("source_table",source_table);
//滚动窗口3s聚合一次
Table tumble_window = tableEnv.sqlQuery("" +
"select id, " +
" sum(vc) as sum_vc, " +
" count(*) as cnt, " +
" window_start as stt, " +
" window_end as edt " +
"from table( " +
" tumble(table water_sensor, descriptor(ts), " +
" interval '3' second) " +
" ) " +
"group by id, window_start, window_end");
//tumble_window.execute().print();
//滑动窗口步长3,大小6
Table sliding_window = tableEnv.sqlQuery("" +
"select id, " +
" sum(vc) as sum_vc, " +
" count(*) as cnt, " +
" window_start as stt, " +
" window_end as edt " +
"from table( " +
" hop(table water_sensor, descriptor(ts), " +
" interval '3' second,interval '6' second) " +
" ) " +
"group by id, window_start, window_end");
//sliding_window.execute().print();
//累积窗口,定义了一个统计周期为15s的累积窗口,但每3s输出一次结果
Table cumulate_window = tableEnv.sqlQuery("" +
"select id, " +
" sum(vc) as sum_vc, " +
" count(*) as cnt, " +
" window_start as stt, " +
" window_end as edt " +
"from table( " +
" cumulate(table water_sensor, descriptor(ts), " +
" interval '3' second,interval '15' second) " +
" ) " +
"group by id, window_start, window_end");
cumulate_window.execute().print();
}
}2.2.1 滚动窗口(TUMBLE)
滚动窗口在SQL 中的概念与 DataStream API 中的定义完全一样,是长度固定、时间对齐、无重叠的窗口,一般用于周期性的统计计算。
在 SQL 中通过调用 TUMBLE()函数就可以声明一个滚动窗口,只有一个核心参数就是窗口大小(size)。在 SQL 中不考虑计数窗口,所以滚动窗口就是滚动时间窗口,参数中还需要将当前的时间属性字段传入;另外,窗口 TVF 本质上是表函数,可以对表进行扩展,所以还应该把当前查询的表作为参数整体传入。具体声明如下:
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
这里基于时间字段 ts,对表 EventTable 中的数据开了大小为 1 小时的滚动窗口。窗口会将表中的每一行数据,按照它们 ts 的值分配到一个指定的窗口中。
//滚动窗口3s聚合一次
Table tumble_window = tableEnv.sqlQuery("" +
"select id, " +
" sum(vc) as sum_vc, " +
" count(*) as cnt, " +
" window_start as stt, " +
" window_end as edt " +
"from table( " +
" tumble(table water_sensor, descriptor(ts), " +
" interval '3' second) " +
" ) " +
"group by id, window_start, window_end");2.2.2 滑动窗口(HOP)
滑动窗口的使用与滚动窗口类似,可以通过设置滑动步长来控制统计输出的频率。在 SQL 中通过调用 HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size) 和滑动步长(slide)两个参数。
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
这里我们基于时间属性 ts,在表 EventTable 上创建了大小为 1 小时的滑动窗口,每 5 分钟滑动一次。需要注意的是,紧跟在时间属性字段后面的第三个参数是步长(slide),第四个参数才是窗口大小(size)。
//滑动窗口步长3,大小6
Table sliding_window = tableEnv.sqlQuery("" +
"select id, " +
" sum(vc) as sum_vc, " +
" count(*) as cnt, " +
" window_start as stt, " +
" window_end as edt " +
"from table( " +
" hop(table water_sensor, descriptor(ts), " +
" interval '3' second,interval '6' second) " +
" ) " +
"group by id, window_start, window_end");2.2.3 累积窗口(ACCUMULATE)
滚动窗口和滑动窗口,可以用来计算大多数周期性的统计指标。不过在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。
例如,我们按天来统计网站的 PV(Page View,页面浏览量),如果用 1 天的滚动窗口,那需要到每天 24 点才会计算一次,输出频率太低;如果用滑动窗口,计算频率可以更高,但统计的就变成了“过去 24 小时的 PV”。所以我们真正希望的是,还是按照自然日统计每天的 PV,不过需要每隔 1 小时就输出一次当天到目前为止的 PV 值。这种特殊的窗口就叫作“累积窗口”(Cumulate Window)。

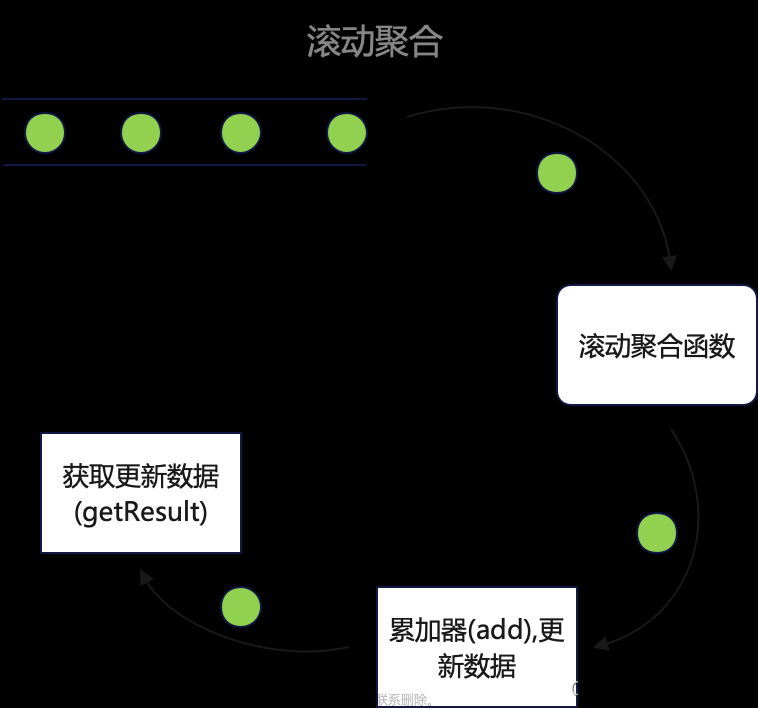
累积窗口是窗口 TVF 中新增的窗口功能,它会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。所谓的最大窗口长度其实就是我们所说的“统计周期”,最终目的就是统计这段时间内的数据。如图 11-8 所示,开始时,创建的第一个窗口大小就是步长 step;之后的每个窗口都会在之前的基础上再扩展 step 的长度,直到达到最大窗口长度。在 SQL 中可以用CUMULATE()函数来定义,具体如下:
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
这里我们基于时间属性 ts,在表 EventTable 上定义了一个统计周期为 1 天、累积步长为 1小时的累积窗口。注意第三个参数为步长 step,第四个参数则是最大窗口长度。
//累积窗口,定义了一个统计周期为15s的累积窗口,但每3s输出一次结果
Table cumulate_window = tableEnv.sqlQuery("" +
"select id, " +
" sum(vc) as sum_vc, " +
" count(*) as cnt, " +
" window_start as stt, " +
" window_end as edt " +
"from table( " +
" cumulate(table water_sensor, descriptor(ts), " +
" interval '3' second,interval '15' second) " +
" ) " +
"group by id, window_start, window_end");
我们会在下一节详细讲解窗口的聚合。
三、聚合
3.1 分组聚合
SQL 中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及 COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于“多对一”的转换。比如我们可以通过下面的代码计算输入数据的个数:
Table eventCountTable = tableEnv.sqlQuery("select COUNT(*) from EventTable");
而更多的情况下,我们可以通过 GROUP BY 子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计。例如之前我们举的例子,可以按照用户名进行分组,统计每个用户点击 url 的次数:
SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user
这种聚合方式,就叫作“分组聚合”(group aggregation)。从概念上讲,SQL 中的分组聚合可以对应 DataStream API 中 keyBy 之后的聚合转换,它们都是按照某个 key 对数据进行了划分,各自维护状态来进行聚合统计的。在流处理中,分组聚合同样是一个持续查询,而且是一个更新查询,得到的是一个动态表;每当流中有一个新的数据到来时,都会导致结果表的更新操作。因此,想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream) 或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成 DataStream 打印输出, 需要调用 toChangelogStream()。
另外,在持续查询的过程中,由于用于分组的 key 可能会不断增加,因此计算结果所需要维护的状态也会持续增长。为了防止状态无限增长耗尽资源,Flink Table API 和 SQL 可以在表环境中配置状态的生存时间(TTL):
TableEnvironment tableEnv = ...
// 获取表环境的配置
TableConfig tableConfig = tableEnv.getConfig();
// 配置状态保持时间
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));或者也可以直接设置配置项 table.exec.state.ttl:
TableEnvironment tableEnv = ...
Configuration configuration = tableEnv.getConfig().getConfiguration(); configuration.setString("table.exec.state.ttl", "60 min");这两种方式是等效的。需要注意,配置 TTL 有可能会导致统计结果不准确,这其实是以牺牲正确性为代价换取了资源的释放。
此外,在 Flink SQL 的分组聚合中同样可以使用 DISTINCT 进行去重的聚合处理;可以使用 HAVING 对聚合结果进行条件筛选;还可以使用GROUPING SETS(分组集)设置多个分组情况分别统计。这些语法跟标准 SQL 中的用法一致,这里就不再详细展开了。
可以看到,分组聚合既是 SQL 原生的聚合查询,也是流处理中的聚合操作,这是实际应用中最常见的聚合方式。当然,使用的聚合函数一般都是系统内置的,如果希望实现特殊需求也可以进行自定义。
3.2 窗口聚合
在 Flink 的 Table API 和 SQL 中,窗口的计算是通过“窗口聚合”(window aggregation)来实现的。与分组聚合类似,窗口聚合也需要调用 SUM()、MAX()、MIN()、COUNT()一类的聚合函数,通过GROUP BY 子句来指定分组的字段。只不过窗口聚合时,需要将窗口信息作为分组 key 的一部分定义出来。在 Flink 1.12 版本之前,是直接把窗口自身作为分组 key 放在GROUP BY 之后的,所以也叫“分组窗口聚合”;而 1.13 版本开始使用了 “窗口表值函数”(Windowing TVF),窗口本身返回的是就是一个表,所以窗口会出现在 FROM后面,GROUP BY 后面的则是窗口新增的字段 window_start 和window_end。
比如,我们将 2.2 中分组窗口的聚合,用窗口TVF 重新实现一下:
SELECT
user,
window_end AS endT,
COUNT(url) AS cnt
FROM TABLE(
CUMULATE(
TABLE EventTable,
DESCRIPTOR(ts),
INTERVAL '30' MINUTE,
INTERVAL '1' HOUR)
)
GROUP BY user, window_start, window_endTable result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " + "COUNT(url) AS cnt " +
"FROM TABLE( " +
"TUMBLE( TABLE EventTable, " + "DESCRIPTOR(ts), " + "INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);这里我们以 ts 作为时间属性字段、基于 EventTable 定义了 1 小时的滚动窗口,希望统计出每小时每个用户点击 url 的次数。用来分组的字段是用户名 user, 以及表示窗口的window_start 和window_end;而 TUMBLE()是表值函数,所以得到的是一个表(Table),我们的聚合查询就是在这个Table 中进行的。
Flink SQL 目前提供了滚动窗口TUMBLE()、滑动窗口 HOP()和累积窗口(CUMULATE) 三种表值函数(TVF)。在具体应用中,我们还需要提前定义好时间属性。下面是一段窗口聚合的完整代码,以累积窗口为例:
import POJO.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
public class CumulateWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTs();
}
})
);
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
);
// 为方便在 SQL 中引用,在环境中注册表 EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 设置累积窗口,执行 SQL 统计查询
Table result = tableEnv.sqlQuery("" +
"SELECT " +
" user, " +
" window_end AS endT, " +
" COUNT(url) AS cnt " +
"FROM TABLE( " +
" CUMULATE( " +
" TABLE EventTable, " +
" DESCRIPTOR(ts), " +
" INTERVAL '30' MINUTE, " +
" INTERVAL '1' HOUR) " +
" ) " +
"GROUP BY user, window_start, window_end");
tableEnv.toDataStream(result).print();
env.execute();
}
}
package POJO;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Event {
public String id;
public String url;
public Long ts;
}
这里我们使用了统计周期为 1 小时、累积间隔为 30 分钟的累积窗口,代码执行结果如下:
+I[Alice, 1970-01-01T00:30, 2]
+I[Bob, 1970-01-01T00:30, 1]
+I[Alice, 1970-01-01T01:00, 3]
+I[Bob, 1970-01-01T01:00, 1]
+I[Bob, 1970-01-01T01:30, 1]
+I[Cary, 1970-01-01T02:00, 2]
+I[Bob, 1970-01-01T02:00, 1]
与分组聚合不同,窗口聚合不会将中间聚合的状态输出,只会最后输出一个结果。我们可以看到,所有数据都是以 INSERT 操作追加到结果动态表中的,因此输出每行前面都有+I 的前缀。所以窗口聚合查询都属于追加查询,没有更新操作,代码中可以直接用 toDataStream() 将结果表转换成流。
具体来看,上面代码输入的前三条数据属于第一个半小时的累积窗口,其中Alice 的访问数据有两条,Bob 的访问数据有 1 条,所以输出了两条结果[Alice, 1970-01-01T00:30, 2]和[Bob, 1970-01-01T00:30, 1];而之后又到来的一条Alice 访问数据属于第二个半小时范围,同时也属于第一个 1 小时的统计周期, 所以会在之前两条的基础上进行叠加, 输出[Alice,1970-01-01T00:30, 3],而 Bob 没有新的访问数据,因此依然输出[Bob, 1970-01-01T00:30, 1]。从第二个小时起,数据属于新的统计周期,就全部从零开始重新计数了。
相比之前的分组窗口聚合,Flink 1.13 版本的窗口表值函数(TVF)聚合有更强大的功能。除了应用简单的聚合函数、提取窗口开始时间(window_start)和结束时间(window_end)之外, 窗口 TVF 还提供了一个 window_time 字段,用于表示窗口中的时间属性;这样就可以方便地进行窗口的级联(cascading window)和计算了。另外,窗口TVF 还支持 GROUPING SETS, 极大地扩展了窗口的应用范围。
基于窗口的聚合,是流处理中聚合统计的一个特色,也是与标准 SQL 最大的不同之处。在实际项目中,很多统计指标其实都是基于时间窗口来进行计算的,所以窗口聚合是 Flink SQL 中非常重要的功能;基于窗口 TVF 的聚合未来也会有更多功能的扩展支持,比如窗口 Top N、会话窗口、窗口联结等等。
3.3 开窗聚合(Over)
OVER 窗口是基于当前行扩展出的一段数据范围,选择的标准可以基于时间也可以基于数量。不论那种定义,数据都应该是以某种顺序排列好的;而表中的数据本身是无序的。所以在OVER 子句中必须用 ORDER BY 明确地指出数据基于那个字段排序。在 Flink 的流处理中, 目前只支持按照时间属性的升序排列,所以这里 ORDER BY 后面的字段必须是定义好的时间属性

3.4 TopN
目前在 Flink SQL (1.13) 中没有能够直接调用的 Top N 函数,而是提供了稍微复杂些的变通实现方法。
3.4.1 普通Top N
在 Flink SQL 中,是通过 OVER 聚合和一个条件筛选来实现 Top N 的。具体来说,是通过将一个特殊的聚合函数ROW_NUMBER()应用到OVER 窗口上,统计出每一行排序后的行号, 作为一个字段提取出来;然后再用WHERE 子句筛选行号小于等于N 的那些行返回。
SELECT ... FROM (
SELECT ...,
ROW_NUMBER() OVER (
[PARTITION BY <字段 1>[, <字段 1>...]]
ORDER BY <排序字段 1> [asc|desc][, <排序字段 2> [asc|desc]...]
) AS row_num
FROM ...)
WHERE row_num <= N [AND <其它条件>]
这里的 OVER 窗口定义与之前的介绍基本一致,目的就是利用 ROW_NUMBER()函数为每一行数据聚合得到一个排序之后的行号。行号重命名为 row_num,并在外层的查询中以row_num <= N 作为条件进行筛选,就可以得到根据排序字段统计的 Top N 结果了。
需要对关键字额外做一些说明:
where
用来指定Top N 选取的条件,这里必须通过 row_num <= N 或者 row_num < N + 1 指定一个“排名结束点”(rank end),以保证结果有界
partitionby
是可选的,用来指定分区的字段,这样我们就可以针对不同的分组分别统计Top N 了。
orderby
指定了排序的字段,因为只有排序之后,才能进行前N 个最大/最小的选取。每个排序字段后可以用asc 或者 desc 来指定排序规则:asc 为升序排列,取出的就是最小的N 个值;desc 为降序排序,对应的就是最大的N 个值。默认情况下为升序,asc 可以省略。
细心的读者可能会发现,之前介绍的 OVER 窗口不是说了,目前 ORDER BY 后面只能跟时间字段、并且只支持升序吗?这里怎么又可以任意指定字段进行排序了呢?
这是因为OVER 窗口目前并不完善,不过针对 Top N 这样一个经典应用场景,Flink SQL 专门用 OVER 聚合做了优化实现。所以只有在 Top N 的应用场景中,OVER 窗口ORDER BY 后才可以指定其它排序字段;而要想实现 Top N,就必须按照上面的格式进行定义,否则 Flink SQL 的优化器将无法正常解析。而且,目前 Table API 中并不支持ROW_NUMBER()函数,所以也只有 SQL 中这一种通用的Top N 实现方式。
另外要注意,Top N 的实现必须写成上面的嵌套查询形式。这是因为行号 row_num 是内部子查询聚合的结果,不可能在内部作为筛选条件,只能放在外层的 WHERE 子句中。
下面是一个具体的示例,我们统计每个用户的访问事件中,按照字符长度排序的前两个url:
SELECT
user,
url,
ts,
row_num
FROM (
SELECT
*,
ROW_NUMBER() OVER ( PARTITION BY user ORDER BY CHAR_LENGTH(url) desc
) AS row_num
FROM EventTable)
WHERE row_num <= 2
这里我们以用户来分组,以访问 url 的字符长度作为排序的字段,降序排列后用聚合统计出每一行的行号,这样就相当于在 EventTable 基础上扩展出了一列 row_num。而后筛选出行号小于等于 2 的所有数据,就得到了每个用户访问的长度最长的两个 url。
需要特别说明的是,这里的 Top N 聚合是一个更新查询。新数据到来后,可能会改变之前数据的排名,所以会有更新(UPDATE)操作。这是 ROW_NUMBER()聚合函数的特性决定的。因此,如果执行上面的 SQL 得到结果表,需要调用 toChangelogStream()才能转换成流打印输出。
3.4.2 窗口TopN
除了直接对数据进行Top N 的选取,我们也可以针对窗口来做Top N。
例如电商行业,实际应用中往往有这样的需求:统计一段时间内的热门商品。这就需要先开窗口,在窗口中统计每个商品的点击量;然后将统计数据收集起来,按窗口进行分组,并按点击量大小降序排序,选取前N 个作为结果返回。
我们已经知道,Top N 聚合本质上是一个表聚合函数,这和窗口表值函数(TVF)有天然的联系。尽管如此,想要基于窗口TVF 实现一个通用的Top N 聚合函数还是比较麻烦的,目前Flink SQL 尚不支持。
不过我们同样可以借鉴之前的思路,使用OVER 窗口统计行号来实现。具体来说,可以先做一个窗口聚合,将窗口信息 window_start、window_end 连同每个商品的点击量一并返回,这就得到了聚合的结果表,包含了窗口信息、商品和统计的点击量。接下来就可以像一般的 Top N 那样定义 OVER 窗口了,按窗口分组,按点击量排序,用ROW_NUMBER()统计行号并筛选前 N 行就可以得到结果。所以窗口 Top N 的实现就是窗口聚合与 OVER 聚合的结合使用。
下面是一个具体案例的代码实现。由于用户访问事件 Event 中没有商品相关信息,因此我们统计的是每小时内有最多访问行为的用户,取前两名,相当于是一个每小时活跃用户的查询。
import POJO.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
public class WindowTopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTs();
}
}));
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
// 将 timestamp 指定为事件时间,并命名为 ts
);
// 为方便在 SQL 中引用,在环境中注册表 EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 定义子查询,进行窗口聚合,得到包含窗口信息、用户以及访问次数的结果表
String subQuery =
"SELECT window_start, " +
"window_end, " +
"user, " +
"COUNT(url) as cnt " +
"FROM TABLE ( " +
"TUMBLE( TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR )) " +
"GROUP BY window_start, window_end, user ";
// 定义 Top N 的外层查询
String topNQuery =
"SELECT * " + "FROM (" +
"SELECT *, " +
"ROW_NUMBER() OVER ( " +
"PARTITION BY window_start, window_end " + "ORDER BY cnt desc " +
") AS row_num " +
"FROM (" + subQuery + ")) " + "WHERE row_num <= 2";
// 执行 SQL 得到结果表
Table result = tableEnv.sqlQuery(topNQuery);
tableEnv.toDataStream(result).print();
env.execute();
}
}这里为了更好的代码可读性,我们将 SQL 拆分成了用来做窗口聚合的内部子查询,和套用 Top N 模板的外层查询。
首先基于 ts 时间字段定义 1 小时滚动窗口,统计 EventTable 中每个用户的访问次数,重命名为 cnt;为了方便后面做排序,我们将窗口信息 window_start 和 window_end 也提取出来,与 user 和 cnt 一起作为聚合结果表中的字段。
然后套用 Top N 模板,对窗口聚合的结果表中每一行数据进行 OVER 聚合统计行号。这里以窗口信息进行分组,按访问次数 cnt 进行排序,并筛选行号小于等于 2 的数据,就可以得到每个窗口内访问次数最多的前两个用户了。
+I[1970-01-01T00:00, 1970-01-01T01:00, Alice, 3, 1]
+I[1970-01-01T00:00, 1970-01-01T01:00, Bob, 1, 2]
+I[1970-01-01T01:00, 1970-01-01T02:00, Cary, 2, 1]
+I[1970-01-01T01:00, 1970-01-01T02:00, Bob, 1, 2]文章来源:https://www.toymoban.com/news/detail-594976.html
可以看到,第一个 1 小时窗口中,Alice 有 3 次访问排名第一,Bob 有 1 次访问排名第二; 而第二小时内,Cary 以 2 次访问占据活跃榜首,Bob 仍以 1 次访问排名第二。由于窗口的统计结果只会最终输出一次,所以排名也是确定的,这里结果表中只有插入(INSERT)操作。也就是说,窗口 Top N 是追加查询,可以直接用 toDataStream()将结果表转换成流打印输出。 文章来源地址https://www.toymoban.com/news/detail-594976.html
到了这里,关于FlinkSQL 时间语义、窗口和聚合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!