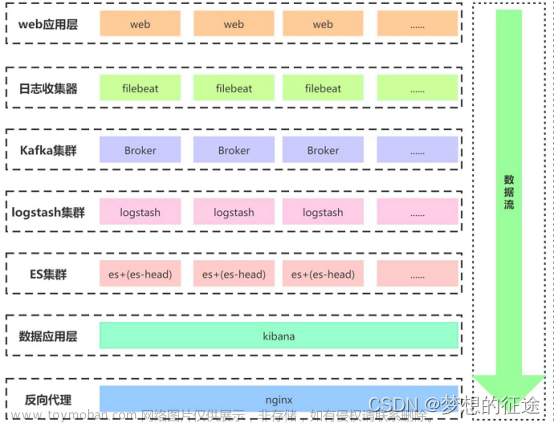
Filebeat用于日志收集和传输,相比Logstash更加轻量级和易部署,对系统资源开销更小,如果对于日志不需要进行过滤分析的,可以直接使用filebeat。
拉取镜像:
docker pull elastic/filebeat:7.5.1
启动
docker run -d --name=filebeat elastic/filebeat:7.5.1
拷贝容器中的数据文件到宿主机
docker cp filebeat:/usr/share/filebeat /data/elk7/
chmod 777 -R /data/elk7/filebeat
chmod go-w /data/elk7/filebeat/filebeat.yml
修改配置文件中的elasticsearch地址
vim filebeat.yml
# 收集系统日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
output.elasticsearch:
hosts: '120.48.54.67:9002'
indices:
- index: "filebeat-%{+yyyy.MM.dd}"
重新启动
先删除之前的容器
docker rm -f filebeat
重启容器
docker run -d --name=filebeat --restart=always -v /data/elk7/filebeat:/usr/share/filebeat -v /var/log/messages:/var/log/messages elastic/filebeat:7.5.1
访问elasticsearch head:
 文章来源:https://www.toymoban.com/news/detail-595263.html
文章来源:https://www.toymoban.com/news/detail-595263.html
访问kibana,创建索引:



这样就可以实现动态收集日志的功能了,但是这样有一点风险,logstash采集本地log4j产生的日志,然后输入进es里,如果吞吐量太大的时候es可能会扛不住,所以最好需要一个高吞吐量的消息队列做一个缓冲,做削峰和异步处理,提升系统性能。推荐使用kafka消息队列。文章来源地址https://www.toymoban.com/news/detail-595263.html
到了这里,关于部署Filebeat收集日志并转发到Elasticsearch的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![搭建EFK(Elasticsearch+Filebeat+Kibana)日志收集系统[windows]](https://imgs.yssmx.com/Uploads/2024/02/475312-1.png)