一、上传镜像
(1)在/var/www/html/下新建flink-cdh文件夹
将编译好的镜像上传到flink-cdh下,主要有下面三个文件
FLINK-1.13.2-BIN-SCALA_2.11-el7.parcel
FLINK-1.13.2-BIN-SCALA_2.11-el7.parcel.sha
manifest.json
(2)将FLINK_ON_YARN-1.13.2.jar上传到/opt/cloudera/csd文件夹下
二、parcel配置

点击配置,添加httpd中的cdh镜像路径

三、重启cdh agent、server服务
(1)systemctl restart cloudera-scm-agent
(2)systemctl restart cloudera-scm-server
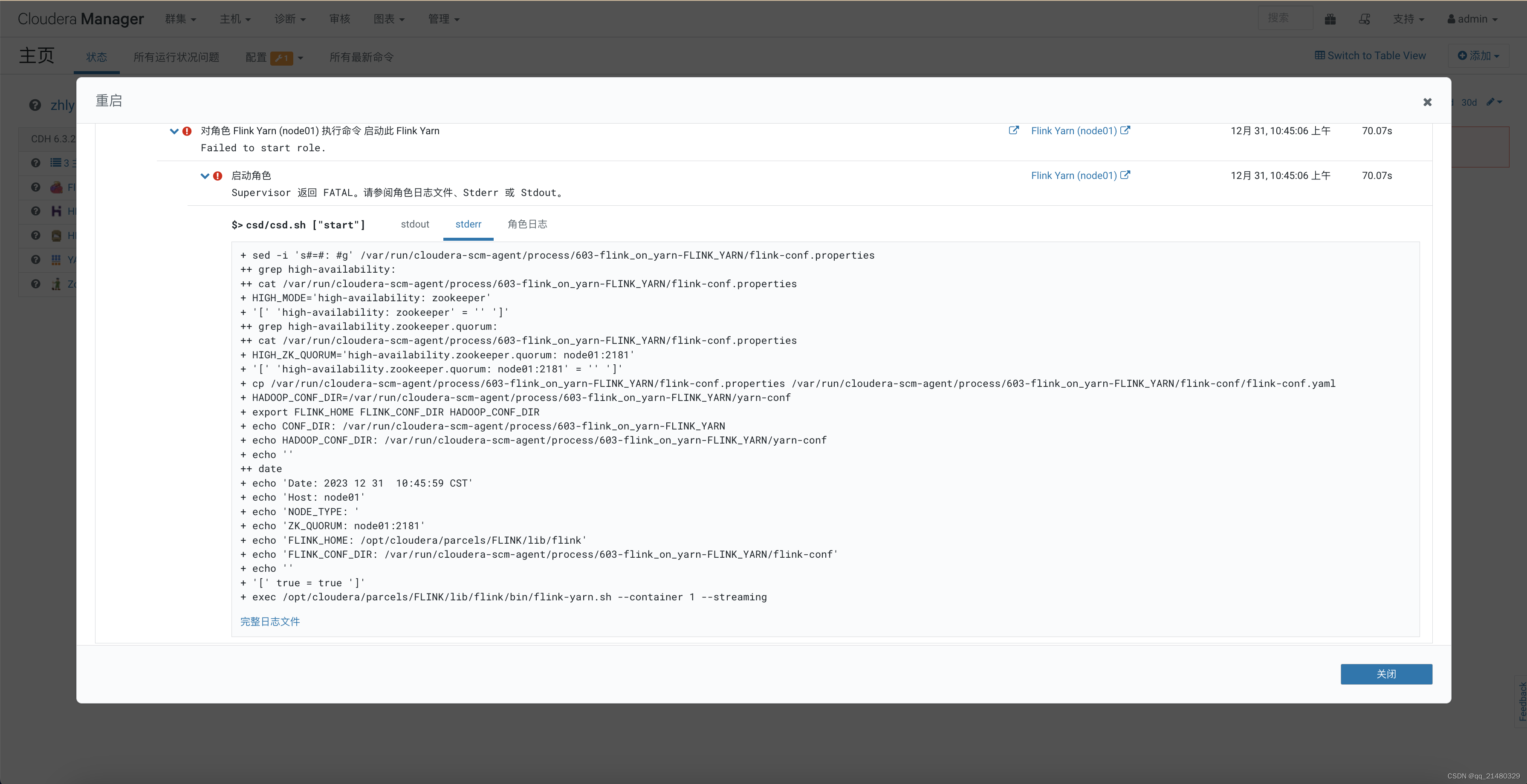
(3)重新进行parcel页面,看到FLINK下已经有了parcel的包,如果提示哈希验证失败,则先去排查
FLINK-1.13.2-BIN-SCALA_2.11-el7.parcel.sha 和 manifest.json两个文件中的哈希值是否一致,如果一致,则是httpd服务导致,需要进行httpd配置文件的修改。
vim /etc/httpd/conf/httpd.conf ,在如图AddType 行添加.parcel,注意tgz前面的空格

重启httpd
systemctl restart httpd
重启cdh agent、server服务
systemctl restart cloudera-scm-agent
systemctl restart cloudera-scm-server
四、配置镜像
(1)重新进入parcel页面,点击下载,完成下载
(2)点击分配,完成分配

(3)点击激活

五、下载依赖jar包flink-shaded-hadoop,并上传到需要安装flink集群节点的服务器
(1)https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/

(2)存放路径:
work1:/opt/cloudera/parcels/FLINK/lib/flink/lib
work2:/opt/cloudera/parcels/FLINK/lib/flink/lib
work3:/opt/cloudera/parcels/FLINK/lib/flink/lib
work4:/opt/cloudera/parcels/FLINK/lib/flink/lib
export HADOOP_CLASSPATH=/opt/cloudera/parcels/FLINK/lib/flink/lib
没有这个包,各节点上的flink会无法启动
六、安装
(1)点击添加服务,选择flink-yarn

(2)选择主机,分配节点
注意将页面中kerberos两项置为空
security.kerberos.login.keytab
security.kerberos.login.principal
(3)完成安装

(4)完成安装

(5)访问flink页面文章来源:https://www.toymoban.com/news/detail-595331.html
http://10.13.8.88:8081/(节点IP+8081)文章来源地址https://www.toymoban.com/news/detail-595331.html

到了这里,关于CDH 6.3.2下安装Flink的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!