介绍一下redis数据库
Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。
Redis 提供了多种数据类型来支持不同的业务场景,比如 String(字符串)、Hash(哈希)、 List (列表)、Set(集合)、Zset(有序集合)、Bitmaps(位图)、HyperLogLog(基数统计)、GEO(地理信息)、Stream(流),并且对数据类型的操作都是原子性的,因为执行命令由单线程负责的,不存在并发竞争的问题。
除此之外,Redis 还支持事务 、持久化、Lua 脚本、多种集群方案(主从复制模式、哨兵模式、切片机群模式)、发布/订阅模式,内存淘汰机制、过期删除机制等等。
介绍redis的单线程模型
Redis是一个基于内存的高性能键值数据库,它的单线程模型是其最大特点之一。单线程模型意味着Redis在一个单独的线程中处理所有的读写请求,而其他线程则负责其他的任务,比如网络I/O和事件处理。
Redis的单线程模型是通过使用一个单线程的IO线程和多个后台线程来实现的。IO线程负责接收客户端的请求,并将请求转发给后台线程。后台线程负责处理所有的命令请求,并将结果返回给IO线程。IO线程再将结果返回给客户端。
虽然Redis的单线程模型可以提高性能,但也存在一些缺点。例如,由于只有一个线程,因此在高并发的情况下,可能会导致请求处理速度变慢。此外,由于Redis是基于内存的,因此也可能会存在内存泄漏的问题。
总之,Redis使用单线程的IO线程,而不是多线程的IO线程,这样可以避免线程切换的开销,提高性能。此外,Redis还使用了阻塞I/O,这样可以避免在高并发情况下,因没有可用的线程而导致的性能下降。最后,Redis还使用了事务机制,可以将多个命令请求作为一个原子操作来执行,这样可以确保数据的一致性。
为什么redis更快/?
因为redis使用单线程(网络I/O和 执行命令),有几个原因:
·redis基于内存的数据库,采用了高效数据结构,瓶颈是内存,CPU不是瓶颈,所以用单线程就能解决。
·单线程模型避免多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,不会有死锁。
·redis采用I/O多路复用机制处理大量客户端socket请求,IO多路复用机制是一个线程处理多个 IO 流,就是常听到** select/epoll 机制**。在redis只允许单线程情况下,该机制允许内核中,同时存在多个监听socket和已连接socket。 内核会监听。一旦有请求,就交给redis线程处理,这就实现了一个redis处理多个IO流效果。
redis怎么实现持久化?
redis读写都在内存中,所以redis性能才会高,当redis重启后,内存中数据会丢失,所以需要持久化。存数据文件到磁盘中,这样redis重启就能从磁盘中恢复原有数据。
两种数据持久化方式:
AOF【Append Only File(追加文件)】日志:每执行一条写,都会追加到文件中。
RDB【Redis Database Backup file(Redis数据备份文件)】快照:某一时刻的内存数据,以二进制方式写入磁盘。
redis单线程会不会浪费资源?
redis6.0后,也采用了多个I/O线程来处理网络模块,因为随着网络硬件性能提升,Redis的性能瓶颈可能出现在网络I/O处理上。
但只是redis6.0对于网络I/O采用多线程来处理,但是对于命令的执行仍用单线程来处理。
redis执行命令是单线程,如何利用多核心来提升性能?
部署多个 redis docker 容器来处理,达到充分利用 cpu 多核心的效果
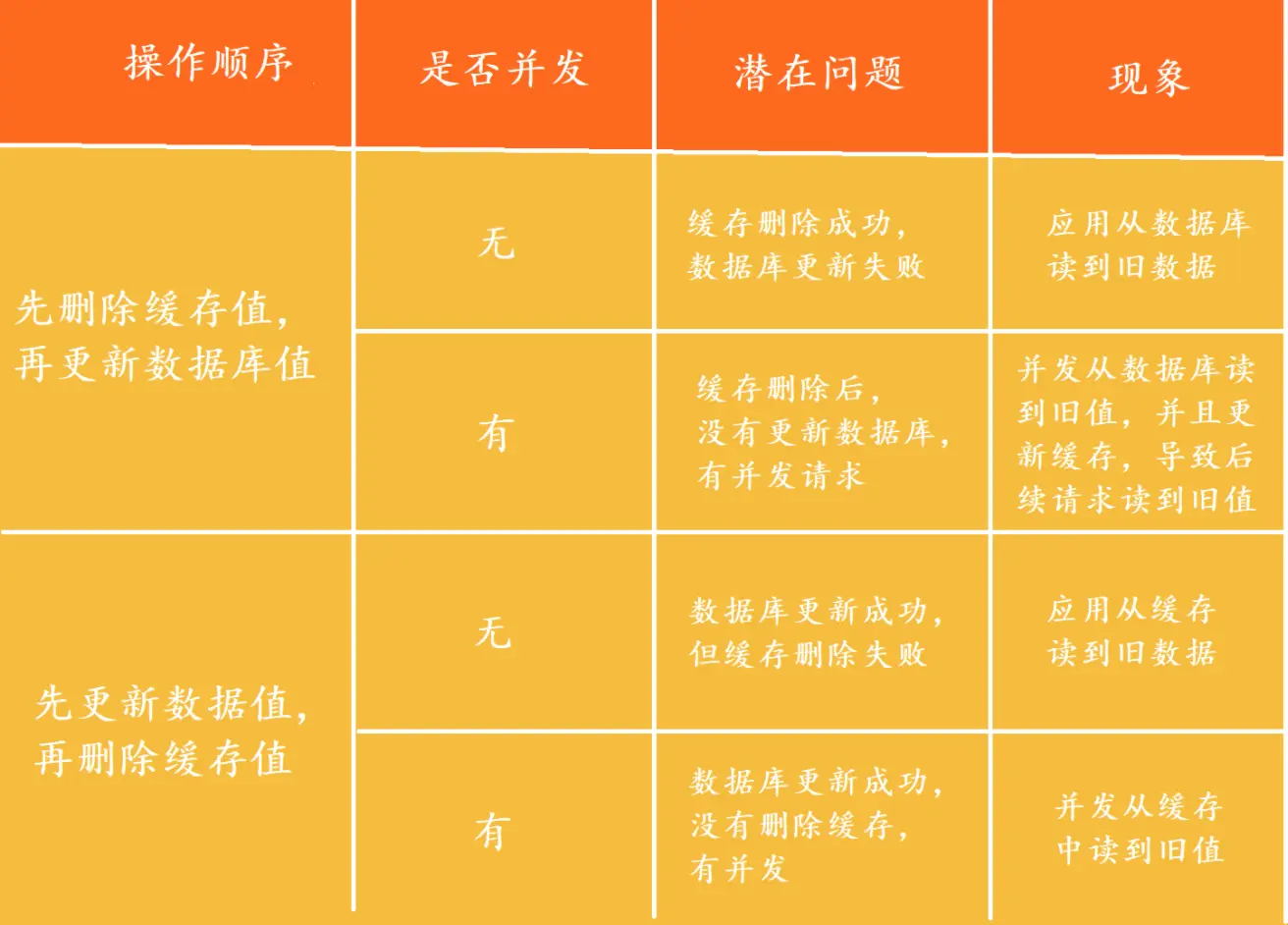
redis缓存穿透、缓存击穿、缓存雪崩是什么?怎么解决?
-
缓存雪崩
当大量缓存数据在同一时间过期或者 Redis 故障宕机时,大量用户请求全部访问数据库。同时也会做大量给内存中缓存的操作,压力剧增,一系列连锁反应,导致整个系统崩溃。
· 解决办法
大量数据同时过期时
- 均匀设置过期时间
- 互斥锁:避免大量访问数据库的结果大量去做存内存操作,加锁同一时间只有一个请求能写缓存。
- 双key策略:使用两个key,主key和副key。过期时间,备用key,不过期。业务主线访问不到主key的缓存数据时,直接返回备key的缓存。(内存中同时写两份,一份过期,还有一份)
- 后台更新缓存策略:后台线程定时更新缓存。
redis故障宕机时
- 启动服务熔断:防止整个系统雪崩,暂停业务对缓存服务的访问,直接返回错误。或者请求限流,只有少量请求发送到数据库中。
- 构建高可靠集群:通过主从节点方式构建redis缓存可靠集群。
-
缓存击穿
缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮。因为不只是访问都普通数据库,而是还会都去写内存。
· 解决办法
- 互斥锁方案:保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 热点数据不设置过期时间:临近过期的热点数据,重写设置过期时间。
-
缓存穿透
频繁去请求一个不在内存和数据库中的数据。使得数据库压力剧增。
· 解决办法
- 非法请求的限制:在API入口处判断请求参数是否合理,是否是带一些特殊字符或者超区间的访问
- 缓存存空值或默认值:不存在的就先存空值或默认值。可以使得不必都去查询数据库。
- 布隆过滤器: 布隆过滤器100%确定不存在。
怎么用redis分布式锁?
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值。
setnx - 锁变量需要设置过期时间。
setnx的ex/px选项,设置过期时间。ex和px区别是粒度不一样。 - 锁变量的值,需要能区分是哪个客户端的加锁操作,所以最好设置为能唯一标识某个客户端的值,这样防止失误地释放。
讲讲redis持久化
redis在内存中,如果意外关机或下次重启,如何恢复内存中的数据。有两种方式RDB、AOF。
-
RDB方式
1> 概念:rdb是快照策略,在配置文件中
2>底层机制:每次存快照会fork一个子进程,父进程继续处理请求,而子进程去把当前的所有数据
2.1> 做保存生成临时rdb文件,替换掉之前的rdb文件,就成了正是的rdb文件。
2.2> save规则满足的情况下会触发rdb规则。
2.3> 执行flushall(触发清除整个redis数据缓存)命令也会触发rdb规则。
2.4>退出redis也会产生rdb文件。
在dump.rdb文件中:里面设定了:
save 900 1
save 1000 2
意思是:每900秒内改1个值,就做一次快照。会触发RDB快照。
当配置好后,启动后激活rdb操作后:在bin下会生成rdb文件。
· RDB的优点:
1 适合大规模数据恢复。
2 对数据的完整性要求不高!
· RDB的缺点:
1 需要一定的时间间隔进行操作。如果redis意外宕机了,最后一次修改数据就没有了
2 fork进程时,会占用一定内存空间
- AOF方式
append only file
默认不开启的,需要手动配。操作发现 appendonly.aof中就有了操作记录。
· 机制:
父进程fork子进程,记录全部写操作。
· AOF文件出错后会导致redis不能重启:
redis提供了工具,redis -check-aof–fix。
· 缺点:
aof远大于rdb,修复速度比rdb慢
aof运行效率要比rdb慢,redis默认配置是rdb持久化
如果AOF文件大于64m,太大了,fork新进程来将文件重写。
AOF无限追加,必然会越来越大。
rewrite参数,在配置中可以看到。
· 建议:
RDB只在从机上,15分钟备份一次即可。
微博每次启动,看哪个从机RDB更新更大,就用哪个RDB。
讲讲redis的订阅发布
信息通信模式,发送者push,订阅者订阅接收。
消息发布者发送消息到队列中,而消息订阅者去抢队列中的内容。
关注(订阅)频道、订阅(已经订阅频道的)信息、退订、发送到指定频道
操作:
先订阅一个频道,频道名称。
一个redis端去订阅a频道
subscribe a
而redis-server 服务端维护了一个字典,字典的键就是个频道,而字典的值是一个链表,链表中保存了所有订阅这个频道的客户端。subscribe命令的关键,是将客户端添加到给定的channel的订阅链表中。
本质是将客户端添加到管道的链表中。
另外一个去给频道中发布:publish a “mess_test”,
则在第一个redis端收到了推送过来的。
场景:
适合实时消息系统,实时聊天系统。
讲讲redis主从复制
· 机制:
一台redis服务的数据,复制到其它redis服务器,前者是主节点,后者从节点。
复制的是从机,原始是主节点,且主机写为主,从机读为主。
80%的情况都是在做读操作。减缓服务器压力,在架构中经常使用。
· 主从复制的主要作用:
数据冗余
故障恢复
负载均衡
高可用基石:一般至少一主二从。
配置方式:
把redis.conf配置几份,不同端口配置到不同conf文件中。
改端口,pid名字,日志名字,备份文件dump.rdb名,依次修改后,分别启动使用。
一主二从:
默认情况下,每一台都是主节点,而配置完后,才有主从节点。
只需要在从机中配置即可。
在从机中执行:slaveof 127.0.0.1 6379 让从机寻找某个端口做主机,
主机中可以查看从机信息:info replication
配置好后,从节点不能写。
全量复制:
从机第一次连接到主机时,就会全部复制一遍。
增量复制:
后面增加的内容
宕机后配置:
当主节点宕机后,如何从节点做替补设置?
slaveof no one:使自己成为主节点
之后主机恢复,也没有用了,只能重新配置。
如果把这些写到配置文件中,每次改得比较麻烦。
而当不写配置文件,反而执行命令就能达到想要的效果。
哨兵模式:自动选取主机节点的模式
自动版的自动选举主机的模式
哨兵也需要多个,哨兵之间也互相监督,且哨兵也监督各个节点

故障转移操作, 投票的结果由一个哨兵发布,然后通过发布订阅模式,让哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
操作:
各个主机上配置:vim sentinel.conf
一串配置最后的1是说主机挂掉,做投票,让某个节点去做主机文章来源:https://www.toymoban.com/news/detail-596336.html
启动哨兵模式,
redis-sentinel sentinel.conf
当主机没了,就发生故障转移。
如果master节点断开,此时就会从从机中随机选择服务器。这里有投票算法。
哨兵日志:
当主机恢复后,也只能是从机。
·哨兵模式的优点:
基于主从模式,自动化
主从可以切换,故障转移,系统可用性更好
· 哨兵模式的缺点:
redis不好做在线扩容,数量一旦上限,在线扩容就很麻烦。
实现哨兵模式配置很麻烦,里面有很多选择。
还有哨兵集群。文章来源地址https://www.toymoban.com/news/detail-596336.html
到了这里,关于Redis常见须知的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!