Linux 文件结构概念
- 文件和目录被组织成一个倒置的单根树形结构
- 文件系统从根目录开始,使用单个正斜线字符(
/)代表 - 严格区分大小写
- 路径使用
/分隔
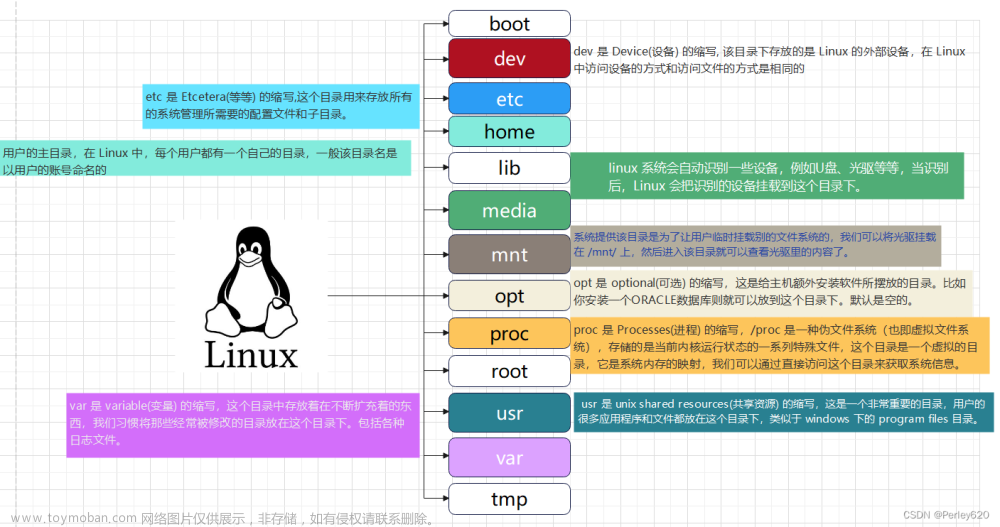
某些重要的目录
- 主目录:
/root、/home/用户名 - 用户可执行文件目录:
/bin、/usr/bin、/usr/local/bin - 系统可执行文件目录:
/sbin、/usr/sbin、/usr/local/sbin - 其它挂载点:
/media、/mnt - 配置:
/etc - 临时文件:
/tmp、/var/tmp - 内核和引导加载程序:
/boot - 服务器数据:
/var、/srv - 系统信息:
/proc、/sys、/run - 设备文件:
/dev - 共享库:
/lib{,64}、/usr/lib{,64}、/usr/local/lib{,64} - SELinux:
/sys/fs/selinux或/selinux
参考
- $ man 7 hier
- FHS(FileSystem Heirache Standard)
- https://www.ibm.com/developerworks/cn/linux/l-cn-sysfs/
文件和目录名称
- 名称可以长达 255 个字符
- 除了正斜线(
/)以外,所有字符都是有效的- 使用特殊字符的文件或目录名并不明智
- 某些字符(如:空格)在引用时应该使用引号来保护
- 名称区分大小写
- 例如:
MAIL、Mail、mail和mAiL - 可以同时在同级目录中使用,但不明智
- 例如:
- 以
.开头的文件或目录是隐含的- 使用
l.命令别名显示当前目录下的所有隐含文件 - 使用
ls -a或ls -A显示当前目录下的所有文件(包含隐含文件)
- 使用
文件的类型
- 普通文件 (
-) - 目录 (
d) - 符号链接 (
l) - 字符设备文件 (
c) - 块设备文件 (
b) - 套接字 (
s) - 命名管道 (
p)
普通文件
- 普通文件仅仅就是字节序列,Linux 并没有对其内容规定任何的结构。
- 普通文件可以是
- 程序源代码(c、c++、python、perl 等)
- 可执行文件(文件编辑器、数据库系统、出版工具、绘图工具 等)
- 文本、图片、声音、图像 等
- Linux 不会区别对待不同的文件
- 只有处理这些文件的应用程序才会根据文件的内容赋予相应的含义
- Linux 环境下,只要是可执行的文件并具有可执行属性它就能执行
- 不管其文件名后缀是什么
- 一些数据文件一般也遵循一些文件名后缀规则
- 如:
.txt、.md、.html、.pdf、.c、.py等
- 如:
目录
- 目录是由一组目录项组成
- 目录项可以是对其他文件的指向也可以是其下的子目录指向
- 一个文件的名称是存储在他的父目录中的,而并非与文件内容本身存储在一起
- 硬链接文件实际上就是在某目录中创建目录项
- 实现了一种文件共享机制
- 可在同一个文件系统中允许不止一个目录项指向同一个文件
- 使用
ln命令行建立硬链接文件
- 实现了一种文件共享机制
符号链接
- 符号链接 又称 软链接
- 是指将一个文件指向另外一个文件的文件名
- 这种符号链接的关系由
ln -s命令行来建立
创建链接文件
- ln - 创建链接文件
- 用法:
ln [参数] <被链接的文件> <链接文件名>
- 例如:
ln somefile hardlinkfile
ln -s somefile softlinkfile
ln -s somedir softlinkfile
硬链接和软链接的比较
- 硬链接
- 链接文件和被链接文件必须位于同一个文件系统内
- 不能建立指向目录的硬链接
- 软链接
- 链接文件和被链接文件可以位于不同文件系统
- 可以建立指向目录的软链接
设备文件
- 在 Linux 下,为了屏蔽用户对设备访问的复杂性
- 用户可以用设备名来使用设备,包括硬盘、光驱、打印机等
- 用户可以用访问文件的方法来使用设备
- 设备文件用来访问硬件设备
- 设备名以设备文件的形式存在(存放在
/dev目录) - 每个硬件设备至少与一个设备文件相关联
- 设备文件分为:字符设备(如:键盘)和块设备(如:磁盘)
- 设备名以设备文件的形式存在(存放在
- Linux 下的常用设备文件
| 设备文件 | 说明 |
|---|---|
| /dev/sd* | 硬盘设备 |
| /dev/sr* | 光驱设备 |
| /dev/lp* | 并口设备 |
| /dev/console | 系统控制台 |
| /dev/tty* | 虚拟终端设备 |
| /dev/pts/* | 伪终端设备 |
| /dev/ppp* | ppp设备 |
| /dev/null | 空设备 |
| /dev/zero | 零(ASCII)设备 |
| /dev/urandom | 随机字符设备 |
套接字和命名管道
- Linux 环境下实现进程间通信(IPC)的机制
- 命名管道(FIFO)文件
- 套接字(Socket)文件
- 套接字和命名管道通常是在进程运行时创建或删除的,一般无需系统管理员干预。
判断文件类型
- 文件可以包含许多类型的数据
- 在打开前检查文件的类型来决定要使用的恰当命令或程序
- 命令
file [选项] <文件名>…stat [选项] <文件名>…
文件的时间戳
-
GNU/Linux 的文件有3种类型的时间戳:
-
mtime: 最后修改时间 (
ls -lt) -
ctime: 状态改变时间 (
ls -lc) -
atime: 最后访问时间 (
ls -lu)
-
mtime: 最后修改时间 (
- 说明
- ctime 并非文件创建时间。
- 修改一个文件会改变所有三类时间
- 改变文件的访问权限或拥有者会改变文件的 ctime 和 atime
- 读文件会改变文件的 atime
目录操作命令
-
ls显示文件和目录列表 -
tree显示目录树 -
cd切换目录 -
pwd显示当前工作目录 -
mkdir创建目录 -
rmdir删除空目录
路径 (path)
- 路径是指文件或目录在文件系统中所处的位置
- 绝对路径
- 以斜线(
/)开头 - 描述到文件位置的完整说明
- 任何时候你想指定文件名的时候都可以使用
-
~或~username
- 以斜线(
- 相对路径
- 不以斜线(
/)开头 - 指定相对于你的当前工作目录而言的位置 (
./可省略) - 可以被用作指定文件名的简捷方式
- 不以斜线(
文件操作命令
-
touch生成一个空文件或更改文件的时间-d 时间描述字符串-t [[CC]YY]MMDDhhmm[.ss]-r FILE
-
ln建立链接文件-
-s创建符号连接
-
-
cp复制文件或目录 -
mv移动文件或目录、文件或目录改名 -
rm删除文件或目录
-r- 递归-i- 删除/覆盖 确认提示-f- 强制 删除/覆盖 任何已存在的目标文件-b- 为每个已存在的目标文件创建备份
文本文件显示
-
cat、nl -
tac、rev -
less、more
抽取文本内容
- 按行截取:
head和tail - 按列抽取:
cut - 按关键字抽取:
grep
按关键字抽取文本 - grep
- 显示文件或STDIN中匹配了某种模式的文本
$ grep ‘john’ /etc/passwd
$ date --help | grep year - 使用
-i不区分大小写搜索 - 使用
–o仅显示匹配内容 - 使用
–n显示匹配的行号 - 使用
–c显示匹配的行数 - 使用
–v显示不包含模式的行 - 使用
-r对目录进行递归搜索 - 使用
--color=auto对匹配内容高亮显示 - 使用
-X在显示每行搜索匹配时包括匹配文本前后的 X 行上下文 - 使用
-AX在显示每项搜索匹配时包括匹配文本后的 X 行上下文 - 使用
-BX在显示每行搜索匹配时包括匹配文本前的 X 行上下文 - 使用
-l <str> <dir>返回目录中包含字符串的文件名
$ grep -rl ‘abc’ ~/doc
$ mv $(grep -lr ‘123456’ .) …/temp - 使用
-L <str> <dir>返回目录中不包含字符串的文件名
grep– 支持基本正则表达式(BRE)的模式匹配egrep– 支持扩展正则表达式(ERE)的模式匹配fgrep– 不支持任何正则表达式(RE)的模式匹配,仅支持字符串匹配,速度快
用于复杂搜索的特殊字符 - 正则表达式
正则表达式的元字符:代表特殊含义
- 匹配单个字符
- . : 匹配任意单个字符
- 和 bash 中 glob 一致的字符类别:
-
[abc],[^abc] -
[[:upper:]],[^[:upper:]]
-
-
\w代表[_[:alnum:]] -
\W代表[^_[:alnum:]]
- 重复匹配次数(Repetition)
-
?匹配其前面的字符 0或1 次;即前面的字符是可选的,且最多匹配 1 次 -
*匹配前面的字符任意次(0或多次),使用贪婪模式匹配 -
+匹配前面的字符至少 1 次,使用贪婪模式匹配 -
{n}匹配前面的字符 n 次 -
{n,}匹配前面的字符至少 n 次,使用贪婪模式匹配 -
{,m}匹配前面的字符至多 m 次,(GNU 扩展). -
{n,m}匹配前面的字符 n 到 m 次
-
- 位置锚定(Anchoring)
-
^代表行首 -
$代表行尾 -
\<代表单词前的空格或其他标点符号 -
\>代表单词后的空格或其他标点符号 -
\b代表单词边界上(前/后)的空格或其他标点符号
-
- 连接(Concatenation)
- 多个RE可以通过任何常规字符或字符串连接起来
- 或者(Alternation)
-
|匹配多个RE之中的任何一个,实现或逻辑
-
- 优先级(Precedence)
- 默认地, 重复(Repetition) > 连接(Concatenation) > 或者(Alternation)
- 若要改变默认优先级,可以在适当位置添加
() - 每个用
()括起来的内容视作一个子RE,并从1开始顺序编号 - 使用
\n(n为数字)可以引用已经通过第n个子RE匹配的内容- 如:
egrep '^(\w+).*\1' /etc/passwd - 如:
egrep '^(\w+)\b.*\1' /etc/passwd
- 如:
正则表达式的类型
- 扩展正则表达式(ERE):
?,+,{,|,(,)
- 适用的程序工具:
egrep,sed -r,awk- 基本正则表达式(BRE):
\?,\+,\{,\|,\(,\)
- 适用的程序工具:
grep,sed
参考
man 7 regex和man grep?(GLOB)=.(RE)*(GLOB)=.*(RE)
按列抽取文本 - cut
- 显示文件或 STDIN 数据的指定列
- 使用
-d指定区分列的定界符(默认为TAB) - 使用
-f指定要显示的列
$ cut -d: -f1 /etc/passwd
$ grep root /etc/passwd | cut -d: -f7 - 使用
-c按字符切割
$ cut -c2-5 /usr/share/dict/words
文本处理与分析工具
- 文本数据统计:
wc - 文本合并:
cat,paste - 文件比较:
diff - 文本排序:
sort - 剔除文本重复行:
sort -u、uniq - 文本随机排列:
sort -R、shuf - 文本替换和删除:
tr、sed - 文本格式化:
fmt、pr、column、fold - 文本编码转换:
iconv、enca、convmv
文本统计 - wc
- 显示文本行数、单词数、字符数等
- 常用选项
-
-l只显示文本的行数 -
-w只显示文本的单词数 -
-c只显示文本的字符数 -
-L只显示文本中最长一行的字符数
-
文本合并 - cat 和 paste
- 纵向合并
cat file1 file2 > newfile
- 横向合并
paste file1 file2 > newfile
文本比较 - diff
- 比较两个文件之间的区别
$ diff foo.conf-broken foo.conf-works
5c5
< use_widgets = no
----
> use_widgets = yes
- 比较两个目录之间的区别
diff -r dir1 dir2
随机排列(洗牌) - shuf
- 以行为单位打乱文件内容的顺序
shuf /etc/passwd - 将命令参数作为输入, 打乱其的顺序
shuf -e apple banana cherry lemon orange pear raspberry - 将一个数值范围作为输入, 打乱其的顺序
shuf -i 1-10
shuf 的常用选项
-n N: 取 N 行-r: 允许重复
随机值的获取
- 使用环境变量:
$RANDOM- 使用UNIX纪元时间:
date +%s- 使用 shuf:
shuf -i 1-65535 -n1- 使用随机设备:
/dev/urandom
- 使用随机数据生成下面的学生表(Name,Nick,Password,Gender,Age,Tel)
st01 Syu LeLJpG9KTU famale 28 13342675170
st02 Ohn N30uLpQYh1 famale 19 13332881942
st03 Rmo fZZHqVMfae famale 25 13347745308
st04 Mju CioZLy4Pt0 male 22 13459810354
st05 Biu aAyFvdSeTu male 22 13673659969
st06 Psk EGaJ5OLLzU male 27 13988407444
st07 Tln JPNxVoRUmr male 18 13770716174
st08 Ptu ve39zRTmiL male 21 13823448278
st09 Xaw jW9gIOf1xr famale 29 13195204321
st10 Ibo 5oskpYfdeY famale 28 13716142384
st11 Qbx WKH38Remu8 famale 18 13988542041
st12 Bdj EhTujFPuaV famale 28 13364446233
st13 Vel i5BAGUvFGL male 21 13557400946
st14 Gdb xOUc2ArRvd male 19 13657805803
st15 Nzn sRcLxaAGMJ famale 30 13105101475
st16 Jka RFNSBwG8P8 famale 18 13807347024
st17 Mmt GbP1yCXdKA male 20 13253259923
st18 Hli P4N6MZFhAR male 18 13282951065
st19 But GK3Ckrduil famale 18 13747153535
st20 Nta laYnn9puAO famale 24 13935185913
- 用随机数据生成一个简易版的 Apache 访问日志文件
68.39.177.6 - - [08/Aug/2016:02:00:46 +0800]
225.189.211.29 - - [18/Aug/2016:17:11:31 +0800]
50.155.240.250 - - [30/Jul/2016:01:36:16 +0800]
121.226.58.74 - - [28/Jan/2017:14:47:45 +0800]
107.17.243.35 - - [19/Aug/2016:11:56:29 +0800]
LANG=C date +'%d/%h/%Y:%T %z'
文本排序 sort
- 将排序过的文本显示在STDOUT,不改变原始文件
$ sort [options] file(s) - 常用选项
-
-n按数字排序 -
-V按版本号排序 -
-M按月份排序, (unknown) < ‘JAN’ < … < ‘DEC’ -
-f忽略字符串中的字符大小写 -
-i忽略所有非打印字符 -
-b忽略前导空格或制表符 -
-u删除输出中的重复行 -
-r执行逆序排序(默认为升序) -
-t c使用 c 做为字段界定符 -
-k X按照第 X 字段到行末进行排序 -
-k X,X按照第 X 字段进行排序 -
-k X.m,X.n按照第 X 字段的第 m~n 个字符进行排序
-
-k选项可以使用多次,依次认为第 N 个排序关键字
剔除重复行 - sort 和 uniq
-
sort -u:从输入中删除重复行 -
uniq:从输入中删除重复的前后连续的行- 使用
-c选项来计数发生次数 - 可以和 sort 命令一起使用:
$ sort userlist.txt | uniq -c
- 使用
文本替换和删除 - tr 和 sed
- 改变(translate)字符:
tr- 把一个集合内的字符转换成另一个集合中的相应字符
- 只读取STDIN中的数据
$ tr ‘a-z’ ‘A-Z’ < lowercase.txt
$ echo “HELLO WORLD” | tr ‘A-Z’ ‘a-z’
- 改变字符串:
sed- 流编辑器(stream editor)
- 在一个文本流上进行 搜索/替换 操作
- 默认不改变源文件
- 使用
-i选项:改变源文件 - 使用
-i.bak选项:改变源文件,并备份改变之前的文件
- 使用
tr 命令
-
压缩
$ tr -s ’ \n’ < filename.txt -
替换
$ tr ‘a-z’ ‘A-Z’ < lowercase.txt
$ tr ‘[:blank:]’ ‘[#]’ < filename.txt
$ tr -s ‘[:blank:]’ '[#]’ < filename.txt # 替换同时进行压缩 -
删除
$ tr -d [:punct:] < filename.txt -
对被操作字符集(SET1)使用补集
$ tr -c ‘[:print:][:cntrl:]’ '[?]’ < filename.txt
$ tr -dc [:alnum:] < filename.txt
$ tr -sc [:alpha:] [\n] < filename.txt
sed 命令
- sed 是一个流编辑器(stream editor)
- sed 按顺序逐行的方式工作,过程为:
- 从输入读取一行数据存入临时缓冲区,此缓冲区称为模式空间(pattern space)
- 按指定的 sed 编辑命令处理缓冲区中的内容,若存在多个编辑命令则按前后次序依次执行
- 将模式空间的内容送往屏幕并将这行内容从模式空间中清除
- 读取下面一行。重复上面的过程直到全部处理结束
- sed 命令格式
sed [选项] [-e] cmd1 [[-e cmd2] ... [-e cmdn]] [input-file]...sed [选项] cmd1[;cmd2; ...; cmdn] [input-file]...- 选项
-
-r:使用扩展正则表达式进行模式匹配 -
-i:直接对输入文件进行sed的编辑命令操作
-
- sed 常见的编辑命令
-
's/old/new/','s/old/new/g'-
's#oldpath#newpath#','s#oldpath#newpath#g'
-
Nda\i\c\
-
- 为了加快执行速度,可在编辑命令之前指定地址范围,筛选处理内容
-
'm s/old/new/'- 对第 m 行执行编辑命令 -
'$ s/old/new/'- 对最后一行执行编辑命令 -
'm,n s/old/new/'- 对第 m 到 n 行执行编辑命令 -
'm,+n s/old/new/'- 对第 m 到 m+n 行执行编辑命令 -
'm~n s/old/new/'- 对第 m 及所有 步长为 n 的行执行编辑命令 -
'/RE/ s/old/new/'- 对匹配RE的行执行编辑命令 -
'/RE1/,/RE2/ s/old/new/'- 对从匹配RE1的行到匹配RE2的行执行编辑命令 -
'm,/RE/ s/old/new/'- 对从第 m 行到匹配RE的行执行编辑命令 -
'/RE/,n s/old/new/'- 对从匹配RE的行到第 n 行执行编辑命令 - 在地址范围之后可以紧跟一个
!用于表示对地址范围取反
-
参考
- https://www.gnu.org/software/sed/manual/sed.html
- SED 简明教程
sed 举例
- 给 s 指令加引号
sed ‘s/Unix/Linux/g’ myfile # 将所有Unix替换成Linux
sed ‘s/Unix/&/Linux/g’ myfile # &表示匹配到的字符串
sed ‘s/cc*/c/g’ myfile # 将连续出现的c都压缩成单个的c
sed ‘s/1*//’ myfile # 删除每一行前导的连续空格和制表符
sed ‘s/ *KaTeX parse error: Expected 'EOF', got '#' at position 23: …ile #̲ 删除每行结尾的所有空格 …/d’ myfile # 删除所有空白行 - sed 的地址
sed ‘s/dog/cat/g’ pets
sed ‘20s/dog/cat/g’ pets
sed ‘1~2s/dog/cat/g’ pets
sed ‘1,50s/dog/cat/g’ pets
sed ‘51,$s/dog/cat/g’ pets
sed ‘/digby/s/dog/cat/g’ pets
sed ‘/digby/,/duncan/s/dog/cat/g’ pets - 多个 sed 指令
sed -e ‘s/dog/cat/’ -e ‘s/hi/lo/’ pets
sed -e ‘s/dog/cat/;s/hi/lo/’ pets
sed -f myedits pets
awk 命令
awk 命令的一般形式为:
awk 'BEGIN {actions}
pattern1 {actions}
......
patternN {actions}
END {actions}' input-file
其中:
- BEGIN {actions} 和 END {actions} 是可选的。
- 若省略 {actions} ,等同于 { print } ,即打印全部记录。
- pattern 部分可以使用扩展正则表达式(用 / / 括起来)、关系表达式、范围表达式(两个范围值用逗号间隔)等
awk 的执行过程如下:
- 如果存在BEGIN,awk首先执行它指定的actions。
- awk从输入中读取一行,称为一条输入记录。
- awk将读入的记录分割成数个字段,并将第一个字段放入变量$1中,第二个放入变量$2中,以此类推。$0表示整条记录;字段分隔符可以通过选项-F指定,否则使用默认的分隔符。
- 把当前输入记录依次与每一个语句中pattern比较:如果相匹配,就执行对应的actions;如果不匹配,就跳过对应的actions,直到完成所有的语句。
- 当一条输入记录处理完毕后,awk读取输入的下一行,重复上面的处理过程,直到所有输入全部处理完毕。
- 如果输入是文件列表,awk将按顺序处理列表中的每个文件。
- awk处理完所有的输入后,若存在END,则执行相应的actions。
awk常用的内置变量:
- NF 当前记录中的字段数
- NR 当前记录数
- FS 字段分隔符(默认是空格)
- RS 记录分隔符(默认是一个换行符)
- OFS 输出字段分隔符(默认值是一个空格)
- ORS 输出记录分隔符(默认值是一个换行符)
- IGNORECASE 如果为真,则进行忽略大小写的匹配
参考
- https://www.gnu.org/software/gawk/manual/gawk.html
- AWK 简明教程
awk 举例
awk '/^[U/]/' /etc/fstab
awk '/^[U/]/ {print $1,$3}' /etc/fstab
awk '/^[U/]/ {print $1 "\t" $3}' /etc/fstab
awk '$2=="/" {print $1,$3}' /etc/fstab
awk '$2=="/",/swap/ {print $1,$3}' /etc/fstab
awk '/root/,/swap/ {print $1,$3}' /etc/fstab
awk '$2=="/" || $3=="swap" {print $1,$3}' /etc/fstab
awk '/root/,NR==8 {print $1,$3}' /etc/fstab
awk 'NR%2==1 {print $1,$3}' /etc/fstab
awk 'NR%2==1 && /^[^# ]/ {print $1,$3}' /etc/fstab
awk -F':' '{print $1,$3}' /etc/passwd
awk -F':' '$3>=1000' /etc/passwd
awk -F':' '$3>=1000 {print $1,$3}' /etc/passwd
ip a s enp0s3|grep 'inet '| awk -F '[ /]+' '{print $3}'
ip a|grep '^\w' | awk -F '[ :]' '!/lo/{print $3}'
ls -l|grep -v ^d|awk 'BEGIN {size=0} {size+=$5} END{print "[end]size is", size}'
netstat -nt| awk '{++S[$NF]} END {for(a in S) print a, S[a]}'
ss -nt|awk '{++S[$1]} END {for(i in S) print i "\t" S[i]}'
TCP连接的11种状态变迁
文件编码转换
- 改变文件内容的编码
-
iconviconv -f GBK -t UTF-8 inputfile -o outputfile
-
enconv和encaenconv -L zh_CN -x UTF-8 filenameenca -L zh_CN -x UTF-8 filenameenca -L zh_CN -x utf-8 *
-
- 改变文件名的编码
-
convmvconvmv -f GBK -t UTF-8 --notest *.mp3
-
- 提示: EPEL 仓库中有 enca 和 convmv 的 RPM 包
yum -y --enablerepo=epel install enca convmv
交互式全屏文本编辑器
-
nano编辑器- 容易学习,容易使用
- 和更高级的编辑器相比,没有那么多功能
- 其它编辑器
-
vim:高级的、功能完整的编辑器 -
emacs:GNU 项目之一 -
gedit:一个简单的图形化编辑器 -
gvim:vim 编辑器的图形化版本
-
vim
- vi (Visual Interface) 是全屏幕文本编辑器,没有菜单,只有命令
- vim - Vi IMproved
- 三种主要模式:
- Normal mode - 普通模式(编辑模式)
- Insert mode - 插入模式
- Command-line mode - 末行模式(ex 模式)
-
Esc会退出当前的模式 -
EscEsc总是会返回到普通模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I40qcH75-1689554001073)(/assets/figs/vim.png)]
vim 基础
- 要使用 vim,你必须至少能够
- 打开文件
- 修改文件(插入模式)
- 保存文件(ex 模式)
在 vim 中打开文件
- 启动 vim
vimvim +n <文件名>vim + <文件名>vim -r <文件名>
- 若文件存在,该文件会被打开,内容被显示
- 若文件不存在,vim 会在首次保存时创建它
修改文件 - 插入模式
-
i在光标处开始插入模式 - 存在许多其他选项
-
A在行尾后补 -
I在行首插入 -
o插入一个新行(在下面) -
O插入一个新行(在上面)
-
末行模式 - 保存文件,退出vim
- 使用
:进入 ex模式- 在左下角创建一个命令提示
- 常用的写入/退出命令
-
:w把文件写入磁盘(保存) -
:wq写入后退出 -
:q不保存而退出,所有改变都会消失 -
:q!强制不保存退出 -
:x退出,如果文件更改则保存
-
末行模式 - 搜索并替换
- 像
sed命令中的搜索/替换 - 使用x,y范围或用%在整个文件中搜索
:1,5s/cat/dog/:%s/cat/dog/g
普通模式 - 搜索、替换、复制、删除、粘贴
-
像
less命令一样的搜索- /、?、n、N
-
删除字符
-
x: 删除光标处的字符 -
nx: 删除光标处起始的n个字符
-
-
替换字符
-
rC替换光标所在处的字符为C -
nrC替换光标所在处的n个字符为C
-
-
删除行并存入缓冲区
-
dd:删除光标所在的整行 -
ndd:删除从光标所在位置开始的n行
-
-
复制行并存入缓冲区
-
yy:复制光标所在的整行 -
nyy:复制从光标所在位置开始的n行
-
-
粘贴文章来源:https://www.toymoban.com/news/detail-596414.html
-
p: 粘贴到当前光标所在行的下方 -
P: 粘贴到当前光标所在行的上方
-
普通模式 - 撤销改变
-
u会撤销最近的改变(undo) -
U会撤销自光标被移到该行后对当前行进行的所有改变 -
Ctrl-r会重做上一个被“撤销”的改变
.重复最近一次编辑(redo)
配置 vim
- 动态配置:
-
:set或:set all
-
- 永久配置
~./vimrc
- 几个常用的配置项目
- 行号
- 显示:
:set number, 简写为set nu - 取消:
:set nonumber, 简写为set nonu
- 显示:
- 括号匹配
- 匹配:
:set sm - 取消:
:set nosm
- 匹配:
- 自动缩进
- 启用:
:set autoindent, 简写为:set ai - 禁用:
:set noautoindent, 简写为:set noai
- 启用:
- 高亮搜索
- 启用:
:set hlsearch - 禁用:
:set nohlsearch
- 启用:
- 语法高亮
- 启用:
:set syntax on - 禁用:
:set syntax off
- 启用:
- 忽略字符的大小写
- 启用:
:set ignorecase, 简写为set ic - 禁用:
:set noignorecase, 简写为set noic
- 启用:
- 设置 缩进字符个数
:set tabstop=4
- 设置自动屏幕换行字符宽度
:set textwith=65
- 行号
- 运行
:help option-list来获取完整列表
- vi/vim 的内建帮助
:help:help topic- 使用
:q退出帮助vimtutor命令
-
\t ↩︎文章来源地址https://www.toymoban.com/news/detail-596414.html
到了这里,关于Linux 文件结构概念和常用命令的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!