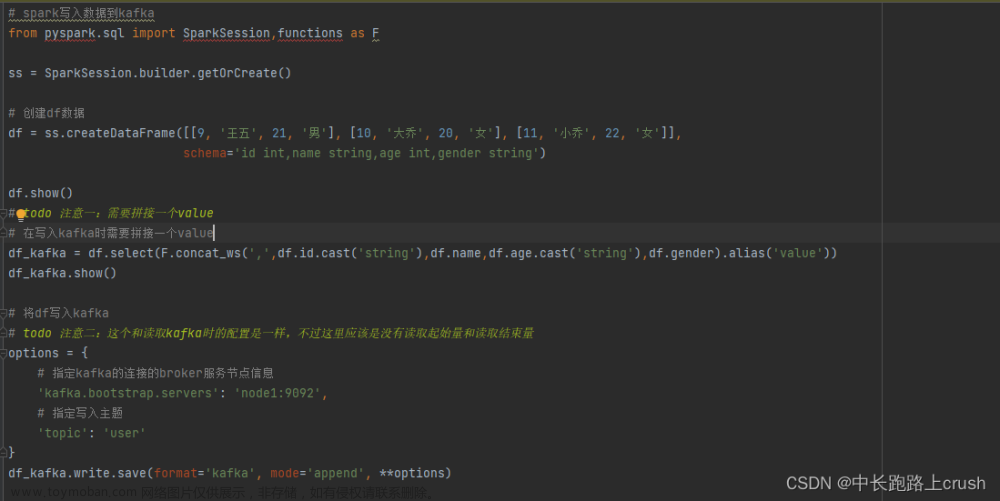
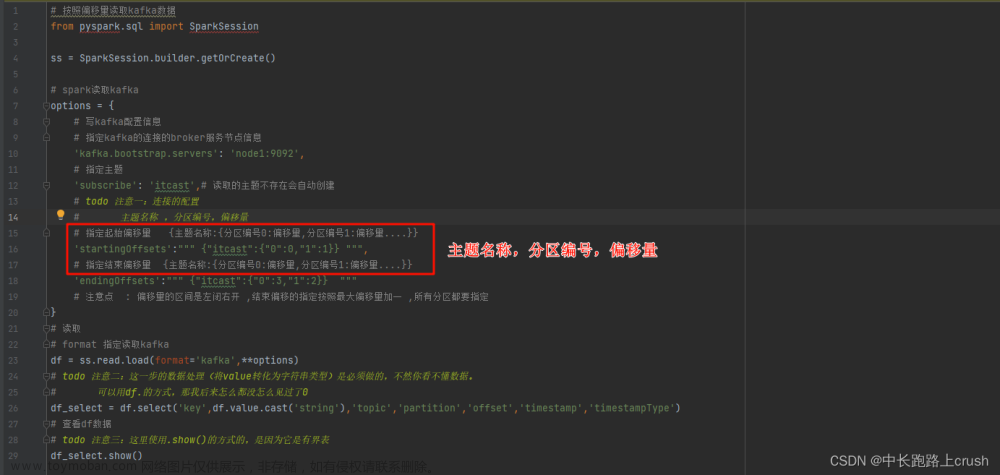
Kafka、Cassandra、Kubernetes和Spark都是用于构建分布式系统的流行技术。下面是它们各自的职责以及如何将它们组合在一起搭建一套系统的简要说明:
1、Kafka(消息队列):
Kafka是一个高吞吐量、可持久化、分布式发布订阅消息系统。它负责处理实时数据流和消息传递。Kafka使用发布-订阅模式,其中消息生产者将消息发布到Kafka主题(topics),而消息消费者从主题订阅消息并进行处理。在系统中,Kafka可用于收集、存储和传输数据。
2、Cassandra(分布式数据库):
Cassandra是一个高度可扩展、分布式和分区的NoSQL数据库系统。它提供了高度容错性和高性能的数据存储,适合处理大规模数据集。Cassandra使用分布式架构,在多个节点上分布数据并提供冗余和容错。它可以用于持久化存储从Kafka接收到的数据。
3、Kubernetes(容器编排平台):
Kubernetes是一个开源的容器编排和管理平台,用于自动化部署、扩展和管理容器化应用程序。它提供了资源调度、自动伸缩、容器间通信等功能,简化了分布式系统的部署和管理。Kubernetes可以用于部署和管理Spark和Cassandra的实例,确保它们的高可用性和弹性。
4、Spark(分布式计算框架):
Spark是一个快速、通用、可扩展的分布式计算系统。它提供了强大的数据处理和分析能力,支持批处理、流式处理和机器学习等多种计算模式。Spark可以与Kafka和Cassandra集成,从Kafka接收实时数据流,将数据存储到Cassandra中,并进行复杂的数据处理和分析。
以下是一种可能的系统架构,将这些技术组合在一起:
1、实时数据流采集:使用Kafka作为数据流的中间件,将实时数据从不同数据源传递到Kafka主题。
2、数据存储:使用Cassandra作为持久化存储,接收Kafka中的数据,并将其分布式存储在Cassandra集群中。
3、分布式计算:使用Spark连接到Kafka主题,读取实时数据流,并进行复杂的数据处理、分析和计算。Spark可以运行在Kubernetes集群上。
4、容器编排和管理:使用Kubernetes部署和管理Spark和Cassandra的实例。Kubernetes确保它们的高可用性、弹性和自动伸缩。文章来源:https://www.toymoban.com/news/detail-597353.html
这样的系统架构可以实现实时数据流的收集、存储和分析,通过将消息队列、分布式数据库、容器编排平台和分布式计算框架结合起来,构建高效、可扩展的分布式系统。请注意,这只是一个示例架构,具体的实现细节和系统设计可能因实际需求而有所不同。文章来源地址https://www.toymoban.com/news/detail-597353.html
到了这里,关于如何用Kafka, Cassandra, Kubernetes, Spark 搭建一套系统?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Spark、hadoop]Spark Streaming整合kafka实战](https://imgs.yssmx.com/Uploads/2024/01/809934-1.png)