论文地址: https://arxiv.org/pdf/2303.10404.pdf
代码: 未开源
目前是MOT20的第二名
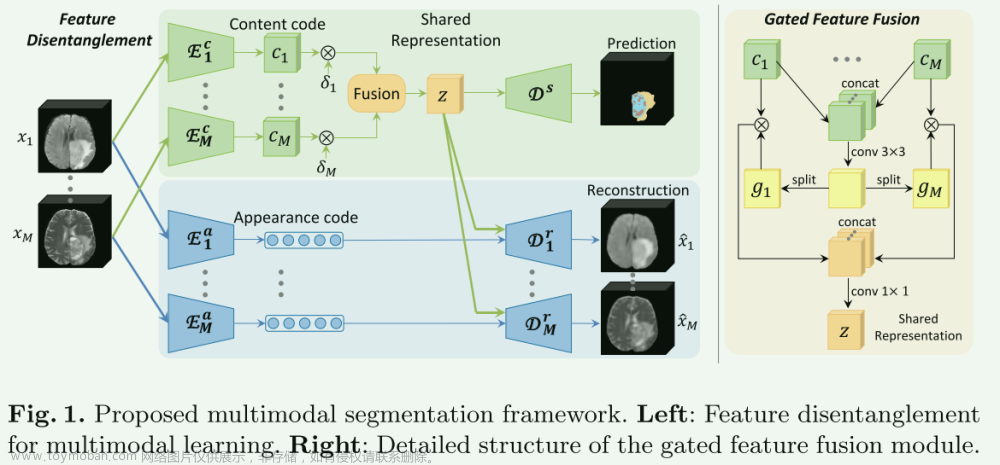
1. Abstract
这篇文章着力于解决长时跟踪的问题. 当前大多数方法只能依靠Re-ID特征来进行长时跟踪, 也就是轨迹长期丢失后的再识别. 然而, Re-ID特征并不总是有效的. 尤其是在拥挤和极度遮挡的情况下. 为此, 这篇文章提出了MotionTrack, 包括两个方面:
- 设计了一个交互模块(Interaction Module), 来学习短轨迹之间的相互作用. 简单来说, 就是根据目标相邻两帧的的偏移, 计算出一个表征目标之间相互影响的矩阵, 随后利用该矩阵经过一个GCN和MLP来直接得到目标的预测位置(代替Kalman滤波).
- 设计了一个恢复模块(Refined Module), 用来拼接碎片化的轨迹. 对于没有匹配成功的检测和丢失的轨迹, 计算他们之间的速度-时间关系, 并保留匹配程度高的组合.
2. Introduction
MOT的范式有两种(当然不完全是这两种), 一是tracking-by-detection, 二是tracking-by-regression. 前者是根据检测器的结果, 将检测与轨迹做关联; 而后者往往是检测器提供检测结果之外, 还预测目标的偏移(比如CenterTrack), 也就是直接回归得到目标的新位置, 这样就不需要额外的关联过程. 本文的方法是tracking-by-detection的方法.
不论哪种范式, 都需要处理短时和长时关联的问题. 对于短时关联, 往往是提取目标的运动或者外观特征. 但是作者认为在拥挤密集的场景中这样性能有限. 主要的原因是bbox太小, 提取的特征有限, 而且在密集场景中目标运动也是很复杂的. 对于长时关联, 如果依靠Re-ID特征去关联, 则同样有分辨率低等等问题, 如果像MeMOT这种采用记忆库的方式, 则有些耗时.
为此, 作者提出了MotionTrack, 对于短时关联, 学习目标之间的交互作用, 来预测拥挤场景下的复杂运动. 对于长时关联, 将轨迹的历史信息和当前的检测进行相关计算, 随后利用当前检测再对轨迹进行修正.
3. Method
下面对文章解决短时和长时关联的两个创新点逐一介绍.
3.1 短时关联–Interaction Module
假设第 t t t帧, 我们有检测集合 D t \mathcal{D}^t Dt, 现有轨迹集合为 T \mathbb{T} T, 共有 M M M个轨迹, 其中有 S S S个标记为丢失的轨迹, 集合为 T l o s t \mathbb{T}^{lost} Tlost. 我们计算 M M M个轨迹在第 t − 2 t-2 t−2到 t − 1 t-1 t−1帧的偏移量 O t ∈ R M × 4 \mathcal{O}^t\in\mathbb{R}^{M\times 4} Ot∈RM×4, 每一行分别表示中心点xy和高宽的偏移量. 随后我们将偏移量和绝对位置坐标concat起来, 得到 I t ∈ R M × 8 I^t\in\mathbb{R}^{M\times 8} It∈RM×8.
随后, 我们利用自注意力机制, 得到每个轨迹之间运动的影响, 如下式所示:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-1.png)
其中
W
W
W代表权重,
d
d
d是维数. 这个与Transformer里的自注意力是基本相似的.
于是我们得到了注意力矩阵 A a t t e ∈ R M × M A^{atte}\in\mathbb{R}^{M\times M} Aatte∈RM×M, 这个矩阵中的每个元素表示的就是两个轨迹间运动趋势的影响程度.
这其实是社会力模型的一种表示, 传统的社会力模型是手工设计特征, 本文(以及后期的多数方法)都是用深度学习的方式直接学习.
为了更好地表示群体行为, 作者采用非对称卷积(简单来说, 就是采用 1 × n 1\times n 1×n或者 n × 1 n\times 1 n×1的卷积核). 因为在这个问题中, 采用这样的卷积核代表的可以是一些轨迹对一个轨迹的影响, 也就是群体建模了. 这一步的公式如下:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-2.png)
随后, 我们只保留大于
ξ
\xi
ξ的元素, 如下所示:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-3.png)
其中 s g n sgn sgn是符号函数, 圆圈加点是Hadamard积, 也就是逐元素乘积.
最后, 我们利用偏移量 O t O^t Ot, 和表示轨迹间相互影响的矩阵 A a d j c A^{adjc} Aadjc输入到一个GCN和MLP后预测当前帧的偏移量:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-4.png)
其中
W
G
W^G
WG是图网络的权重.
3.2 长时关联–Refined Module
我们将预测的轨迹的位置和检测进行IoU匹配(最简单的匹配方式), 如果匹配完, 还有 U U U个检测和 S S S个轨迹没有匹配, 则进入到Refined Module模块.具体地, 剩余的检测集合记为 D r e s t ∈ R U × 5 D^{rest}\in\mathbb{R}^{U\times 5} Drest∈RU×5, 5表示的分别是时间和 x y w h xywh xywh坐标. 我们保留30帧历史轨迹的信息, 因此仍未匹配的轨迹集合记为 T l o s t ∈ R S × 30 × 5 T^{lost}\in\mathbb{R}^{S\times 30 \times 5} Tlost∈RS×30×5, 我们对于 T l o s t T^{lost} Tlost的第二维和第三维分别采用非对称卷积, 得到新的特征, 如下:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-5.png)
对第二维采用卷积的意义是对于每个轨迹, 学习时间维上的关联; 对第三维采用卷积的意义是对不同轨迹, 学习位置间的影响.
随后对于检测, 将当前位置和最后一次的位置concat起来, 变成 D r e s t ^ ∈ R U × 10 \hat{D^{rest}}\in\mathbb{R}^{U \times 10} Drest^∈RU×10, 随后将10升维成D:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-6.png)
其中
F
d
e
t
e
∈
R
U
×
D
F^{dete}\in\mathbb{R}^{U \times D}
Fdete∈RU×D
有一个疑问: 还没有匹配, 怎么确定检测的最后一次的位置是什么?
随后将 F d e t e F^{dete} Fdete和 F t r a j F^{traj} Ftraj结合起来, 变成 F ∈ R S × U × 2 D F\in\mathbb{R}^{S \times U \times 2D} F∈RS×U×2D, 这样我们对第三维做MLP+sigmoid, 就可以得到轨迹和检测之间的相似度得分(相关度) C c o r r ∈ R S × U C^{corr}\in\mathbb{R}^{S \times U} Ccorr∈RS×U, 之后将 C c o r r C^{corr} Ccorr作为代价矩阵, 用贪心算法就可以得到匹配.
得到匹配后, 我们要利用现有的检测来修正丢失轨迹的位置, 采用简单的线性模型即可:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-7.png)
3.3 整体流程
再看下面的流程图, 就比较明了了:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-8.png)
3.4 训练
以前做笔记, 不注重是怎么训练的, 其实这是很重要的一部分…
对于Interaction Module, 根据预测出的偏移量计算绝对坐标, 并采用IoU损失:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-9.png)
具体地, 采用相邻的三帧作为一个sample, 前两帧是网络的输入, 预测出的第三帧位置用来计算损失.
对于Refined Module, 对所有的真值轨迹进行提取, 并且随机进行两两组合, 一种组合方式作为一个训练集, 然后对轨迹和检测进行采样, 看看这个网络预测出的检测是否属于该轨迹. 这是个分类问题, 因此采用交叉熵损失:
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-10.png)
4. 效果与评价
![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking,读文献,MOT,多目标跟踪,论文阅读,深度学习,机器学习,目标跟踪,人工智能](https://imgs.yssmx.com/Uploads/2023/07/597527-11.png)
总体来说, 效果确实是很好的.文章来源:https://www.toymoban.com/news/detail-597527.html
这篇文章比较"大力出奇迹", 堆了self-attention, 堆了GCN, 也用了相关运算这种在MOT里也比较惯常的做法, 亮点是从社会力模型的角度讲故事, 而且用网络代替Kalman预测位置也许具有更好的效果.文章来源地址https://www.toymoban.com/news/detail-597527.html
到了这里,关于[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!