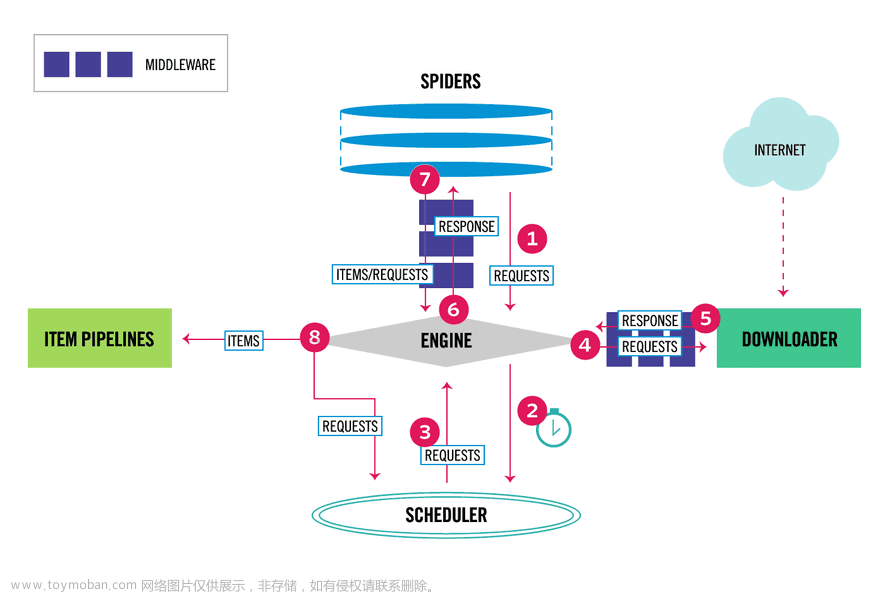
Scrapy是一款强大的Python网络爬虫框架,它可以帮助你快速、简洁地编写爬虫程序,处理数据抓取、处理和存储等复杂问题。
1. 安装Scrapy
在开始使用Scrapy之前,你需要先将其安装在你的系统中。你可以使用Python的包管理器pip来安装Scrapy:
pip install Scrapy
2. 创建一个Scrapy项目
Scrapy使用一个明确的项目结构来管理爬虫。你可以使用以下命令来创建一个新的Scrapy项目:
scrapy startproject projectname
这将创建一个新的目录,名为"projectname",其中包含了Scrapy项目的基本结构。
3. 创建一个Spider
Spider是Scrapy用来定义如何爬取特定网站的类。要创建一个新的Spider,你可以在"spiders"目录下创建一个新的Python文件。以下是一个基本的Spider的例子:
import scrapy
class ExampleSpider(scrapy.Spider):
name = "example"
start_urls = [
'http://example.com',
]
def parse(self, response):
self.log('Visited %s' % response.url)
这个Spider将会访问"example.com",然后在日志中记录访问的URL。
4. 运行Spider
你可以使用以下命令来运行你的Spider:
scrapy crawl example
"example"是你在Spider中定义的name。
5. 解析页面内容
Scrapy的Response对象提供了一些方法来提取页面内容。例如,你可以使用CSS选择器或XPath选择器来选择页面中的元素:
def parse(self, response):
title = response.css('title::text').get()
self.log('Title: %s' % title)
这个例子将会提取页面的标题,然后在日志中记录。
6. 存储结果
你可以使用Scrapy的Item和Item Pipeline来存储你的爬取结果。Item是保存爬取数据的容器,而Item Pipeline则是处理和存储Item的组件。
首先,你需要在items.py文件中定义你的Item:
import scrapy
class ExampleItem(scrapy.Item):
title = scrapy.Field()
然后,在你的Spider中,返回这个Item的实例:
def parse(self, response):
item = ExampleItem()
item['title'] = response.css('title::text').get()
return item
最后,定义一个Item Pipeline来存储这个Item:
class ExamplePipeline(object):
def process_item(self, item, spider):
print('Title: %s' % item['title'])
return item
并在settings.py文件中启用这个Item Pipeline:
ITEM_PIPELINES = {'projectname.pipelines.ExamplePipeline': 1}
这样,每次爬取到一个Item,都会打印出其标题。
以上就是Scrapy框架的基本使用。你可以根据你的需求,使用Scrapy提供的各种功能和选项,来编写更复杂的爬虫。
推荐阅读:
https://mp.weixin.qq.com/s/dV2JzXfgjDdCmWRmE0glDA
https://mp.weixin.qq.com/s/an83QZOWXHqll3SGPYTL5g文章来源:https://www.toymoban.com/news/detail-598070.html
![[爬虫]3.4.1 Scrapy框架的基本使用](https://imgs.yssmx.com/Uploads/2023/07/598070-1.jpg) 文章来源地址https://www.toymoban.com/news/detail-598070.html
文章来源地址https://www.toymoban.com/news/detail-598070.html
到了这里,关于[爬虫]3.4.1 Scrapy框架的基本使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!