AUTOMATIC1111 GUI: A Beginner's Guide - Stable Diffusion ArtAUTOMATIC1111 (A1111 for short) Stable Diffusion webui is the de facto GUI for advanced users. Thanks to the passionate community, most new features come to![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://i0.wp.com/stable-diffusion-art.com/wp-content/uploads/2022/12/favicon-32x32-1.png?fit=32%2C32&ssl=1) https://stable-diffusion-art.com/automatic1111/#Text-to-image_tab1.参数
https://stable-diffusion-art.com/automatic1111/#Text-to-image_tab1.参数
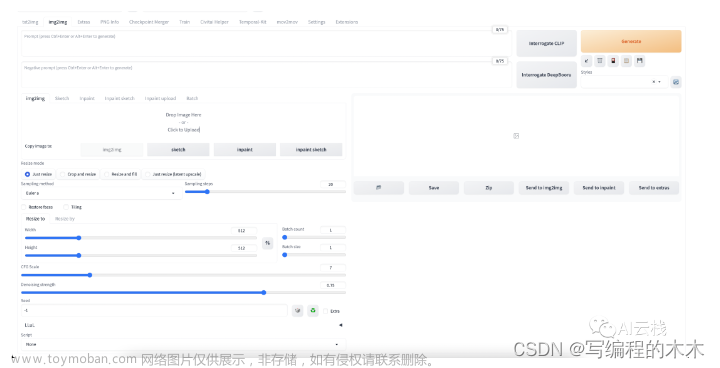
id_task='task(w9j5f4nn7lpfojk)',
mode=0,
prompt='a highly detailed tower designed by Zaha hadid with few metal and lots of glass,roads around with much traffic,in a city with a lot of greenery,aerial view, stunning sunny lighting, foggy atmosphere, vivid colors, Photo-grade rendering, Realistic style,8k,high res,highly detialed, ray tracing,vray render,masterpiece, best quality,rendered by Mir. and Brick visual',
negative_prompt='',
prompt_styles=[],
init_img=Image.open(),
sketch=None, # 可以勾画初始草图
init_img_with_mask=None,
inpaint_color_sketch=None,
inpaint_color_sketch_orig=None,
init_img_inpaint=None,
init_mask_inpaint=None,
steps=20,
sampler_index=0,
mask_blur=4,
mask_alpha=0,
inpainting_fill=1,
restore_faces=False,
tiling=False,
n_iter=1,
batch_size=1,
cfg_scale=7,
image_cfg_scale=1.5,
denoising_strength=0.75,# 控制图像变化的程度,如果=0,没有任何变化,如果=1,则新图像不会跟随输入图像,0.75是个很好的起点
seed=-1,
subseed=-1,
subseed_strength=0,
seed_resize_from_h=0,
seed_resize_from_w=0,
seed_enable_extras=False,
selected_scale_tab=0,
height=512,
width=512,
scale_by=1,
resize_mode=0, # 0(just resize):缩放输入图像以适应新的图像尺寸,会拉伸或者挤压图像,1(crop and resize):使画布适应输入图像,多余部分删除,保留原始图像的纵横比,3(resize and fill):将输入图像适应画布,额外部分用输入图像平均颜色填充,保留纵横比,4(just resize(latent upscale)):类似于just resize,但缩放是在隐空间中完成,使用>0.5的denoising strength以避免图像模糊。
inpaint_full_res=0,
inpaint_full_res_padding=32,
inpainting_mask_invert=0,
img2img_batch_input_dir="",
img2img_batch_output_dir='',
img2img_batch_inpaint_mask_dir='',
override_settings_texts=[]![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://imgs.yssmx.com/Uploads/2023/07/598567-1.png)
![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://imgs.yssmx.com/Uploads/2023/07/598567-2.png)
![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://imgs.yssmx.com/Uploads/2023/07/598567-3.png)
![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://imgs.yssmx.com/Uploads/2023/07/598567-4.png)
![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://imgs.yssmx.com/Uploads/2023/07/598567-5.png)
inpaint upload:允许上传单独的mask,而不是绘制。
![[linux-sd-webui]之img2img,大模型、多模态和生成,计算机视觉,opencv,人工智能](https://imgs.yssmx.com/Uploads/2023/07/598567-6.png)
main.py文章来源:https://www.toymoban.com/news/detail-598567.html
import sys
import logging
logging.getLogger("xformers").addFilter(lambda record: 'A matching Triton is not available' not in record.getMessage())
from modules import paths, timer, import_hook, errors
startup_timer = timer.Timer()
from modules import shared, devices, sd_samplers, upscaler, extensions, localization, ui_tempdir, ui_extra_networks
import modules.scripts
import modules.sd_models
import modules.img2img
from PIL import Image
from modules.shared import cmd_opts
def initialize():
extensions.list_extensions()
localization.list_localizations(cmd_opts.localizations_dir)
startup_timer.record("list extensions")
modules.sd_models.setup_model() # 加载模型
startup_timer.record("list SD models")
modules.scripts.load_scripts()
startup_timer.record("load scripts")
try:
modules.sd_models.load_model()
except Exception as e:
errors.display(e, "loading stable diffusion model")
print("", file=sys.stderr)
print("Stable diffusion model failed to load, exiting", file=sys.stderr)
exit(1)
startup_timer.record("load SD checkpoint")
def webui():
initialize()
image, _, _, _ = modules.img2img.img2img(
id_task='task(w9j5f4nn7lpfojk)',
mode=0,
prompt='a highly detailed tower designed by Zaha hadid with few metal and lots of glass,roads around with much traffic,in a city with a lot of greenery,aerial view, stunning sunny lighting, foggy atmosphere, vivid colors, Photo-grade rendering, Realistic style,8k,high res,highly detialed, ray tracing,vray render,masterpiece, best quality,rendered by Mir. and Brick visual',
negative_prompt='',
prompt_styles=[],
init_img=Image.open(),
sketch=None,
init_img_with_mask=None,
inpaint_color_sketch=None,
inpaint_color_sketch_orig=None,
init_img_inpaint=None,
init_mask_inpaint=None,
steps=20,
sampler_index=0,
mask_blur=4,
mask_alpha=0,
inpainting_fill=1,
restore_faces=False,
tiling=False,
n_iter=1,
batch_size=1,
cfg_scale=7,
image_cfg_scale=1.5,
denoising_strength=0.75,
seed=-1,
subseed=-1,
subseed_strength=0,
seed_resize_from_h=0,
seed_resize_from_w=0,
seed_enable_extras=False,
selected_scale_tab=0,
height=512,
width=512,
scale_by=1,
resize_mode=0,
inpaint_full_res=0,
inpaint_full_res_padding=32,
inpainting_mask_invert=0,
img2img_batch_input_dir="",
img2img_batch_output_dir='',
img2img_batch_inpaint_mask_dir='',
override_settings_texts=[]
)
for i in range(len(image)):
image[i].save(f"{i}.png")
if __name__ == "__main__":
webui()
modules/img2img.py文章来源地址https://www.toymoban.com/news/detail-598567.html
import math
import os
import sys
import traceback
import numpy as np
from PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops, UnidentifiedImageError
from modules import devices, sd_samplers
from modules.generation_parameters_copypaste import create_override_settings_dict
from modules.processing import Processed, StableDiffusionProcessingImg2Img, process_images
from modules.shared import opts, state
import modules.shared as shared
import modules.processing as processing
from modules.ui import plaintext_to_html
import modules.images as images
import modules.scripts
def process_batch(p, input_dir, output_dir, inpaint_mask_dir, args):
processing.fix_seed(p)
images = shared.listfiles(input_dir)
is_inpaint_batch = False
if inpaint_mask_dir:
inpaint_masks = shared.listfiles(inpaint_mask_dir)
is_inpaint_batch = len(inpaint_masks) > 0
if is_inpaint_batch:
print(f"\nInpaint batch is enabled. {len(inpaint_masks)} masks found.")
print(f"Will process {len(images)} images, creating {p.n_iter * p.batch_size} new images for each.")
save_normally = output_dir == ''
p.do_not_save_grid = True
p.do_not_save_samples = not save_normally
state.job_count = len(images) * p.n_iter
for i, image in enumerate(images):
state.job = f"{i+1} out of {len(images)}"
if state.skipped:
state.skipped = False
if state.interrupted:
break
try:
img = Image.open(image)
except UnidentifiedImageError:
continue
# Use the EXIF orientation of photos taken by smartphones.
img = ImageOps.exif_transpose(img)
p.init_images = [img] * p.batch_size
if is_inpaint_batch:
# try to find corresponding mask for an image using simple filename matching
mask_image_path = os.path.join(inpaint_mask_dir, os.path.basename(image))
# if not found use first one ("same mask for all images" use-case)
if not mask_image_path in inpaint_masks:
mask_image_path = inpaint_masks[0]
mask_image = Image.open(mask_image_path)
p.image_mask = mask_image
proc = modules.scripts.scripts_img2img.run(p, *args)
if proc is None:
proc = process_images(p)
for n, processed_image in enumerate(proc.images):
filename = os.path.basename(image)
if n > 0:
left, right = os.path.splitext(filename)
filename = f"{left}-{n}{right}"
if not save_normally:
os.makedirs(output_dir, exist_ok=True)
if processed_image.mode == 'RGBA':
processed_image = processed_image.convert("RGB")
processed_image.save(os.path.join(output_dir, filename))
def img2img(id_task: str, mode: int, prompt: str, negative_prompt: str, prompt_styles, init_img, sketch, init_img_with_mask, inpaint_color_sketch, inpaint_color_sketch_orig, init_img_inpaint, init_mask_inpaint, steps: int, sampler_index: int, mask_blur: int, mask_alpha: float, inpainting_fill: int, restore_faces: bool, tiling: bool, n_iter: int, batch_size: int, cfg_scale: float, image_cfg_scale: float, denoising_strength: float, seed: int, subseed: int, subseed_strength: float, seed_resize_from_h: int, seed_resize_from_w: int, seed_enable_extras: bool, selected_scale_tab: int, height: int, width: int, scale_by: float, resize_mode: int, inpaint_full_res: bool, inpaint_full_res_padding: int, inpainting_mask_invert: int, img2img_batch_input_dir: str, img2img_batch_output_dir: str, img2img_batch_inpaint_mask_dir: str, override_settings_texts, *args):
args = (
(0, '<ul>\n<li><code>CFG Scale</code> should be 2 or lower.</li>\n</ul>\n', True, True, '', '', True, 50, True, 1, 0, False, 4, 0.5, 'Linear', 'None', '<p style="margin-bottom:0.75em">Recommended settings: Sampling Steps: 80-100, Sampler: Euler a, Denoising strength: 0.8</p>', 128, 8, ['left', 'right', 'up', 'down'], 1, 0.05, 128, 4, 0, ['left', 'right', 'up', 'down'], False, False, 'positive', 'comma', 0, False, False, '', '<p style="margin-bottom:0.75em">Will upscale the image by the selected scale factor; use width and height sliders to set tile size</p>', 64, 0, 2, 1, '', [], 0, '', [], 0, '', [], True, False, False, False, 0))
override_settings = create_override_settings_dict(override_settings_texts)
is_batch = mode == 5
if mode == 0: # img2img
image = init_img.convert("RGB")
mask = None
elif mode == 1: # img2img sketch
image = sketch.convert("RGB")
mask = None
elif mode == 2: # inpaint
image, mask = init_img_with_mask["image"], init_img_with_mask["mask"]
alpha_mask = ImageOps.invert(image.split()[-1]).convert('L').point(lambda x: 255 if x > 0 else 0, mode='1')
mask = ImageChops.lighter(alpha_mask, mask.convert('L')).convert('L')
image = image.convert("RGB")
elif mode == 3: # inpaint sketch
image = inpaint_color_sketch
orig = inpaint_color_sketch_orig or inpaint_color_sketch
pred = np.any(np.array(image) != np.array(orig), axis=-1)
mask = Image.fromarray(pred.astype(np.uint8) * 255, "L")
mask = ImageEnhance.Brightness(mask).enhance(1 - mask_alpha / 100)
blur = ImageFilter.GaussianBlur(mask_blur)
image = Image.composite(image.filter(blur), orig, mask.filter(blur))
image = image.convert("RGB")
elif mode == 4: # inpaint upload mask
image = init_img_inpaint
mask = init_mask_inpaint
else:
image = None
mask = None
# Use the EXIF orientation of photos taken by smartphones.
if image is not None:
image = ImageOps.exif_transpose(image)
if selected_scale_tab == 1:
assert image, "Can't scale by because no image is selected"
width = int(image.width * scale_by)
height = int(image.height * scale_by)
assert 0. <= denoising_strength <= 1., 'can only work with strength in [0.0, 1.0]'
p = StableDiffusionProcessingImg2Img(
sd_model=shared.sd_model,
outpath_samples=opts.outdir_samples or opts.outdir_img2img_samples,
outpath_grids=opts.outdir_grids or opts.outdir_img2img_grids,
prompt=prompt,
negative_prompt=negative_prompt,
styles=prompt_styles,
seed=seed,
subseed=subseed,
subseed_strength=subseed_strength,
seed_resize_from_h=seed_resize_from_h,
seed_resize_from_w=seed_resize_from_w,
seed_enable_extras=seed_enable_extras,
sampler_name=sd_samplers.samplers_for_img2img[sampler_index].name,
batch_size=batch_size,
n_iter=n_iter,
steps=steps,
cfg_scale=cfg_scale,
width=width,
height=height,
restore_faces=restore_faces,
tiling=tiling,
init_images=[image],
mask=mask,
mask_blur=mask_blur,
inpainting_fill=inpainting_fill,
resize_mode=resize_mode,
denoising_strength=denoising_strength,
image_cfg_scale=image_cfg_scale,
inpaint_full_res=inpaint_full_res,
inpaint_full_res_padding=inpaint_full_res_padding,
inpainting_mask_invert=inpainting_mask_invert,
override_settings=override_settings,
)
p.scripts = modules.scripts.scripts_img2img # scriptrunner
p.script_args = args
if shared.cmd_opts.enable_console_prompts:
print(f"\nimg2img: {prompt}", file=shared.progress_print_out)
if mask:
p.extra_generation_params["Mask blur"] = mask_blur
if is_batch:
assert not shared.cmd_opts.hide_ui_dir_config, "Launched with --hide-ui-dir-config, batch img2img disabled"
process_batch(p, img2img_batch_input_dir, img2img_batch_output_dir, img2img_batch_inpaint_mask_dir, args)
processed = Processed(p, [], p.seed, "")
else:
processed = modules.scripts.scripts_img2img.run(p, *args)
if processed is None:
processed = process_images(p)
p.close()
shared.total_tqdm.clear()
generation_info_js = processed.js()
if opts.samples_log_stdout:
print(generation_info_js)
if opts.do_not_show_images:
processed.images = []
return processed.images, generation_info_js, plaintext_to_html(processed.info), plaintext_to_html(processed.comments)
到了这里,关于[linux-sd-webui]之img2img的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!