基础配置
#1 了解
BOT_NAME = "firstscrapy" #项目名字,整个爬虫名字
#2 爬虫存放位置 了解
SPIDER_MODULES = ["firstscrapy.spiders"]
NEWSPIDER_MODULE = "firstscrapy.spiders"#3 记住 是否遵循爬虫协议,一般都设为False
ROBOTSTXT_OBEY = False
# 4 记住
USER_AGENT = "firstscrapy (+http://www.yourdomain.com)"#5 记住 日志级别
LOG_LEVEL='ERROR'#6 记住 DEFAULT_REQUEST_HEADERS 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
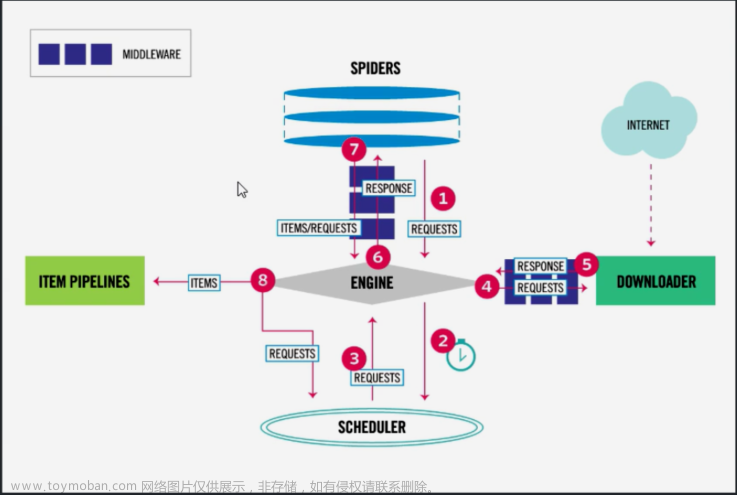
}#7 记住 后面学 SPIDER_MIDDLEWARES 爬虫中间件
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
#8 后面学 DOWNLOADER_MIDDLEWARES 下载中间件
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}#9 后面学 ITEM_PIPELINES 持久化配置
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
高级配置(提高爬虫效率--scarpy框架)
#1 增加并发:默认16
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100。#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False文章来源:https://www.toymoban.com/news/detail-598708.html# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s文章来源地址https://www.toymoban.com/news/detail-598708.html
到了这里,关于scrapy----setting配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!