文章来源地址https://www.toymoban.com/news/detail-598875.html
文章来源地址https://www.toymoban.com/news/detail-598875.html
1. 数据建模
1.1. 多上下文编码算法背后的基本概念
1.1.1. 会考虑最后观察到的几个符号以确定当前符号的理想编码位数
1.1.2. 英语中的字母组合如何影响后面字母的出现概率
1.1.3. 基于统计观察的相邻关系,通常也被称作“预测”编码器
1.2. 马尔可夫链(Markov chain)
1.2.1. 一种离散的随机过程,其未来的状态只取决于现在,而与过去的历史无关
1.2.2. 马尔可夫提出的事件选择概率(probabilistic event selection)这一概念,与当时概率界的主流观点格格不入,当时的概率模型大都与抛掷硬币或掷骰子有关
1.2.3. 马尔可夫链则帮助我们提出了关联概率的问题
1.2.3.1. 如果今天多云,那么明后两天会下雨的概率是多少?
1.2.4. 统计编码算法就是一阶马尔可夫链
1.2.5. 没有人真正地使用马尔可夫链来压缩数据
1.2.5.1. 要使马尔可夫链算法变得实用,就必须要解决内存消耗问题与计算性能问题,即使用最佳链来编码
1.3. 部分匹配预测算法
1.3.1. prediction by partial matching,PPM
1.3.2. 该算法在内存消耗与计算性能方面表现都还不错
1.3.3. PPM算法(模型)的大部分优化工作是在处理输入流中那些之前没有出现过的字符
1.3.4. 那些没有见过的符号应该赋什么样的概率值呢?这通常被称为零频问题(zero-frequency problem)
1.4. 上下文混合算法
1.4.1. context mixing
1.4.2. 即为了找出给定符号的最佳编码,我们会使用两个或者更多的统计模型
1.4.3. PAQ 系列算法
1.4.3.1. 在PPMZ算法中,对于符号如何去响应匹配,人们尝试了多种类型的上下文
1.4.4. 数据的相邻性与它的最佳编码方式有关
1.4.5. 线性混合(linear mixing),它是将各个模型的预测值加权平均的过程,最终的值则取决于证据权重
1.4.6. 逻辑混合使用了神经网络(你没有看错,就是人工智能中的神经网络)来更新权重,而更新的依据则是哪个模型在过去给出了最准确的预测
1.4.6.1. 缺点是在进行数据压缩时,它需要消耗大量的内存,同时运行的时间也较长
1.4.7. 由于需要大量的内存和运行时间,这就使得上下文混合算法很难适用于移动设备
2. 通用压缩工具
2.1. 设计用来压缩除多媒体数据以外的其他数据
2.2. 像DEFLATE、GZIP、BZIP2、LZMA和PAQ这些算法,都是将各种无损转换结合起来,用来压缩诸如文本、源代码、序列化数据以及二进制内容等其他不能使用有损压缩工具压缩的非多媒体文件
2.3. 谷歌对GZIP算法的改进
2.3.1. Snappy
2.3.2. Zopfli
2.3.3. Gipfeli
2.3.4. Brotli
2.3.4.1. 标准的HTTP协议栈允许数据包使用GZIP和BZIP编码,现在又多了一种Brotli
3. 序列化
3.1. 将高级数据对象转化为二进制字符串的过程(与之相反的过程则称为反序列化)
3.2. 序列化内容是网络应用程序处理第二多的数据格式
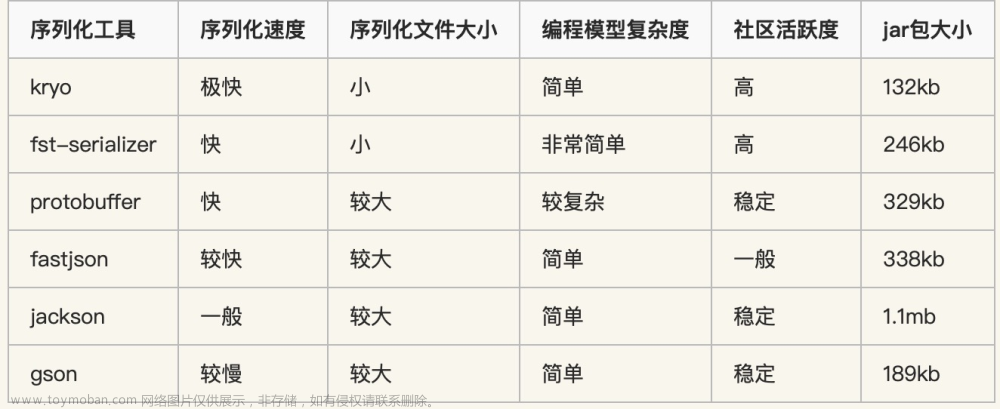
3.3. 两种最常见的序列化格式就是JSON和XML
3.3.1. 可读文本
3.3.2. 解码时间长
3.3.2.1. 字符串的输入必须经过强力操作才能转化为内存对象
3.3.2.1.1. 将ASCII符号转换为整数就不那么容易
3.3.2.2. 在加载期间将数据保存在临时内存里并非总是高效的
3.3.2.3. 对旧格式的兼容也会使得编码和解码变慢
3.4. 将图像压缩和数据序列化的工作做好,有助于应用程序安全度过其生命周期
4. 更小的序列化数据
4.1. 使用二进制序列化格式
4.1.1. Protobufs
4.1.2. Cap'n Proto
4.1.3. Flatbuffers
4.1.4. 处于文件大小和解压时间平衡的位置
4.1.5. BSON
4.1.6. MSGPACK
4.1.7. 特点
4.1.7.1. 保留了JSON的模式
4.1.7.2. 在编码时能提供二进制的大小
4.1.8. 与人类可读格式相比,它们可以产生更好的压缩效果
4.2. 重构列表以获得更好的压缩
4.2.1. 将结构的数组转换为数组的结构极为重要
4.2.1.1. 数组结构转换为某个给定属性的所有值都包含在一个数组中,并紧密地放在一起
4.3. 组织数据以便高效获取
4.3.1. json
{
"messages" : [{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "hello
hello",
"date" : "123"
},
{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "how are you",
"date" : "124"
},
{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "you there",
"date" : "125"
},
{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "hello
hello",
"date" : "126"
}]
}
4.3.2. 与其返回分层的数据,不如返回规范化的数据
4.3.2.1. json
{
"users" : {
"1" : {
"user_id" : 1,
"user_name" : "claude",
....
}
},
"messages" : [{
"from" : 1,
"text" : "hello
hello",
"date" : "123"
},
{
"from" : 1,
"text" : "how are you",
"date" : "124"
},
{
"from" : 1,
"text" : "you there",
"date" : "125"
},
{
"from" : 1,
"text" : "hello
hello",
"date" : "126"
}]
}
4.3.3. 还可以做得更好,使数据完全不再分层
4.3.3.1. json
{
"users" : {
"1" : {
"user_id" : 1,
"user_name" : "claude",
....
}
},
"messages" : {
"from": [1,1,1,1],
"text": [ "hello
hello","how are you","you there","hello
hello"],
}
4.3.4. 客户端对需要显示的数据掌握的信息越多,效率就越高
4.3.5. 应用程序决定缓存或者删除哪些数据
4.4. 将数据切分为适当的压缩格式
4.4.1. 大的数据类型单独分开然后再压缩,产生的压缩效果肯定要比将它们放在文件中后再压缩好
5. 数据压缩与盈利
5.1. 用户获取与保持
5.1.1. 如果你将产品页的数据压得越小,网页加载的速度就会越快,那么用户购买以及下次继续访问的可能性就会增大
5.2. 运行成本
5.2.1. 即使云技术已经标准化且其费用在大幅下降,带宽和存储仍然是大公司面临的重要财务挑战
5.2.2. 数据量更小,就意味着更小的出站流量成本、更小的入站流量成本以及更小的存储成本
5.3. 提前规划
5.3.1. 移动页面加速(Accelerated Mobile Pages,AMP)这一全新的框架,专门用来减小站点加载时依赖的图形、图像文件的大小,在带宽有限的情况下为用户提供更精简、加载速度更快的内容
5.4. 在连接速度同样慢的情况下,文件越小就意味着下载需要的时间会越短,消耗的电量也会越少
5.4.1. 用户能快速看到商品的图像
5.5. 一切都是需要用户支付费用的
5.5.1. 大多数人要为数据付费,以兆字节为单位,并且付费惊人
6. 下一步技术的思考
6.1. 2G网络的传输速度大约为0.021 MB/s
6.2. GZIP的压缩速度则可达61 MB/s
6.3. 即使GZIP的压缩速度降为原来的十分之一,压缩1 MB的速度仍然比通过网络传输要快
6.4. 与投入数百万美元升级网络硬件相比,投资更好的压缩解压编解码器要划算得多
文章来源:https://www.toymoban.com/news/detail-598875.html
到了这里,关于读数据压缩入门笔记10_通用压缩和序列化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!