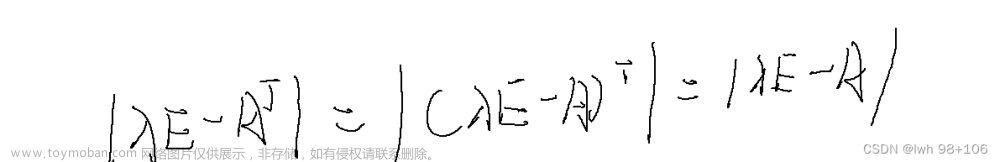之前把广义特征向量放在特征值的第一篇文章里,我后来觉得对初学者太不友好了,所以剪出来,单独作为一篇文章。
1 特征空间
前面说过矩阵不过是把自己的特征向量给延长或缩短了,为了求特征值和特征向量,我们有以下的方程:
(
A
−
λ
I
)
v
=
0
(A-\lambda I)v=0
(A−λI)v=0
把某个特征值代进去,得到的
A
−
λ
I
A-\lambda I
A−λI是一个矩阵,这个矩阵会把对应的特征向量变成0向量。这群向量构成了一个空间,这个空间就叫做特征空间。
可以举个例子:
A
=
(
2.0
1.0
−
1.0
1.0
2.0
−
1.0
−
1.0
−
1.0
2.0
)
A
−
λ
I
=
(
1.0
1.0
−
1.0
1.0
1.0
−
1.0
−
1.0
−
1.0
1.0
)
A=\begin{pmatrix} 2.0 & 1.0 & -1.0\\ 1.0 & 2.0 & -1.0\\ -1.0 & -1.0 & 2.0 \end{pmatrix}\\ A-\lambda I=\begin{pmatrix} 1.0 & 1.0 & -1.0\\ 1.0 & 1.0 & -1.0\\ -1.0 & -1.0 & 1.0 \end{pmatrix}\\
A=
2.01.0−1.01.02.0−1.0−1.0−1.02.0
A−λI=
1.01.0−1.01.01.0−1.0−1.0−1.01.0
然后我们根据定义解下齐次线性方程组就可以了。
(
1.0
1.0
−
1.0
1.0
1.0
−
1.0
−
1.0
−
1.0
1.0
)
∼
(
1.0
1.0
−
1.0
0.0
0.0
0.0
0.0
0.0
0.0
)
∴
v
=
k
1
(
1
0
1
)
+
k
2
(
0
1
1
)
\begin{pmatrix} 1.0 & 1.0 & -1.0\\ 1.0 & 1.0 & -1.0\\ -1.0 & -1.0 & 1.0 \end{pmatrix} \sim \begin{pmatrix} 1.0 & 1.0 & -1.0\\ 0.0 & 0.0 & 0.0\\ 0.0 & 0.0 & 0.0 \end{pmatrix}\\ \therefore v=k_1\begin{pmatrix}1\\0\\1\end{pmatrix}+k_2\begin{pmatrix}0\\1\\1\end{pmatrix}
1.01.0−1.01.01.0−1.0−1.0−1.01.0
∼
1.00.00.01.00.00.0−1.00.00.0
∴v=k1
101
+k2
011
所以这个特征空间的两个基就求出来了。我们再试一下下一个特征值4:
A
=
(
2.0
1.0
−
1.0
1.0
2.0
−
1.0
−
1.0
−
1.0
2.0
)
A
−
λ
I
=
(
−
2.0
1.0
−
1.0
1.0
−
2.0
−
1.0
−
1.0
−
1.0
−
2.0
)
A=\begin{pmatrix} 2.0 & 1.0 & -1.0\\ 1.0 & 2.0 & -1.0\\ -1.0 & -1.0 & 2.0 \end{pmatrix}\\ A-\lambda I=\begin{pmatrix} -2.0 & 1.0 & -1.0\\ 1.0 & -2.0 & -1.0\\ -1.0 & -1.0 & -2.0 \end{pmatrix}\\
A=
2.01.0−1.01.02.0−1.0−1.0−1.02.0
A−λI=
−2.01.0−1.01.0−2.0−1.0−1.0−1.0−2.0
同样,解一下这个齐次方程组:
(
−
2.0
1.0
−
1.0
1.0
−
2.0
−
1.0
−
1.0
−
1.0
−
2.0
)
∼
(
−
2.0
1.0
−
1.0
0.0
1.0
1.0
0.0
0.0
0.0
)
∴
v
=
k
(
0
1
1
)
\begin{pmatrix} -2.0 & 1.0 & -1.0\\ 1.0 & -2.0 & -1.0\\ -1.0 & -1.0 & -2.0 \end{pmatrix} \sim \begin{pmatrix} -2.0 & 1.0 & -1.0\\ 0.0 & 1.0 & 1.0\\ 0.0 & 0.0 & 0.0 \end{pmatrix}\\ \therefore v=k\begin{pmatrix}0\\1\\1\end{pmatrix}
−2.01.0−1.01.0−2.0−1.0−1.0−1.0−2.0
∼
−2.00.00.01.01.00.0−1.01.00.0
∴v=k
011
这样两个特征值的特征空间就求出来了。
2 广义特征向量
有了特征向量和特征向量构成的特征空间,我们知道
A
−
λ
I
A-\lambda I
A−λI可以把特征空间里的向量变成0。我们再想想,
(
A
−
λ
I
)
2
(A-\lambda I)^2
(A−λI)2能不能把某个向量变成0呢?三次方呢?四次方呢?有了方向,数学家们就开始思考了,于是有了广义特征向量的定义:
(
A
−
λ
I
)
j
v
=
0
(A-\lambda I)^jv=0
(A−λI)jv=0
公式中v被成为广义特征向量generalized eigenvector,对于某个固定的v,上述公式中的
j
j
j的最小值是广义特征向量的下标index。毫无疑问,特征向量本身是一个j=1的广义特征向量。我们举个例子:
A
=
(
2
1
1
−
2
−
1
−
2
1
1
2
)
λ
=
1
A= \begin{pmatrix} 2 & 1 & 1\\ -2 & -1 & -2\\ 1 & 1 & 2 \end{pmatrix}\\ \lambda=1
A=
2−211−111−22
λ=1
以
λ
1
=
2
\lambda_1=2
λ1=2为例子,求它的特征方程:
A
=
(
3
1
1
−
2
0
−
2
1
1
3
)
A
−
2
I
=
(
1
1
1
−
2
−
2
−
2
1
1
1
)
∼
(
1
1
1
0
0
0
0
0
0
)
v
=
k
1
(
−
1
1
0
)
+
k
2
(
−
1
0
1
)
(
A
−
2
I
)
2
=
(
0
0
0
0
0
0
0
0
0
)
v
=
k
1
(
1
0
0
)
+
k
2
(
0
1
0
)
+
k
3
(
0
0
1
)
A=\begin{pmatrix} 3 & 1 & 1\\ -2 & 0 & -2\\ 1 & 1 & 3 \end{pmatrix} \\ A-2I= \begin{pmatrix} 1 & 1 & 1\\ -2 & -2 & -2\\ 1 & 1 & 1 \end{pmatrix} \sim \begin{pmatrix} 1 & 1 & 1\\ 0 & 0 & 0\\ 0 & 0 & 0 \end{pmatrix}\\ v=k_1\begin{pmatrix}-1\\1\\0\end{pmatrix}+k_2\begin{pmatrix}-1\\0\\1\end{pmatrix}\\ (A-2I)^2= \begin{pmatrix} 0 & 0 & 0\\ 0 & 0 & 0\\ 0 & 0 & 0 \end{pmatrix}\\ v=k_1\begin{pmatrix}1\\0\\0\end{pmatrix}+k_2\begin{pmatrix}0\\1\\0\end{pmatrix}+k_3\begin{pmatrix}0\\0\\1\end{pmatrix}\\
A=
3−211011−23
A−2I=
1−211−211−21
∼
100100100
v=k1
−110
+k2
−101
(A−2I)2=
000000000
v=k1
100
+k2
010
+k3
001
所以j到2时,再乘什么都是0矩阵了,广义特征向量就是任意向量,再乘方就没意义了。文章来源:https://www.toymoban.com/news/detail-599054.html
3 广义特征空间
对于上述的规律,我们总在j增大到一定程度后,广义特征向量所在的空间是不会增大的。所以对某个特定的特征值定义了以下空间:
E
j
(
λ
)
=
{
v
∣
(
A
−
λ
I
)
j
v
=
0
}
E_j(\lambda)=\{v|(A-\lambda I)^jv=0\}
Ej(λ)={v∣(A−λI)jv=0}
当
j
j
j无穷大时定义的空间
E
∞
(
λ
)
E_\infty(\lambda)
E∞(λ),被称为广义特征空间generalized eigenspace。但是也不要看到无穷就悲观,因为前面我们说了当j到一定程度时,
E
j
(
λ
)
E_j(\lambda)
Ej(λ)空间不再扩大,这个时候就等于广义特征空间,这时候的
j
j
j被称为广义特征向量最大下标maximum index of
a generalized eigenvector of A associated to λ,数学符号为
m
a
x
max
max-
i
n
d
(
λ
)
ind(\lambda)
ind(λ)。实际上
m
a
x
max
max-
i
n
d
(
λ
)
ind(\lambda)
ind(λ)等于该特征值最大约当块的行数。所以利用这个特性,可以快速确定矩阵的约当标准型。如下面的矩阵:
(
2
1
−
1
1
2
−
1
−
1
−
1
2
)
λ
1
=
λ
2
=
1
,
λ
3
=
4
\begin{pmatrix} 2 & 1 & -1\\ 1 & 2 & -1\\ -1 & -1 & 2 \end{pmatrix}\\ \lambda_1=\lambda_2=1,\lambda_3=4
21−112−1−1−12
λ1=λ2=1,λ3=4
它的约当标准型有两种可能:
(
1
1
0
0
1
0
0
0
4
)
o
r
(
1
0
0
0
1
0
0
0
4
)
\begin{pmatrix} 1 & 1 & 0\\ 0 & 1& 0\\ 0 & 0 & 4 \end{pmatrix}or \begin{pmatrix} 1 & 0 & 0\\ 0 & 1& 0\\ 0 & 0 & 4 \end{pmatrix}
100110004
or
100010004
那么到底是哪一种?这个时候就需要用特征空间了,求出
m
a
x
max
max-
i
n
d
(
1
)
ind(1)
ind(1)。那只能拿特征方程计算下呗:
A
−
λ
I
=
(
1
1
−
1
1
1
−
1
−
1
−
1
1
)
∼
(
1
1
−
1
0
0
0
0
0
0
)
(
A
−
λ
I
)
2
=
(
3
3
−
3
3
3
−
3
−
3
−
3
3
)
∼
(
1
1
−
1
0
0
0
0
0
0
)
A-\lambda I=\begin{pmatrix} 1 & 1 & -1\\ 1 & 1 & -1\\ -1 & -1 & 1 \end{pmatrix} \sim \begin{pmatrix} 1 & 1 & -1\\ 0 & 0 & 0\\ 0 & 0 & 0\end{pmatrix}\\ (A-\lambda I)^2=\begin{pmatrix} 3 & 3 & -3\\ 3 & 3 & -3\\ -3 & -3 & 3 \end{pmatrix}\sim \begin{pmatrix} 1 & 1 & -1\\ 0 & 0 & 0\\ 0 & 0 & 0 \end{pmatrix}\\
A−λI=
11−111−1−1−11
∼
100100−100
(A−λI)2=
33−333−3−3−33
∼
100100−100
特征方程的二次方并没有变成0矩阵,说明
m
a
x
{max}
max-
i
n
d
(
1
)
=
1
{ind}(1)=1
ind(1)=1,所以约当标准型为:
(
1
0
0
0
1
0
0
0
4
)
\begin{pmatrix} 1 & 0 & 0\\ 0 & 1& 0\\ 0 & 0 & 4 \end{pmatrix}
100010004
文章来源地址https://www.toymoban.com/news/detail-599054.html
到了这里,关于6.7 广义特征向量与特征空间的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!