Doker官网:Doker 多克
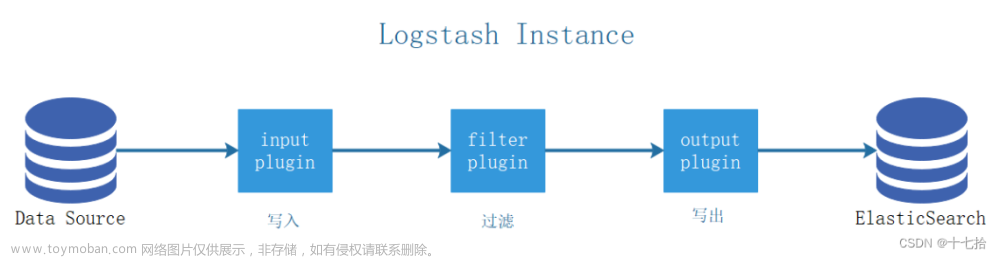
在存储您的第一个事件中,您创建了一个基本的 Logstash 管道来测试 Logstash 设置。在现实世界中,一个日志藏匿处 管道有点复杂:它通常有一个或多个输入、过滤器和输出插件。
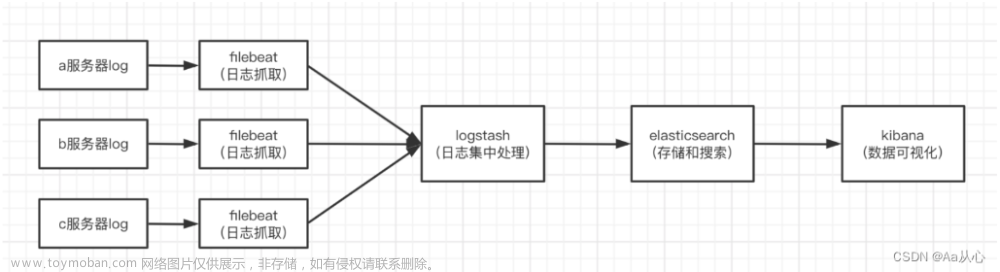
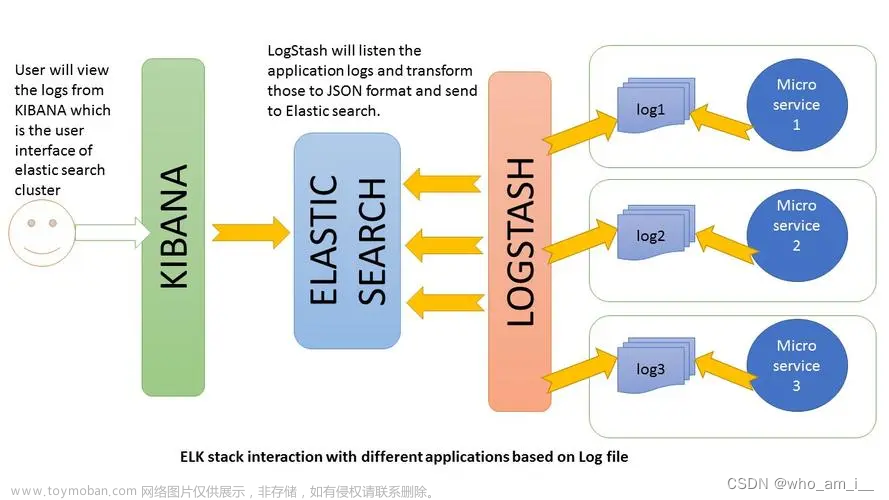
在本节中,您将创建一个 Logstash 管道,该管道使用 Filebeat 将 Apache Web 日志作为输入,解析这些日志 日志以从日志中创建特定的命名字段,并将解析后的数据写入 Elasticsearch 集群。而不是 在命令行定义管道配置时,您将在配置文件中定义管道
一、配置 Filebeat 以将日志行发送到 logstash
在创建 Logstash 管道之前,您需要将 Filebeat 配置为将日志行发送到 Logstash。 Filebeat 客户端是一个轻量级、资源友好的工具 从服务器上的文件收集日志,并将这些日志转发到 Logstash 实例进行处理。 Filebeat 专为可靠性和低延迟而设计。Filebeat 在主机上的资源占用量很小, 和 Beats 输入插件最大限度地减少了对 Logstash 的资源需求 实例。
默认的 Logstash 安装包括 Beats 输入插件。节拍 输入插件使 Logstash 能够从 Elastic Beats 框架接收事件,这意味着任何 Beat 写入 使用Beats框架,如Packetbeat和Metricbeat,也可以将事件数据发送到Logstash。
安装Filebeat后,您需要对其进行配置。打开位于Filebeat安装目录中的Filebeat.yml文件,并用以下行替换内容。确保路径指向您之前下载的示例Apache日志文件logstash-tutorial.log:
filebeat.inputs:
- type: log
paths:
- /path/to/file/logstash-tutorial.log (1)
output.logstash:
hosts: ["localhost:5044"](1)Filebeat处理的一个或多个文件的绝对路径。
保存更改。
为了保持配置简单,您不会像在现实世界中那样指定 TLS/SSL 设置 场景。
在数据源计算机上,使用以下命令运行 Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"
如果以 root 用户身份运行 Filebeat,则需要更改配置文件的所有权
Filebeat将尝试在端口5044上进行连接。在Logstash启动一个活动的Beats插件之前,该端口不会有任何答案,所以你看到的任何关于该端口连接失败的消息目前都是正常的。
二、为Filebeat Input配置Logstash
接下来,您创建一个Logstash配置管道,该管道使用Beats输入插件从Beats接收事件。
以下文本表示配置管道的骨架:
# The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}这个骨架是不起作用的,因为输入和输出部分没有定义任何有效的选项。
首先,将骨架配置管道复制并粘贴到主Logstash目录中名为firstpipeline.conf的文件中。
接下来,通过在第一个pipeline.conf文件的输入部分添加以下行,将Logstash实例配置为使用Beats输入插件:
beats {
port => "5044"
}稍后您将配置Logstash写入Elasticsearch。目前,您可以将以下行添加到输出部分,以便在运行Logstash时将输出打印到stdout:
stdout { codec => rubydebug }完成后,第一个pipeline.conf的内容应该如下所示:
input {
beats {
port => "5044"
}
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
stdout { codec => rubydebug }
}要验证您的配置,请运行以下命令:
bin/logstash -f first-pipeline.conf --config.test_and_exit
--config.test_and_exit选项解析配置文件并报告任何错误。
如果配置文件通过了配置测试,请使用以下命令启动Logstash:
--config.reload.automatic选项允许自动重新加载配置,这样您就不必每次修改配置文件时都停止并重新启动Logstash。
当Logstash启动时,您可能会看到一条或多条关于Logstash忽略pipelines.yml文件的警告消息。您可以放心地忽略此警告。pipelines.yml文件用于在单个Logstash实例中运行多个管道。对于这里显示的示例,您正在运行一个管道。
如果您的管道工作正常,您应该会看到一系列事件,如写入控制台的以下内容:
{
"@timestamp" => 2017-11-09T01:44:20.071Z,
"offset" => 325,
"@version" => "1",
"beat" => {
"name" => "My-MacBook-Pro.local",
"hostname" => "My-MacBook-Pro.local",
"version" => "6.0.0"
},
"host" => "My-MacBook-Pro.local",
"prospector" => {
"type" => "log"
},
"input" => {
"type" => "log"
},
"source" => "/path/to/file/logstash-tutorial.log",
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}
...三、使用Grok Filter Plugin解析Web日志
现在您有了一个可以从Filebeat读取日志行的工作管道。然而,您会注意到日志消息的格式并不理想。您需要分析日志消息,以便从日志中创建特定的命名字段。为此,您将使用grok过滤器插件。
grok过滤器插件是Logstash中默认可用的几个插件之一。有关如何管理Logstash插件的详细信息,请参阅插件管理器的参考文档。
grok过滤器插件使您能够将非结构化日志数据解析为结构化和可查询的数据。
因为grok过滤器插件在传入的日志数据中寻找模式,所以配置插件需要您决定如何识别用例感兴趣的模式。web服务器日志示例中的代表行如下所示:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png
HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"行开头的IP地址很容易识别,括号中的时间戳也是如此。要解析数据,可以使用%{COMEMBIDAPACHELOG}grok模式,该模式使用以下架构从Apache日志中构建行:
Information |
Field Name |
IP Address |
clientip |
User ID |
ident |
User Authentication |
auth |
timestamp |
timestamp |
HTTP Verb |
verb |
Request body |
request |
HTTP Version |
httpversion |
HTTP Status Code |
response |
Bytes served |
bytes |
Referrer URL |
referrer |
User agent |
agent |
编辑第一个pipeline.conf文件,并用以下文本替换整个过滤器部分:
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}完成后,第一个pipeline.conf的内容应该如下所示:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}保存您的更改。因为您已经启用了自动重新加载配置,所以不必重新启动Logstash来获取更改。但是,您确实需要强制Filebeat从头开始读取日志文件。要执行此操作,请转到正在运行Filebeat的终端窗口,然后按Ctrl+C关闭Filebeat。然后删除Filebeat注册表文件。例如,运行:
sudo rm data/registry
由于Filebeat将其获取的每个文件的状态存储在注册表中,因此删除注册表文件会迫使Filebeat从头开始读取所有正在获取的文件。
接下来,使用以下命令重新启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"
如果Filebeat需要等待Logstash重新加载配置文件,那么在它开始处理事件之前可能会有一点延迟。
Logstash应用grok模式后,事件将具有以下JSON表示:
{
"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"offset" => 325,
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"prospector" => {
"type" => "log"
},
"input" => {
"type" => "log"
},
"source" => "/path/to/file/logstash-tutorial.log",
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://semicomplete.com/presentations/logstash-monitorama-2013/\"",
"@timestamp" => 2017-11-09T02:51:12.416Z,
"response" => "200",
"bytes" => "203023",
"clientip" => "83.149.9.216",
"@version" => "1",
"beat" => {
"name" => "My-MacBook-Pro.local",
"hostname" => "My-MacBook-Pro.local",
"version" => "6.0.0"
},
"host" => "My-MacBook-Pro.local",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:13:42 +0000"
}请注意,事件包括原始消息,但日志消息也被分解为特定的字段。
四、使用Geoip Filter Plugin增强您的数据
除了解析日志数据以进行更好的搜索外,过滤器插件还可以从现有数据中获取补充信息。例如,geoap插件查找IP地址,从地址中导出地理位置信息,并将该位置信息添加到日志中。
通过在第一个pipeline.conf文件的filter部分添加以下行,将Logstash实例配置为使用geoip过滤器插件:
geoip {
source => "clientip"
}geoap插件配置要求您指定包含要查找的IP地址的源字段的名称。在本例中,clientip字段包含IP地址。
由于滤波器是按顺序计算的,请确保大地水准面剖面在配置文件的grok剖面之后,并且grok剖面和大地水准面断面都嵌套在滤波器剖面内。
完成后,第一个pipeline.conf的内容应该如下所示:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}保存您的更改。如前所述,要强制Filebeat从头开始读取日志文件,请关闭Filebeat(按Ctrl+C),删除注册表文件,然后使用以下命令重新启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"
请注意,该事件现在包含地理位置信息:
{
"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"geoip" => {
"timezone" => "Europe/Moscow",
"ip" => "83.149.9.216",
"latitude" => 55.7485,
"continent_code" => "EU",
"city_name" => "Moscow",
"country_name" => "Russia",
"country_code2" => "RU",
"country_code3" => "RU",
"region_name" => "Moscow",
"location" => {
"lon" => 37.6184,
"lat" => 55.7485
},
"postal_code" => "101194",
"region_code" => "MOW",
"longitude" => 37.6184
},
...五、将数据索引到Elasticsearch
现在,网络日志被分解为特定的字段,您可以将数据输入Elasticsearch了。
Logstash管道可以将数据索引到Elasticsearch集群中。编辑第一个pipeline.conf文件,并将整个输出部分替换为以下文本:
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}有了这个配置,Logstash使用http协议连接到Elasticsearch。上面的例子假设Logstash和Elasticsearch在同一个实例上运行。您可以通过使用hosts配置指定hosts=>[“es machine:9092”]之类的内容来指定远程Elasticsearch实例。
此时,您的第一个pipeline.conf文件已经正确配置了输入、过滤和输出部分,看起来如下:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}保存您的更改。如前所述,要强制Filebeat从头开始读取日志文件,请关闭Filebeat(按Ctrl+C),删除注册表文件,然后使用以下命令重新启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"
六、测试pipeline
现在Logstash管道被配置为将数据索引到Elasticsearch集群中,您可以查询Elasticsearch。
根据grok过滤器插件创建的字段,尝试对Elasticsearch进行测试查询。将$DATE替换为当前日期,格式为YYYY.MM.DD:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=response=200'
你应该得到多次回击。例如:
{
"took": 50,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 98,
"max_score": 2.793642,
"hits": [
{
"_index": "logstash-2017.11.09",
"_type": "doc",
"_id": "3IzDnl8BW52sR0fx5wdV",
"_score": 2.793642,
"_source": {
"request": "/presentations/logstash-monitorama-2013/images/frontend-response-codes.png",
"agent": """"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"""",
"geoip": {
"timezone": "Europe/Moscow",
"ip": "83.149.9.216",
"latitude": 55.7485,
"continent_code": "EU",
"city_name": "Moscow",
"country_name": "Russia",
"country_code2": "RU",
"country_code3": "RU",
"region_name": "Moscow",
"location": {
"lon": 37.6184,
"lat": 55.7485
},
"postal_code": "101194",
"region_code": "MOW",
"longitude": 37.6184
},
"offset": 2932,
"auth": "-",
"ident": "-",
"verb": "GET",
"prospector": {
"type": "log"
},
"input": {
"type": "log"
},
"source": "/path/to/file/logstash-tutorial.log",
"message": """83.149.9.216 - - [04/Jan/2015:05:13:45 +0000] "GET /presentations/logstash-monitorama-2013/images/frontend-response-codes.png HTTP/1.1" 200 52878 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"""",
"tags": [
"beats_input_codec_plain_applied"
],
"referrer": """"http://semicomplete.com/presentations/logstash-monitorama-2013/"""",
"@timestamp": "2017-11-09T03:11:35.304Z",
"response": "200",
"bytes": "52878",
"clientip": "83.149.9.216",
"@version": "1",
"beat": {
"name": "My-MacBook-Pro.local",
"hostname": "My-MacBook-Pro.local",
"version": "6.0.0"
},
"host": "My-MacBook-Pro.local",
"httpversion": "1.1",
"timestamp": "04/Jan/2015:05:13:45 +0000"
}
},
...尝试另一次搜索从IP地址派生的地理信息。将$DATE替换为当前日期,格式为YYYY.MM.DD:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=geoip.city_name=Buffalo'
一些日志条目来自Buffalo,因此查询会产生以下响应:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 2.6390574,
"hits": [
{
"_index": "logstash-2017.11.09",
"_type": "doc",
"_id": "L4zDnl8BW52sR0fx5whY",
"_score": 2.6390574,
"_source": {
"request": "/blog/geekery/disabling-battery-in-ubuntu-vms.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29",
"agent": """"Tiny Tiny RSS/1.11 (http://tt-rss.org/)"""",
"geoip": {
"timezone": "America/New_York",
"ip": "198.46.149.143",
"latitude": 42.8864,
"continent_code": "NA",
"city_name": "Buffalo",
"country_name": "United States",
"country_code2": "US",
"dma_code": 514,
"country_code3": "US",
"region_name": "New York",
"location": {
"lon": -78.8781,
"lat": 42.8864
},
"postal_code": "14202",
"region_code": "NY",
"longitude": -78.8781
},
"offset": 22795,
"auth": "-",
"ident": "-",
"verb": "GET",
"prospector": {
"type": "log"
},
"input": {
"type": "log"
},
"source": "/path/to/file/logstash-tutorial.log",
"message": """198.46.149.143 - - [04/Jan/2015:05:29:13 +0000] "GET /blog/geekery/disabling-battery-in-ubuntu-vms.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29 HTTP/1.1" 200 9316 "-" "Tiny Tiny RSS/1.11 (http://tt-rss.org/)"""",
"tags": [
"beats_input_codec_plain_applied"
],
"referrer": """"-"""",
"@timestamp": "2017-11-09T03:11:35.321Z",
"response": "200",
"bytes": "9316",
"clientip": "198.46.149.143",
"@version": "1",
"beat": {
"name": "My-MacBook-Pro.local",
"hostname": "My-MacBook-Pro.local",
"version": "6.0.0"
},
"host": "My-MacBook-Pro.local",
"httpversion": "1.1",
"timestamp": "04/Jan/2015:05:29:13 +0000"
}
},
...如果您正在使用Kibana可视化您的数据,您也可以在Kibana中探索Filebeat数据:

您已成功创建了一个管道,该管道使用 Filebeat 将 Apache Web 日志作为输入,并将这些日志解析为 从日志中创建特定的命名字段,并将解析后的数据写入 Elasticsearch 集群。接下来,你 了解如何创建使用多个输入和输出插件的管道。文章来源:https://www.toymoban.com/news/detail-599080.html
大家好,我是Doker品牌的Sinbad,欢迎点赞和评论,您的鼓励是我们持续更新的动力!欢迎加微信进入技术群聊!文章来源地址https://www.toymoban.com/news/detail-599080.html
到了这里,关于logstash 日志解析配置详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!