-
UIE-X在医疗领域的实战
- 1.项目背景
- 2.案例简介
- 3.环境准备
-
数据转换
- 5.模型微调
- 6.模型评估
- 7.Taskflow一键部署
UIE-X在医疗领域的实战
PaddleNLP全新发布UIE-X 🧾,除已有纯文本抽取的全部功能外,新增文档抽取能力。
UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先。
项目链接:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction
本案例为UIE-X在医疗领域的实战,通过少量标注+模型微调即可具备定制场景的端到端文档信息提取能力!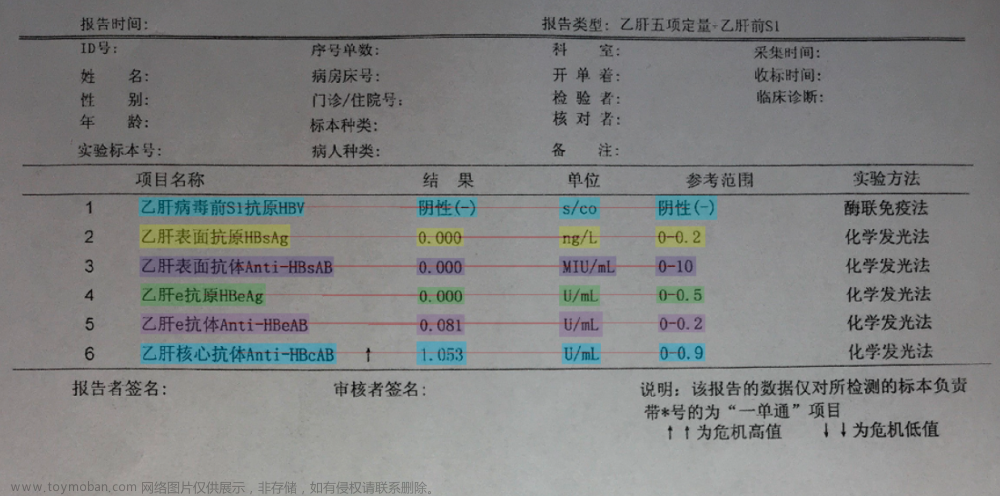
1.项目背景
目前医疗领域有大量的医学检查报告单,病历,发票,CT影像,眼科等等的医疗图片数据。现阶段,针对这些图片都是靠人工分类,结构化录入系统中,做患者的全生命周期的管理。
耗时耗力,人工成本极大。如果能靠人工智能的技术做到图片的自动分类和结构化,将大大的降低成本,提高系统录入的整体效率。
2.案例简介
本案例基于PaddleNLP最新开源的UIE-X,以医学检查单这种医疗领域常见的图片类型为例,展示从数据标注、模型训练到Taskflow一键部署的全流程解决方案
数据集来源:https://tianchi.aliyun.com/dataset/126039
数据集样例展示:



医疗场景常见图片展示:



3.环境准备
!pip install --upgrade --user paddleocr
!pip install --upgrade --user paddlenlp
我们推荐使用数据标注平台Label-Studio进行数据标注,本案例也打通了从标注到训练的通道,即Label-Studio导出数据后可通过label_studio.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。为了达到这个目的,您可以参考信息抽取任务Label-Studio标注指南在Label-Studio平台上标注数据:

# 下载标注数据:
!wget https://paddlenlp.bj.bcebos.com/datasets/medical_checklist.zip
!unzip medical_checklist.zip
数据转换
!python label_studio.py \
--label_studio_file ./medical_checklist/label_studio.json \
--save_dir ./medical_checklist \
--splits 0.8 0.2 0\
--task_type ext \
5.模型微调
!python finetune.py \
--device gpu \
--logging_steps 5 \
--save_steps 25 \
--eval_steps 25 \
--seed 42 \
--model_name_or_path uie-x-base \
--output_dir ./checkpoint/model_best \
--train_path medical_checklist/train.txt \
--dev_path medical_checklist/dev.txt \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--num_train_epochs 5 \
--learning_rate 1e-5 \
--label_names 'start_positions' 'end_positions' \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
[2023-07-21 15:36:09,684] [ WARNING] - evaluation_strategy reset to IntervalStrategy.STEPS for do_eval is True. you can also set evaluation_strategy='epoch'.
[2023-07-21 15:36:09,684] [ INFO] - The default value for the training argument `--report_to` will change in v5 (from all installed integrations to none). In v5, you will need to use `--report_to all` to get the same behavior as now. You should start updating your code and make this info disappear :-).
[2023-07-21 15:36:09,684] [ INFO] - ============================================================
[2023-07-21 15:36:09,685] [ INFO] - Model Configuration Arguments
[2023-07-21 15:36:09,685] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2023-07-21 15:36:09,685] [ INFO] - export_model_dir :./checkpoint/model_best
[2023-07-21 15:36:09,685] [ INFO] - model_name_or_path :uie-x-base
[2023-07-21 15:36:09,685] [ INFO] -
[2023-07-21 15:36:09,685] [ INFO] - ============================================================
[2023-07-21 15:36:09,685] [ INFO] - Data Configuration Arguments
[2023-07-21 15:36:09,685] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2023-07-21 15:36:09,685] [ INFO] - dev_path :medical_checklist/dev.txt
[2023-07-21 15:36:09,685] [ INFO] - max_seq_len :512
[2023-07-21 15:36:09,685] [ INFO] - train_path :medical_checklist/train.txt
[2023-07-21 15:36:09,685] [ INFO] -
[2023-07-21 15:36:09,685] [ WARNING] - Process rank: -1, device: gpu, world_size: 1, distributed training: False, 16-bits training: False
[2023-07-21 15:36:09,686] [ INFO] - Model config ErnieLayoutConfig {
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"coordinate_size": 128,
"enable_recompute": false,
"eos_token_id": 2,
"fuse": false,
"gradient_checkpointing": false,
"has_relative_attention_bias": true,
"has_spatial_attention_bias": true,
"has_visual_segment_embedding": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"image_feature_pool_shape": [
7,
7,
256
],
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_2d_position_embeddings": 1024,
"max_position_embeddings": 514,
"max_rel_2d_pos": 256,
"max_rel_pos": 128,
"model_type": "ernie_layout",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"output_past": true,
"pad_token_id": 1,
"paddlenlp_version": null,
"pool_act": "tanh",
"rel_2d_pos_bins": 64,
"rel_pos_bins": 32,
"shape_size": 128,
"task_id": 0,
"task_type_vocab_size": 3,
"type_vocab_size": 100,
"use_task_id": true,
"vocab_size": 250002
}
[2023-07-21 15:36:09,687] [ INFO] - Configuration saved in /home/aistudio/.paddlenlp/models/uie-x-base/config.json
[2023-07-21 15:36:09,687] [ INFO] - Downloading uie_x_base.pdparams from https://bj.bcebos.com/paddlenlp/models/transformers/uie_x/uie_x_base.pdparams
100%|██████████████████████████████████████| 1.05G/1.05G [00:15<00:00, 73.4MB/s]
W0721 15:36:28.591925 856 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0721 15:36:28.595674 856 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-07-21 15:36:30,069] [ INFO] - All model checkpoint weights were used when initializing UIEX.
[2023-07-21 15:36:30,069] [ INFO] - All the weights of UIEX were initialized from the model checkpoint at uie-x-base.
If your task is similar to the task the model of the checkpoint was trained on, you can already use UIEX for predictions without further training.
[2023-07-21 15:36:30,070] [ INFO] - We are using <class 'paddlenlp.transformers.ernie_layout.tokenizer.ErnieLayoutTokenizer'> to load 'uie-x-base'.
[2023-07-21 15:36:30,071] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_layout/vocab.txt and saved to /home/aistudio/.paddlenlp/models/uie-x-base
[2023-07-21 15:36:30,132] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_layout/vocab.txt
100%|██████████████████████████████████████| 2.70M/2.70M [00:00<00:00, 48.4MB/s]
[2023-07-21 15:36:30,263] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_layout/sentencepiece.bpe.model and saved to /home/aistudio/.paddlenlp/models/uie-x-base
[2023-07-21 15:36:30,325] [ INFO] - Downloading sentencepiece.bpe.model from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_layout/sentencepiece.bpe.model
100%|██████████████████████████████████████| 4.83M/4.83M [00:00<00:00, 63.2MB/s]
[2023-07-21 15:36:31,214] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/uie-x-base/tokenizer_config.json
[2023-07-21 15:36:31,214] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/uie-x-base/special_tokens_map.json
[2023-07-21 15:36:33,843] [ INFO] - ============================================================
[2023-07-21 15:36:33,844] [ INFO] - Training Configuration Arguments
[2023-07-21 15:36:33,844] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2023-07-21 15:36:33,844] [ INFO] - _no_sync_in_gradient_accumulation:True
[2023-07-21 15:36:33,844] [ INFO] - activation_quantize_type :None
[2023-07-21 15:36:33,844] [ INFO] - adam_beta1 :0.9
[2023-07-21 15:36:33,844] [ INFO] - adam_beta2 :0.999
[2023-07-21 15:36:33,844] [ INFO] - adam_epsilon :1e-08
[2023-07-21 15:36:33,844] [ INFO] - algo_list :None
[2023-07-21 15:36:33,844] [ INFO] - batch_num_list :None
[2023-07-21 15:36:33,844] [ INFO] - batch_size_list :None
[2023-07-21 15:36:33,844] [ INFO] - bf16 :False
[2023-07-21 15:36:33,844] [ INFO] - bf16_full_eval :False
[2023-07-21 15:36:33,844] [ INFO] - bias_correction :False
[2023-07-21 15:36:33,844] [ INFO] - current_device :gpu:0
[2023-07-21 15:36:33,844] [ INFO] - dataloader_drop_last :False
[2023-07-21 15:36:33,844] [ INFO] - dataloader_num_workers :0
[2023-07-21 15:36:33,845] [ INFO] - device :gpu
[2023-07-21 15:36:33,845] [ INFO] - disable_tqdm :True
[2023-07-21 15:36:33,845] [ INFO] - do_compress :False
[2023-07-21 15:36:33,845] [ INFO] - do_eval :True
[2023-07-21 15:36:33,845] [ INFO] - do_export :True
[2023-07-21 15:36:33,845] [ INFO] - do_predict :False
[2023-07-21 15:36:33,845] [ INFO] - do_train :True
[2023-07-21 15:36:33,845] [ INFO] - eval_batch_size :16
[2023-07-21 15:36:33,845] [ INFO] - eval_steps :25
[2023-07-21 15:36:33,845] [ INFO] - evaluation_strategy :IntervalStrategy.STEPS
[2023-07-21 15:36:33,845] [ INFO] - flatten_param_grads :False
[2023-07-21 15:36:33,845] [ INFO] - fp16 :False
[2023-07-21 15:36:33,845] [ INFO] - fp16_full_eval :False
[2023-07-21 15:36:33,845] [ INFO] - fp16_opt_level :O1
[2023-07-21 15:36:33,845] [ INFO] - gradient_accumulation_steps :1
[2023-07-21 15:36:33,845] [ INFO] - greater_is_better :True
[2023-07-21 15:36:33,845] [ INFO] - ignore_data_skip :False
[2023-07-21 15:36:33,845] [ INFO] - input_dtype :int64
[2023-07-21 15:36:33,845] [ INFO] - input_infer_model_path :None
[2023-07-21 15:36:33,845] [ INFO] - label_names :['start_positions', 'end_positions']
[2023-07-21 15:36:33,845] [ INFO] - lazy_data_processing :True
[2023-07-21 15:36:33,845] [ INFO] - learning_rate :1e-05
[2023-07-21 15:36:33,845] [ INFO] - load_best_model_at_end :True
[2023-07-21 15:36:33,845] [ INFO] - local_process_index :0
[2023-07-21 15:36:33,845] [ INFO] - local_rank :-1
[2023-07-21 15:36:33,845] [ INFO] - log_level :-1
[2023-07-21 15:36:33,845] [ INFO] - log_level_replica :-1
[2023-07-21 15:36:33,846] [ INFO] - log_on_each_node :True
[2023-07-21 15:36:33,846] [ INFO] - logging_dir :./checkpoint/model_best/runs/Jul21_15-36-09_jupyter-2631487-6518069
[2023-07-21 15:36:33,846] [ INFO] - logging_first_step :False
[2023-07-21 15:36:33,846] [ INFO] - logging_steps :5
[2023-07-21 15:36:33,846] [ INFO] - logging_strategy :IntervalStrategy.STEPS
[2023-07-21 15:36:33,846] [ INFO] - lr_scheduler_type :SchedulerType.LINEAR
[2023-07-21 15:36:33,846] [ INFO] - max_grad_norm :1.0
[2023-07-21 15:36:33,846] [ INFO] - max_steps :-1
[2023-07-21 15:36:33,846] [ INFO] - metric_for_best_model :eval_f1
[2023-07-21 15:36:33,846] [ INFO] - minimum_eval_times :None
[2023-07-21 15:36:33,846] [ INFO] - moving_rate :0.9
[2023-07-21 15:36:33,846] [ INFO] - no_cuda :False
[2023-07-21 15:36:33,846] [ INFO] - num_train_epochs :5.0
[2023-07-21 15:36:33,846] [ INFO] - onnx_format :True
[2023-07-21 15:36:33,846] [ INFO] - optim :OptimizerNames.ADAMW
[2023-07-21 15:36:33,846] [ INFO] - output_dir :./checkpoint/model_best
[2023-07-21 15:36:33,846] [ INFO] - overwrite_output_dir :True
[2023-07-21 15:36:33,846] [ INFO] - past_index :-1
[2023-07-21 15:36:33,846] [ INFO] - per_device_eval_batch_size :16
[2023-07-21 15:36:33,846] [ INFO] - per_device_train_batch_size :16
[2023-07-21 15:36:33,846] [ INFO] - prediction_loss_only :False
[2023-07-21 15:36:33,846] [ INFO] - process_index :0
[2023-07-21 15:36:33,846] [ INFO] - prune_embeddings :False
[2023-07-21 15:36:33,846] [ INFO] - recompute :False
[2023-07-21 15:36:33,846] [ INFO] - remove_unused_columns :True
[2023-07-21 15:36:33,846] [ INFO] - report_to :['visualdl']
[2023-07-21 15:36:33,846] [ INFO] - resume_from_checkpoint :None
[2023-07-21 15:36:33,846] [ INFO] - round_type :round
[2023-07-21 15:36:33,847] [ INFO] - run_name :./checkpoint/model_best
[2023-07-21 15:36:33,847] [ INFO] - save_on_each_node :False
[2023-07-21 15:36:33,847] [ INFO] - save_steps :25
[2023-07-21 15:36:33,847] [ INFO] - save_strategy :IntervalStrategy.STEPS
[2023-07-21 15:36:33,847] [ INFO] - save_total_limit :1
[2023-07-21 15:36:33,847] [ INFO] - scale_loss :32768
[2023-07-21 15:36:33,847] [ INFO] - seed :42
[2023-07-21 15:36:33,847] [ INFO] - sharding :[]
[2023-07-21 15:36:33,847] [ INFO] - sharding_degree :-1
[2023-07-21 15:36:33,847] [ INFO] - should_log :True
[2023-07-21 15:36:33,847] [ INFO] - should_save :True
[2023-07-21 15:36:33,847] [ INFO] - skip_memory_metrics :True
[2023-07-21 15:36:33,847] [ INFO] - strategy :dynabert+ptq
[2023-07-21 15:36:33,847] [ INFO] - train_batch_size :16
[2023-07-21 15:36:33,847] [ INFO] - use_pact :True
[2023-07-21 15:36:33,847] [ INFO] - warmup_ratio :0.1
[2023-07-21 15:36:33,847] [ INFO] - warmup_steps :0
[2023-07-21 15:36:33,847] [ INFO] - weight_decay :0.0
[2023-07-21 15:36:33,847] [ INFO] - weight_quantize_type :channel_wise_abs_max
[2023-07-21 15:36:33,847] [ INFO] - width_mult_list :None
[2023-07-21 15:36:33,847] [ INFO] - world_size :1
[2023-07-21 15:36:33,847] [ INFO] -
[2023-07-21 15:36:33,849] [ INFO] - ***** Running training *****
[2023-07-21 15:36:33,849] [ INFO] - Num examples = 686
[2023-07-21 15:36:33,849] [ INFO] - Num Epochs = 5
[2023-07-21 15:36:33,849] [ INFO] - Instantaneous batch size per device = 16
[2023-07-21 15:36:33,849] [ INFO] - Total train batch size (w. parallel, distributed & accumulation) = 16
[2023-07-21 15:36:33,849] [ INFO] - Gradient Accumulation steps = 1
[2023-07-21 15:36:33,849] [ INFO] - Total optimization steps = 215.0
[2023-07-21 15:36:33,849] [ INFO] - Total num train samples = 3430.0
[2023-07-21 15:36:33,856] [ INFO] - Number of trainable parameters = 281693122
[2023-07-21 15:36:55,804] [ INFO] - loss: 0.00139983, learning_rate: 1e-05, global_step: 5, interval_runtime: 21.9466, interval_samples_per_second: 3.645, interval_steps_per_second: 0.228, epoch: 0.1163
[2023-07-21 15:37:17,246] [ INFO] - loss: 0.00095238, learning_rate: 1e-05, global_step: 10, interval_runtime: 21.4431, interval_samples_per_second: 3.731, interval_steps_per_second: 0.233, epoch: 0.2326
[2023-07-21 15:37:38,397] [ INFO] - loss: 0.00227169, learning_rate: 1e-05, global_step: 15, interval_runtime: 21.1288, interval_samples_per_second: 3.786, interval_steps_per_second: 0.237, epoch: 0.3488
[2023-07-21 15:37:59,719] [ INFO] - loss: 0.00058537, learning_rate: 1e-05, global_step: 20, interval_runtime: 21.3431, interval_samples_per_second: 3.748, interval_steps_per_second: 0.234, epoch: 0.4651
[2023-07-21 15:38:20,879] [ INFO] - loss: 0.00099298, learning_rate: 1e-05, global_step: 25, interval_runtime: 21.1605, interval_samples_per_second: 3.781, interval_steps_per_second: 0.236, epoch: 0.5814
[2023-07-21 15:38:20,879] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:38:20,880] [ INFO] - Num examples = 35
[2023-07-21 15:38:20,880] [ INFO] - Total prediction steps = 3
[2023-07-21 15:38:20,880] [ INFO] - Pre device batch size = 16
[2023-07-21 15:38:20,880] [ INFO] - Total Batch size = 16
[2023-07-21 15:38:31,387] [ INFO] - eval_loss: 0.0014212249079719186, eval_precision: 0.9344262295081968, eval_recall: 0.9047619047619048, eval_f1: 0.9193548387096775, eval_runtime: 10.5013, eval_samples_per_second: 3.333, eval_steps_per_second: 0.286, epoch: 0.5814
[2023-07-21 15:38:31,387] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-25
[2023-07-21 15:38:31,390] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-25/config.json
[2023-07-21 15:38:33,536] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-25/tokenizer_config.json
[2023-07-21 15:38:33,537] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-25/special_tokens_map.json
[2023-07-21 15:38:46,593] [ INFO] - loss: 0.00054665, learning_rate: 1e-05, global_step: 30, interval_runtime: 25.7138, interval_samples_per_second: 3.111, interval_steps_per_second: 0.194, epoch: 0.6977
[2023-07-21 15:39:07,860] [ INFO] - loss: 0.00042223, learning_rate: 1e-05, global_step: 35, interval_runtime: 21.2605, interval_samples_per_second: 3.763, interval_steps_per_second: 0.235, epoch: 0.814
[2023-07-21 15:39:29,450] [ INFO] - loss: 0.00070746, learning_rate: 1e-05, global_step: 40, interval_runtime: 21.5964, interval_samples_per_second: 3.704, interval_steps_per_second: 0.232, epoch: 0.9302
[2023-07-21 15:39:50,745] [ INFO] - loss: 0.00027768, learning_rate: 1e-05, global_step: 45, interval_runtime: 21.2946, interval_samples_per_second: 3.757, interval_steps_per_second: 0.235, epoch: 1.0465
[2023-07-21 15:40:12,219] [ INFO] - loss: 0.00037302, learning_rate: 1e-05, global_step: 50, interval_runtime: 21.4753, interval_samples_per_second: 3.725, interval_steps_per_second: 0.233, epoch: 1.1628
[2023-07-21 15:40:12,220] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:40:12,220] [ INFO] - Num examples = 35
[2023-07-21 15:40:12,220] [ INFO] - Total prediction steps = 3
[2023-07-21 15:40:12,220] [ INFO] - Pre device batch size = 16
[2023-07-21 15:40:12,221] [ INFO] - Total Batch size = 16
[2023-07-21 15:40:22,304] [ INFO] - eval_loss: 0.0014475114876404405, eval_precision: 0.9482758620689655, eval_recall: 0.873015873015873, eval_f1: 0.9090909090909091, eval_runtime: 10.0828, eval_samples_per_second: 3.471, eval_steps_per_second: 0.298, epoch: 1.1628
[2023-07-21 15:40:22,305] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-50
[2023-07-21 15:40:22,308] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-50/config.json
[2023-07-21 15:40:24,464] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-50/tokenizer_config.json
[2023-07-21 15:40:24,465] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-50/special_tokens_map.json
[2023-07-21 15:40:37,740] [ INFO] - loss: 0.00019248, learning_rate: 1e-05, global_step: 55, interval_runtime: 25.5206, interval_samples_per_second: 3.135, interval_steps_per_second: 0.196, epoch: 1.2791
[2023-07-21 15:40:58,905] [ INFO] - loss: 0.00021258, learning_rate: 1e-05, global_step: 60, interval_runtime: 21.1645, interval_samples_per_second: 3.78, interval_steps_per_second: 0.236, epoch: 1.3953
[2023-07-21 15:41:20,213] [ INFO] - loss: 0.00024681, learning_rate: 1e-05, global_step: 65, interval_runtime: 21.3084, interval_samples_per_second: 3.754, interval_steps_per_second: 0.235, epoch: 1.5116
[2023-07-21 15:41:41,237] [ INFO] - loss: 0.000169, learning_rate: 1e-05, global_step: 70, interval_runtime: 21.024, interval_samples_per_second: 3.805, interval_steps_per_second: 0.238, epoch: 1.6279
[2023-07-21 15:42:02,163] [ INFO] - loss: 0.00036645, learning_rate: 1e-05, global_step: 75, interval_runtime: 20.9256, interval_samples_per_second: 3.823, interval_steps_per_second: 0.239, epoch: 1.7442
[2023-07-21 15:42:02,163] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:42:02,163] [ INFO] - Num examples = 35
[2023-07-21 15:42:02,164] [ INFO] - Total prediction steps = 3
[2023-07-21 15:42:02,164] [ INFO] - Pre device batch size = 16
[2023-07-21 15:42:02,164] [ INFO] - Total Batch size = 16
[2023-07-21 15:42:12,158] [ INFO] - eval_loss: 0.001322056632488966, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 9.9708, eval_samples_per_second: 3.51, eval_steps_per_second: 0.301, epoch: 1.7442
[2023-07-21 15:42:12,159] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-75
[2023-07-21 15:42:12,161] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-75/config.json
[2023-07-21 15:42:14,264] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-75/tokenizer_config.json
[2023-07-21 15:42:14,264] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-75/special_tokens_map.json
[2023-07-21 15:42:18,485] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-25] due to args.save_total_limit
[2023-07-21 15:42:27,793] [ INFO] - loss: 0.00060927, learning_rate: 1e-05, global_step: 80, interval_runtime: 25.6304, interval_samples_per_second: 3.121, interval_steps_per_second: 0.195, epoch: 1.8605
[2023-07-21 15:42:48,729] [ INFO] - loss: 0.00068383, learning_rate: 1e-05, global_step: 85, interval_runtime: 20.9361, interval_samples_per_second: 3.821, interval_steps_per_second: 0.239, epoch: 1.9767
[2023-07-21 15:43:09,835] [ INFO] - loss: 0.00042777, learning_rate: 1e-05, global_step: 90, interval_runtime: 21.1056, interval_samples_per_second: 3.79, interval_steps_per_second: 0.237, epoch: 2.093
[2023-07-21 15:43:30,942] [ INFO] - loss: 0.00013877, learning_rate: 1e-05, global_step: 95, interval_runtime: 21.1075, interval_samples_per_second: 3.79, interval_steps_per_second: 0.237, epoch: 2.2093
[2023-07-21 15:43:52,187] [ INFO] - loss: 0.00042886, learning_rate: 1e-05, global_step: 100, interval_runtime: 21.2446, interval_samples_per_second: 3.766, interval_steps_per_second: 0.235, epoch: 2.3256
[2023-07-21 15:43:52,188] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:43:52,188] [ INFO] - Num examples = 35
[2023-07-21 15:43:52,188] [ INFO] - Total prediction steps = 3
[2023-07-21 15:43:52,188] [ INFO] - Pre device batch size = 16
[2023-07-21 15:43:52,188] [ INFO] - Total Batch size = 16
[2023-07-21 15:44:02,369] [ INFO] - eval_loss: 0.001290834159590304, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 10.1799, eval_samples_per_second: 3.438, eval_steps_per_second: 0.295, epoch: 2.3256
[2023-07-21 15:44:02,369] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-100
[2023-07-21 15:44:02,371] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-100/config.json
[2023-07-21 15:44:04,511] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-100/tokenizer_config.json
[2023-07-21 15:44:04,511] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-100/special_tokens_map.json
[2023-07-21 15:44:08,763] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-50] due to args.save_total_limit
[2023-07-21 15:44:17,868] [ INFO] - loss: 0.00011366, learning_rate: 1e-05, global_step: 105, interval_runtime: 25.6806, interval_samples_per_second: 3.115, interval_steps_per_second: 0.195, epoch: 2.4419
[2023-07-21 15:44:39,049] [ INFO] - loss: 4.777e-05, learning_rate: 1e-05, global_step: 110, interval_runtime: 21.1812, interval_samples_per_second: 3.777, interval_steps_per_second: 0.236, epoch: 2.5581
[2023-07-21 15:45:00,245] [ INFO] - loss: 0.00013845, learning_rate: 1e-05, global_step: 115, interval_runtime: 21.1969, interval_samples_per_second: 3.774, interval_steps_per_second: 0.236, epoch: 2.6744
[2023-07-21 15:45:21,118] [ INFO] - loss: 0.00040561, learning_rate: 1e-05, global_step: 120, interval_runtime: 20.8727, interval_samples_per_second: 3.833, interval_steps_per_second: 0.24, epoch: 2.7907
[2023-07-21 15:45:41,985] [ INFO] - loss: 0.00054928, learning_rate: 1e-05, global_step: 125, interval_runtime: 20.8671, interval_samples_per_second: 3.834, interval_steps_per_second: 0.24, epoch: 2.907
[2023-07-21 15:45:41,986] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:45:41,986] [ INFO] - Num examples = 35
[2023-07-21 15:45:41,986] [ INFO] - Total prediction steps = 3
[2023-07-21 15:45:41,986] [ INFO] - Pre device batch size = 16
[2023-07-21 15:45:41,986] [ INFO] - Total Batch size = 16
[2023-07-21 15:45:52,179] [ INFO] - eval_loss: 0.0013684021541848779, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 10.1923, eval_samples_per_second: 3.434, eval_steps_per_second: 0.294, epoch: 2.907
[2023-07-21 15:45:52,180] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-125
[2023-07-21 15:45:52,182] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-125/config.json
[2023-07-21 15:45:54,324] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-125/tokenizer_config.json
[2023-07-21 15:45:54,324] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-125/special_tokens_map.json
[2023-07-21 15:45:58,570] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-100] due to args.save_total_limit
[2023-07-21 15:46:07,445] [ INFO] - loss: 5.219e-05, learning_rate: 1e-05, global_step: 130, interval_runtime: 25.4597, interval_samples_per_second: 3.142, interval_steps_per_second: 0.196, epoch: 3.0233
[2023-07-21 15:46:28,712] [ INFO] - loss: 0.00026077, learning_rate: 1e-05, global_step: 135, interval_runtime: 21.2671, interval_samples_per_second: 3.762, interval_steps_per_second: 0.235, epoch: 3.1395
[2023-07-21 15:46:49,731] [ INFO] - loss: 6.99e-05, learning_rate: 1e-05, global_step: 140, interval_runtime: 21.0185, interval_samples_per_second: 3.806, interval_steps_per_second: 0.238, epoch: 3.2558
[2023-07-21 15:47:10,751] [ INFO] - loss: 0.00023049, learning_rate: 1e-05, global_step: 145, interval_runtime: 21.0205, interval_samples_per_second: 3.806, interval_steps_per_second: 0.238, epoch: 3.3721
[2023-07-21 15:47:31,889] [ INFO] - loss: 0.00015275, learning_rate: 1e-05, global_step: 150, interval_runtime: 21.1372, interval_samples_per_second: 3.785, interval_steps_per_second: 0.237, epoch: 3.4884
[2023-07-21 15:47:31,889] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:47:31,889] [ INFO] - Num examples = 35
[2023-07-21 15:47:31,889] [ INFO] - Total prediction steps = 3
[2023-07-21 15:47:31,890] [ INFO] - Pre device batch size = 16
[2023-07-21 15:47:31,890] [ INFO] - Total Batch size = 16
[2023-07-21 15:47:42,271] [ INFO] - eval_loss: 0.0013476903550326824, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 10.3813, eval_samples_per_second: 3.371, eval_steps_per_second: 0.289, epoch: 3.4884
[2023-07-21 15:47:42,272] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-150
[2023-07-21 15:47:42,274] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-150/config.json
[2023-07-21 15:47:44,424] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-150/tokenizer_config.json
[2023-07-21 15:47:44,424] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-150/special_tokens_map.json
[2023-07-21 15:47:48,728] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-125] due to args.save_total_limit
[2023-07-21 15:47:57,472] [ INFO] - loss: 0.00024907, learning_rate: 1e-05, global_step: 155, interval_runtime: 25.5832, interval_samples_per_second: 3.127, interval_steps_per_second: 0.195, epoch: 3.6047
[2023-07-21 15:48:18,254] [ INFO] - loss: 0.00027028, learning_rate: 1e-05, global_step: 160, interval_runtime: 20.7824, interval_samples_per_second: 3.849, interval_steps_per_second: 0.241, epoch: 3.7209
[2023-07-21 15:48:39,309] [ INFO] - loss: 0.0001771, learning_rate: 1e-05, global_step: 165, interval_runtime: 21.0551, interval_samples_per_second: 3.8, interval_steps_per_second: 0.237, epoch: 3.8372
[2023-07-21 15:49:00,354] [ INFO] - loss: 0.00024041, learning_rate: 1e-05, global_step: 170, interval_runtime: 21.0449, interval_samples_per_second: 3.801, interval_steps_per_second: 0.238, epoch: 3.9535
[2023-07-21 15:49:21,382] [ INFO] - loss: 4.51e-05, learning_rate: 1e-05, global_step: 175, interval_runtime: 21.0273, interval_samples_per_second: 3.805, interval_steps_per_second: 0.238, epoch: 4.0698
[2023-07-21 15:49:21,382] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:49:21,382] [ INFO] - Num examples = 35
[2023-07-21 15:49:21,382] [ INFO] - Total prediction steps = 3
[2023-07-21 15:49:21,382] [ INFO] - Pre device batch size = 16
[2023-07-21 15:49:21,382] [ INFO] - Total Batch size = 16
[2023-07-21 15:49:31,953] [ INFO] - eval_loss: 0.0013263615546748042, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 10.57, eval_samples_per_second: 3.311, eval_steps_per_second: 0.284, epoch: 4.0698
[2023-07-21 15:49:31,954] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-175
[2023-07-21 15:49:31,956] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-175/config.json
[2023-07-21 15:49:34,699] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-175/tokenizer_config.json
[2023-07-21 15:49:34,700] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-175/special_tokens_map.json
[2023-07-21 15:49:40,286] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-150] due to args.save_total_limit
[2023-07-21 15:49:48,671] [ INFO] - loss: 0.0003263, learning_rate: 1e-05, global_step: 180, interval_runtime: 27.2898, interval_samples_per_second: 2.931, interval_steps_per_second: 0.183, epoch: 4.186
[2023-07-21 15:50:09,486] [ INFO] - loss: 0.00014406, learning_rate: 1e-05, global_step: 185, interval_runtime: 20.8144, interval_samples_per_second: 3.843, interval_steps_per_second: 0.24, epoch: 4.3023
[2023-07-21 15:50:31,097] [ INFO] - loss: 0.00010923, learning_rate: 1e-05, global_step: 190, interval_runtime: 21.6107, interval_samples_per_second: 3.702, interval_steps_per_second: 0.231, epoch: 4.4186
[2023-07-21 15:50:52,282] [ INFO] - loss: 8.216e-05, learning_rate: 1e-05, global_step: 195, interval_runtime: 21.1856, interval_samples_per_second: 3.776, interval_steps_per_second: 0.236, epoch: 4.5349
[2023-07-21 15:51:14,299] [ INFO] - loss: 9.251e-05, learning_rate: 1e-05, global_step: 200, interval_runtime: 22.0164, interval_samples_per_second: 3.634, interval_steps_per_second: 0.227, epoch: 4.6512
[2023-07-21 15:51:14,299] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:51:14,299] [ INFO] - Num examples = 35
[2023-07-21 15:51:14,299] [ INFO] - Total prediction steps = 3
[2023-07-21 15:51:14,299] [ INFO] - Pre device batch size = 16
[2023-07-21 15:51:14,300] [ INFO] - Total Batch size = 16
[2023-07-21 15:51:24,773] [ INFO] - eval_loss: 0.0014609990175813437, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 10.4732, eval_samples_per_second: 3.342, eval_steps_per_second: 0.286, epoch: 4.6512
[2023-07-21 15:51:24,774] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-200
[2023-07-21 15:51:24,776] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-200/config.json
[2023-07-21 15:51:27,228] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-200/tokenizer_config.json
[2023-07-21 15:51:27,228] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-200/special_tokens_map.json
[2023-07-21 15:51:32,347] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-175] due to args.save_total_limit
[2023-07-21 15:51:41,379] [ INFO] - loss: 0.00016781, learning_rate: 1e-05, global_step: 205, interval_runtime: 27.0808, interval_samples_per_second: 2.954, interval_steps_per_second: 0.185, epoch: 4.7674
[2023-07-21 15:52:03,510] [ INFO] - loss: 0.00013611, learning_rate: 1e-05, global_step: 210, interval_runtime: 22.1302, interval_samples_per_second: 3.615, interval_steps_per_second: 0.226, epoch: 4.8837
[2023-07-21 15:52:23,996] [ INFO] - loss: 0.0001641, learning_rate: 1e-05, global_step: 215, interval_runtime: 20.4867, interval_samples_per_second: 3.905, interval_steps_per_second: 0.244, epoch: 5.0
[2023-07-21 15:52:23,997] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:52:23,997] [ INFO] - Num examples = 35
[2023-07-21 15:52:23,997] [ INFO] - Total prediction steps = 3
[2023-07-21 15:52:23,997] [ INFO] - Pre device batch size = 16
[2023-07-21 15:52:23,997] [ INFO] - Total Batch size = 16
[2023-07-21 15:52:33,805] [ INFO] - eval_loss: 0.0011874400079250336, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 9.8078, eval_samples_per_second: 3.569, eval_steps_per_second: 0.306, epoch: 5.0
[2023-07-21 15:52:33,806] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-215
[2023-07-21 15:52:33,808] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-215/config.json
[2023-07-21 15:52:36,141] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-215/tokenizer_config.json
[2023-07-21 15:52:36,141] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-215/special_tokens_map.json
[2023-07-21 15:52:41,717] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-200] due to args.save_total_limit
[2023-07-21 15:52:42,252] [ INFO] -
Training completed.
[2023-07-21 15:52:42,252] [ INFO] - Loading best model from ./checkpoint/model_best/checkpoint-75 (score: 0.9354838709677418).
[2023-07-21 15:52:43,847] [ INFO] - train_runtime: 969.9908, train_samples_per_second: 3.536, train_steps_per_second: 0.222, train_loss: 0.0003774468271267535, epoch: 5.0
[2023-07-21 15:52:43,915] [ INFO] - Saving model checkpoint to ./checkpoint/model_best
[2023-07-21 15:52:43,917] [ INFO] - Configuration saved in ./checkpoint/model_best/config.json
[2023-07-21 15:52:46,306] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/tokenizer_config.json
[2023-07-21 15:52:46,306] [ INFO] - Special tokens file saved in ./checkpoint/model_best/special_tokens_map.json
[2023-07-21 15:52:46,314] [ INFO] - ***** train metrics *****
[2023-07-21 15:52:46,315] [ INFO] - epoch = 5.0
[2023-07-21 15:52:46,315] [ INFO] - train_loss = 0.0004
[2023-07-21 15:52:46,315] [ INFO] - train_runtime = 0:16:09.99
[2023-07-21 15:52:46,315] [ INFO] - train_samples_per_second = 3.536
[2023-07-21 15:52:46,315] [ INFO] - train_steps_per_second = 0.222
[2023-07-21 15:52:46,318] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:52:46,318] [ INFO] - Num examples = 35
[2023-07-21 15:52:46,318] [ INFO] - Total prediction steps = 3
[2023-07-21 15:52:46,318] [ INFO] - Pre device batch size = 16
[2023-07-21 15:52:46,318] [ INFO] - Total Batch size = 16
[2023-07-21 15:52:55,755] [ INFO] - eval_loss: 0.001322056632488966, eval_precision: 0.9508196721311475, eval_recall: 0.9206349206349206, eval_f1: 0.9354838709677418, eval_runtime: 9.4374, eval_samples_per_second: 3.709, eval_steps_per_second: 0.318, epoch: 5.0
[2023-07-21 15:52:55,756] [ INFO] - ***** eval metrics *****
[2023-07-21 15:52:55,756] [ INFO] - epoch = 5.0
[2023-07-21 15:52:55,756] [ INFO] - eval_f1 = 0.9355
[2023-07-21 15:52:55,756] [ INFO] - eval_loss = 0.0013
[2023-07-21 15:52:55,756] [ INFO] - eval_precision = 0.9508
[2023-07-21 15:52:55,756] [ INFO] - eval_recall = 0.9206
[2023-07-21 15:52:55,756] [ INFO] - eval_runtime = 0:00:09.43
[2023-07-21 15:52:55,756] [ INFO] - eval_samples_per_second = 3.709
[2023-07-21 15:52:55,756] [ INFO] - eval_steps_per_second = 0.318
[2023-07-21 15:52:55,759] [ INFO] - Exporting inference model to ./checkpoint/model_best/model
[2023-07-21 15:53:55,567] [ INFO] - Inference model exported.
6.模型评估
!python evaluate.py \
--device "gpu" \
--model_path ./checkpoint/model_best \
--test_path ./medical_checklist/dev.txt \
--output_dir ./checkpoint/model_best \
--label_names 'start_positions' 'end_positions'\
--max_seq_len 512 \
--per_device_eval_batch_size 16
[2023-07-21 15:55:25,012] [ INFO] - The default value for the training argument `--report_to` will change in v5 (from all installed integrations to none). In v5, you will need to use `--report_to all` to get the same behavior as now. You should start updating your code and make this info disappear :-).
[2023-07-21 15:55:25,012] [ INFO] - ============================================================
[2023-07-21 15:55:25,013] [ INFO] - Model Configuration Arguments
[2023-07-21 15:55:25,013] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2023-07-21 15:55:25,013] [ INFO] - model_path :./checkpoint/model_best
[2023-07-21 15:55:25,013] [ INFO] -
[2023-07-21 15:55:25,013] [ INFO] - ============================================================
[2023-07-21 15:55:25,013] [ INFO] - Data Configuration Arguments
[2023-07-21 15:55:25,013] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2023-07-21 15:55:25,013] [ INFO] - debug :False
[2023-07-21 15:55:25,013] [ INFO] - max_seq_len :512
[2023-07-21 15:55:25,013] [ INFO] - schema_lang :ch
[2023-07-21 15:55:25,013] [ INFO] - test_path :./medical_checklist/dev.txt
[2023-07-21 15:55:25,013] [ INFO] -
[2023-07-21 15:55:25,014] [ INFO] - We are using <class 'paddlenlp.transformers.ernie_layout.tokenizer.ErnieLayoutTokenizer'> to load './checkpoint/model_best'.
[2023-07-21 15:55:25,693] [ INFO] - loading configuration file ./checkpoint/model_best/config.json
[2023-07-21 15:55:25,694] [ INFO] - Model config ErnieLayoutConfig {
"architectures": [
"UIEX"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"coordinate_size": 128,
"dtype": "float32",
"enable_recompute": false,
"eos_token_id": 2,
"fuse": false,
"gradient_checkpointing": false,
"has_relative_attention_bias": true,
"has_spatial_attention_bias": true,
"has_visual_segment_embedding": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"image_feature_pool_shape": [
7,
7,
256
],
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_2d_position_embeddings": 1024,
"max_position_embeddings": 514,
"max_rel_2d_pos": 256,
"max_rel_pos": 128,
"model_type": "ernie_layout",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"output_past": true,
"pad_token_id": 1,
"paddlenlp_version": null,
"pool_act": "tanh",
"rel_2d_pos_bins": 64,
"rel_pos_bins": 32,
"shape_size": 128,
"task_id": 0,
"task_type_vocab_size": 3,
"type_vocab_size": 100,
"use_task_id": true,
"vocab_size": 250002
}
W0721 15:55:29.126700 3399 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0721 15:55:29.130168 3399 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-07-21 15:55:31,058] [ INFO] - All model checkpoint weights were used when initializing UIEX.
[2023-07-21 15:55:31,058] [ INFO] - All the weights of UIEX were initialized from the model checkpoint at ./checkpoint/model_best.
If your task is similar to the task the model of the checkpoint was trained on, you can already use UIEX for predictions without further training.
[2023-07-21 15:55:31,259] [ INFO] - ============================================================
[2023-07-21 15:55:31,259] [ INFO] - Training Configuration Arguments
[2023-07-21 15:55:31,259] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2023-07-21 15:55:31,260] [ INFO] - _no_sync_in_gradient_accumulation:True
[2023-07-21 15:55:31,260] [ INFO] - adam_beta1 :0.9
[2023-07-21 15:55:31,260] [ INFO] - adam_beta2 :0.999
[2023-07-21 15:55:31,260] [ INFO] - adam_epsilon :1e-08
[2023-07-21 15:55:31,260] [ INFO] - bf16 :False
[2023-07-21 15:55:31,260] [ INFO] - bf16_full_eval :False
[2023-07-21 15:55:31,260] [ INFO] - current_device :gpu:0
[2023-07-21 15:55:31,260] [ INFO] - dataloader_drop_last :False
[2023-07-21 15:55:31,260] [ INFO] - dataloader_num_workers :0
[2023-07-21 15:55:31,260] [ INFO] - device :gpu
[2023-07-21 15:55:31,260] [ INFO] - disable_tqdm :False
[2023-07-21 15:55:31,260] [ INFO] - do_eval :False
[2023-07-21 15:55:31,260] [ INFO] - do_export :False
[2023-07-21 15:55:31,260] [ INFO] - do_predict :False
[2023-07-21 15:55:31,260] [ INFO] - do_train :False
[2023-07-21 15:55:31,260] [ INFO] - eval_batch_size :16
[2023-07-21 15:55:31,261] [ INFO] - eval_steps :None
[2023-07-21 15:55:31,261] [ INFO] - evaluation_strategy :IntervalStrategy.NO
[2023-07-21 15:55:31,261] [ INFO] - flatten_param_grads :False
[2023-07-21 15:55:31,261] [ INFO] - fp16 :False
[2023-07-21 15:55:31,261] [ INFO] - fp16_full_eval :False
[2023-07-21 15:55:31,261] [ INFO] - fp16_opt_level :O1
[2023-07-21 15:55:31,261] [ INFO] - gradient_accumulation_steps :1
[2023-07-21 15:55:31,261] [ INFO] - greater_is_better :None
[2023-07-21 15:55:31,261] [ INFO] - ignore_data_skip :False
[2023-07-21 15:55:31,261] [ INFO] - label_names :['start_positions', 'end_positions']
[2023-07-21 15:55:31,261] [ INFO] - lazy_data_processing :True
[2023-07-21 15:55:31,261] [ INFO] - learning_rate :5e-05
[2023-07-21 15:55:31,261] [ INFO] - load_best_model_at_end :False
[2023-07-21 15:55:31,261] [ INFO] - local_process_index :0
[2023-07-21 15:55:31,261] [ INFO] - local_rank :-1
[2023-07-21 15:55:31,261] [ INFO] - log_level :-1
[2023-07-21 15:55:31,261] [ INFO] - log_level_replica :-1
[2023-07-21 15:55:31,261] [ INFO] - log_on_each_node :True
[2023-07-21 15:55:31,261] [ INFO] - logging_dir :./checkpoint/model_best/runs/Jul21_15-55-25_jupyter-2631487-6518069
[2023-07-21 15:55:31,262] [ INFO] - logging_first_step :False
[2023-07-21 15:55:31,262] [ INFO] - logging_steps :500
[2023-07-21 15:55:31,262] [ INFO] - logging_strategy :IntervalStrategy.STEPS
[2023-07-21 15:55:31,262] [ INFO] - lr_scheduler_type :SchedulerType.LINEAR
[2023-07-21 15:55:31,262] [ INFO] - max_grad_norm :1.0
[2023-07-21 15:55:31,262] [ INFO] - max_steps :-1
[2023-07-21 15:55:31,262] [ INFO] - metric_for_best_model :None
[2023-07-21 15:55:31,262] [ INFO] - minimum_eval_times :None
[2023-07-21 15:55:31,262] [ INFO] - no_cuda :False
[2023-07-21 15:55:31,262] [ INFO] - num_train_epochs :3.0
[2023-07-21 15:55:31,262] [ INFO] - optim :OptimizerNames.ADAMW
[2023-07-21 15:55:31,262] [ INFO] - output_dir :./checkpoint/model_best
[2023-07-21 15:55:31,262] [ INFO] - overwrite_output_dir :False
[2023-07-21 15:55:31,262] [ INFO] - past_index :-1
[2023-07-21 15:55:31,262] [ INFO] - per_device_eval_batch_size :16
[2023-07-21 15:55:31,262] [ INFO] - per_device_train_batch_size :8
[2023-07-21 15:55:31,262] [ INFO] - prediction_loss_only :False
[2023-07-21 15:55:31,262] [ INFO] - process_index :0
[2023-07-21 15:55:31,262] [ INFO] - recompute :False
[2023-07-21 15:55:31,262] [ INFO] - remove_unused_columns :True
[2023-07-21 15:55:31,262] [ INFO] - report_to :['visualdl']
[2023-07-21 15:55:31,262] [ INFO] - resume_from_checkpoint :None
[2023-07-21 15:55:31,262] [ INFO] - run_name :./checkpoint/model_best
[2023-07-21 15:55:31,262] [ INFO] - save_on_each_node :False
[2023-07-21 15:55:31,262] [ INFO] - save_steps :500
[2023-07-21 15:55:31,263] [ INFO] - save_strategy :IntervalStrategy.STEPS
[2023-07-21 15:55:31,263] [ INFO] - save_total_limit :None
[2023-07-21 15:55:31,263] [ INFO] - scale_loss :32768
[2023-07-21 15:55:31,263] [ INFO] - seed :42
[2023-07-21 15:55:31,263] [ INFO] - sharding :[]
[2023-07-21 15:55:31,263] [ INFO] - sharding_degree :-1
[2023-07-21 15:55:31,263] [ INFO] - should_log :True
[2023-07-21 15:55:31,263] [ INFO] - should_save :True
[2023-07-21 15:55:31,263] [ INFO] - skip_memory_metrics :True
[2023-07-21 15:55:31,263] [ INFO] - train_batch_size :8
[2023-07-21 15:55:31,263] [ INFO] - warmup_ratio :0.0
[2023-07-21 15:55:31,263] [ INFO] - warmup_steps :0
[2023-07-21 15:55:31,263] [ INFO] - weight_decay :0.0
[2023-07-21 15:55:31,263] [ INFO] - world_size :1
[2023-07-21 15:55:31,263] [ INFO] -
[2023-07-21 15:55:31,263] [ INFO] - ***** Running Evaluation *****
[2023-07-21 15:55:31,263] [ INFO] - Num examples = 35
[2023-07-21 15:55:31,263] [ INFO] - Total prediction steps = 3
[2023-07-21 15:55:31,263] [ INFO] - Pre device batch size = 16
[2023-07-21 15:55:31,264] [ INFO] - Total Batch size = 16
100%|█████████████████████████████████████████████| 3/3 [00:03<00:00, 1.31s/it]
[2023-07-21 15:55:41,222] [ INFO] - -----Evaluate model-------
[2023-07-21 15:55:41,222] [ INFO] - Class Name: ALL CLASSES
[2023-07-21 15:55:41,222] [ INFO] - Evaluation Precision: 0.95082 | Recall: 0.92063 | F1: 0.93548
[2023-07-21 15:55:41,222] [ INFO] - -----------------------------
7.Taskflow一键部署
from pprint import pprint
from paddlenlp import Taskflow
schema = {
'项目名称': [
'结果',
'单位',
'参考范围'
]
}
my_ie = Taskflow("information_extraction", model="uie-x-base", schema=schema, task_path='./checkpoint/model_best')
pprint(my_ie({"doc": "test.jpg"}))
[{'项目名称': [{'bbox': [[417, 598, 764, 653]],
'end': 161,
'probability': 0.9931185709767476,
'relations': {'单位': [{'bbox': [[1383, 603, 1475, 653]],
'end': 170,
'probability': 0.9982062669088805,
'start': 166,
'text': 'ng/L'}],
'参考范围': [{'bbox': [[1603, 603, 1717, 650]],
'end': 175,
'probability': 0.994915152253455,
'start': 170,
'text': '0-0.2'}],
'结果': [{'bbox': [[1055, 608, 1161, 647]],
'end': 166,
'probability': 0.9779773840612904,
'start': 161,
'text': '0.000'}]},
'start': 150,
'text': '乙肝表面抗原HBsAg'},
{'bbox': [[420, 803, 807, 850]],
'end': 263,
'probability': 0.9839514684545492,
'relations': {'单位': [{'bbox': [[1382, 800, 1481, 856]],
'end': 272,
'probability': 0.9902134016753692,
'start': 268,
'text': 'U/mL'}],
'参考范围': [{'bbox': [[1609, 806, 1717, 845]],
'end': 277,
'probability': 0.9948578061238109,
'start': 272,
'text': '0-0.2'}],
'结果': [{'bbox': [[1055, 806, 1163, 853]],
'end': 268,
'probability': 0.9997722031372689,
'start': 263,
'text': '0.081'}]},
'start': 248,
'text': '乙肝e抗体Anti-HBeAB'},
{'bbox': [[417, 671, 863, 718]],
'end': 197,
'probability': 0.9933030680080606,
'relations': {'单位': [{'bbox': [[1383, 671, 1512, 717]],
'end': 208,
'probability': 0.993252639775573,
'start': 202,
'text': 'MIU/mL'}],
'参考范围': [{'bbox': [[1603, 671, 1697, 717]],
'end': 212,
'probability': 0.9968451209051636,
'start': 208,
'text': '0-10'}],
'结果': [{'bbox': [[1055, 676, 1163, 715]],
'end': 202,
'probability': 0.9627551951018489,
'start': 197,
'text': '0.000'}]},
'start': 181,
'text': '乙肝表面抗体Anti-HBsAB'},
{'bbox': [[420, 735, 706, 785]],
'end': 228,
'probability': 0.9925530039269148,
'relations': {'单位': [{'bbox': [[1383, 738, 1475, 785]],
'end': 237,
'probability': 0.9953925121749307,
'start': 233,
'text': 'U/mL'}],
'参考范围': [{'bbox': [[1606, 741, 1715, 780]],
'end': 242,
'probability': 0.9982005347972311,
'start': 237,
'text': '0-0.5'}],
'结果': [{'bbox': [[1057, 743, 1163, 782]],
'end': 233,
'probability': 0.9943726871306069,
'start': 228,
'text': '0.000'}]},
'start': 218,
'text': '乙肝e抗原HBeAg'},
{'bbox': [[420, 871, 870, 918]],
'end': 299,
'probability': 0.9931226228703274,
'relations': {'单位': [{'bbox': [[1389, 871, 1477, 918]],
'end': 308,
'probability': 0.9990609045893919,
'start': 304,
'text': 'U/mL'}],
'参考范围': [{'bbox': [[1611, 873, 1717, 912]],
'end': 313,
'probability': 0.9937555165322465,
'start': 308,
'text': '0-0.9'}],
'结果': [{'bbox': [[1054, 867, 1169, 921]],
'end': 304,
'probability': 0.9996564084931308,
'start': 299,
'text': '1.053'}]},
'start': 283,
'text': '乙肝核心抗体Anti-HBcAB'},
{'bbox': [[415, 536, 794, 580]],
'end': 130,
'probability': 0.9905078246100985,
'relations': {'单位': [{'bbox': [[1383, 536, 1475, 585]],
'end': 139,
'probability': 0.9996564019316949,
'start': 135,
'text': 's/co'}],
'参考范围': [{'bbox': [[1603, 533, 1745, 588]],
'end': 144,
'probability': 0.9937541085628041,
'start': 139,
'text': '阴性(-)'}],
'结果': [{'bbox': [[1055, 536, 1194, 582]],
'end': 135,
'probability': 0.9912728416351548,
'start': 130,
'text': '阴性(-)'}]},
'start': 118,
'text': '乙肝病毒前S1抗原HBV'}]}]
图像展示文章来源:https://www.toymoban.com/news/detail-599233.html
import matplotlib.pyplot as plt
from paddlenlp.utils.doc_parser import DocParser
results = my_ie({"doc": "test.jpg"})
img_show = DocParser.write_image_with_results(
"test.jpg",
result=results[0],
return_image=True)
plt.figure(figsize=(15,15))
plt.imshow(img_show)
plt.show()
项目地址:https://aistudio.baidu.com/aistudio/projectdetail/6518069?sUid=2631487&shared=1&ts=1690163802670文章来源地址https://www.toymoban.com/news/detail-599233.html
到了这里,关于AI识别检验报告 -PaddleNLP UIE-X 在医疗领域的实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!