PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
作者单位
旷视
目的
本文的目标是 通过扩展 PETR,使其有时序建模和多任务学习的能力 以此建立一个 强有力且统一的框架。
本文主要贡献:
- 将 位置 embedding 转换到 时序表示学习,时序的对齐 是在 3D PE 上做 姿态变换实现的。提出了 feature-guided 位置编码,可以通过 2D 图像特征 reweigth 3D PE
- 提出了一个简单但有效的方法(引入了基于特定任务的 queries),让 PETR 支持 多任务学习,包括 BEV 分割 和 3D lane 检测
- 本文提出的框架想,在 3D 目标检测,BEV 分割 和 3D lane 检测 上达到了 sota 的性能。
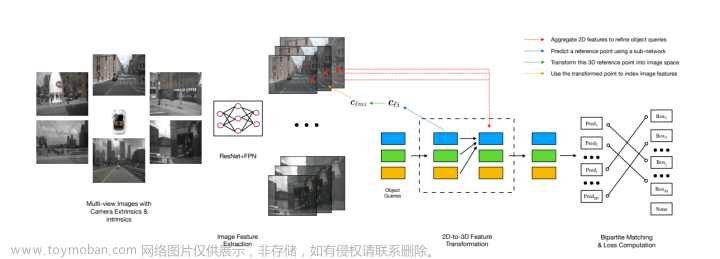
方法
网络结构

时序建模
时序建模:
3D 坐标对齐:
目的是将 t-1 帧的 3D 坐标 变换到 t 帧的 3D 坐标系统。
为了清楚的描述,这里定义一些符号:
- c(t): 相机坐标
- l(t) : lidar 坐标
- e(t) : 自车坐标
- g: 全局坐标
- T_dst^src : 原坐标系 到 目标坐标系的 变换矩阵
首先将 t-1 帧 和 t 帧 的 相机坐标系下的3D点集 投影到 雷达坐标系,然后 使用全局坐标系 作为桥梁 ,将 t-1帧雷达坐标系下的 3D点集 投影到 t 帧的 雷达坐标系下
对其之后的 t 帧 和 t-1帧的 点集 会被用于 生成 3D PE
Multi-task Learning
为了让 PETR 支持多任务学习,设计了不同的 queries,包括 BEV segmentation 和 3D lane detection
- BEV segmentation
刚开始在 BEV空间中 初始化一些 anchor points, 然后将这些 points 送入两层的 MLP 生成 seg queries
使用 CVT 中相同的 head 生成最后预测的分割结果
- 3D Lane Detection
3D anchor lanes 作为 query
每一个 lane 都是由 一个有序的 3d 坐标点集(n 个)组成的。这些点集都是沿着 Y轴 均匀采样的,这些 anchor 是与 Y轴 平行的。
3D 的 Lane head 会预测 lane 的 类别 以及 相对于 x 轴 和 Z 轴的偏移量。 同时由于每个车道线的长度是不固定的,所以也会预测 一个可见 向量 T (sizn n),用于控制 lane 的起始点
Feature-guided Position Encoder
PETR 中的 3D 坐标 到 3D 位置编码的 过程是 数据无关的。本文认为 3D PE 应该由 2D features 驱动,因为 图像特征 可以提供 一些信息的指导,比如深度信息。
因此在 PETRv2 中 将 2D features 经过两层 1x1 的卷积,然后最后经过一层 sigmoid 获得 attention weights,
3D 坐标 通过另一个 mlp 并与 attention weight 相乘生成 3D PE。3D PE 毁于 2D features 相加,作为 key 输入到 transformer decoder 中。
鲁棒性分析
虽然有很多关于自动驾驶系统的工作,但是只有极少数的工作 探究了 自动驾驶方法的 鲁棒性。本文针对几种 传感器的误差 对 算法的影响 进行了 探究。文章来源:https://www.toymoban.com/news/detail-599320.html
- 外参噪声
外参噪声是很常见的,比如相机抖动 导致 外参的不准。 - 相机丢失
- 相机时延
相机曝光的时间过长(比如在晚上),输入系统的图像可能是之前的图像,会对输出造成影响
鲁棒性分析结果文章来源地址https://www.toymoban.com/news/detail-599320.html
- 外参噪声
噪声越大,性能下降越多,FPE 可以提升 对 外参噪声的鲁棒性 - 相机丢失:front (5.05% mAP 下降) 和 back(13.19% mAP下降) 相机丢失带来的影响最大,其它的相机丢失噪声的性能下降要小一些。back的视角大一些 (120°),所以影响最大。(在 nuScenes 上的实验)
- 使用一些未标注的 frame 来代替 关键帧,来模拟时延,下降了 3.19% mAP 和 8.4% NDS(delay 0.083s),26.08 mAP 和 36.54% NDS (delay 0.3s)
到了这里,关于PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文笔记] SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving](https://imgs.yssmx.com/Uploads/2024/02/765392-1.png)