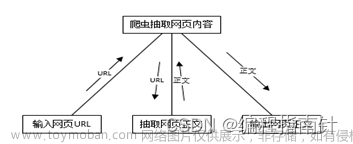
网络爬虫在各种不同的领域都有广泛的应用。它们可以用来收集,分析,处理和理解大量的在线信息。以下是网络爬虫的一些主要应用场景:
1. 搜索引擎
搜索引擎,如Google,Bing,和Baidu,是网络爬虫的最主要的应用场景。搜索引擎使用网络爬虫来抓取网页内容,然后对这些内容进行索引并存储在数据库中。当用户进行搜索时,搜索引擎会从数据库中查找匹配的结果。
例如,Google的网络爬虫会周期性地访问网站,抓取新的内容或者检查已经索引的内容是否有更新。这就是为什么你可以在Google上搜索到几乎所有的公开网页的原因。
2. 数据挖掘
数据挖掘是另一个网络爬虫的主要应用场景。数据科学家,市场研究员,和其他专业人士使用网络爬虫来收集大量的数据,然后使用统计和机器学习方法来分析这些数据,以找出有用的信息和模式。
例如,你可以使用网络爬虫来收集所有相关的Twitter推文,然后分析这些推文的情感,以了解公众对某个产品或者事件的感觉。
以下是一个简单的使用Python的requests和BeautifulSoup库来抓取网页内容的例子:
import requests
from bs4 import BeautifulSoup
url = 'https://twitter.com/search?q=product%20review&src=typed_query'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tweets = soup.find_all('div', class_='tweet')
for tweet in tweets:
content = tweet.find('p', class_='tweet-text').text
print(content)
3. 网络监控
网络爬虫也可以用于网络监控,比如检测网站是否正常运行,或者检测网站内容是否有变化。
例如,你可以编写一个网络爬虫,每分钟访问你的网站,如果网站无法访问,或者网站的某个关键部分的内容发生了变化,爬虫可以发送一个警报邮件给你。
4. 竞品分析
网络爬虫可以用于竞品分析,通过收集并分析竞争对手的信息,比如产品价格,产品特性,和用户评论等,来帮助商家制定更好的商业策略。
例如,你可以编写一个网络爬虫,定期访问你竞争对手的网站,收集他们的产品价格,然后分析价格趋势,以帮助你制定你的定价策略。
5. 价格比较
网络爬虫可以用于价格比较。通过抓取不同商家的商品价格,用户可以找到最低的价格。
例如,你可以编写一个网络爬虫,访问各大电商网站,抓取某个商品的价格,然后比较价格,找到最低的价格。
以上就是网络爬虫的一些主要应用场景。然而,值得注意的是,网络爬虫需要遵守法律和道德规则,不要抓取和使用不应该抓取和使用的数据。在抓取数据之前,你应该先阅读和理解网站的robots.txt文件和隐私政策。
推荐阅读:
https://mp.weixin.qq.com/s/dV2JzXfgjDdCmWRmE0glDA
https://mp.weixin.qq.com/s/an83QZOWXHqll3SGPYTL5g文章来源:https://www.toymoban.com/news/detail-599424.html
![[爬虫]1.1.3 网络爬虫的应用场景](https://imgs.yssmx.com/Uploads/2023/07/599424-1.jpg) 文章来源地址https://www.toymoban.com/news/detail-599424.html
文章来源地址https://www.toymoban.com/news/detail-599424.html
到了这里,关于[爬虫]1.1.3 网络爬虫的应用场景的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!