一、机器学习
1. 定义
计算机程序从经验E中学习,解决某一任务T,进行某一性能P,通过P测定在T上的表现因经验E而提高。
2. 例子
跳棋程序
E:程序自身下的上万盘棋局
T:下跳棋
P:与新对手下跳棋时赢的概率
二、监督学习Supervised Learning
1. 定义
给算法一个数据集,其中包含了正确答案,算法的目的是给出更多的正确答案。
2. 例子
(1)预测房价(回归问题)Regression problem
回归:Predict continuous valued output
目的:预测连续的数值输出

· 用直线拟合

· 用二次函数或二阶多项式拟合(效果更佳)

(2)预测肿瘤是良性或恶性(分类问题)
分类:Discrete valued output ( 0 or 1 )
目的: 预测离散值输出。就本问题而言,结果只有0和1的输出。

· 有两个特征影响的时候:

· 算法最终的目的是解决无穷多个特征的数据集
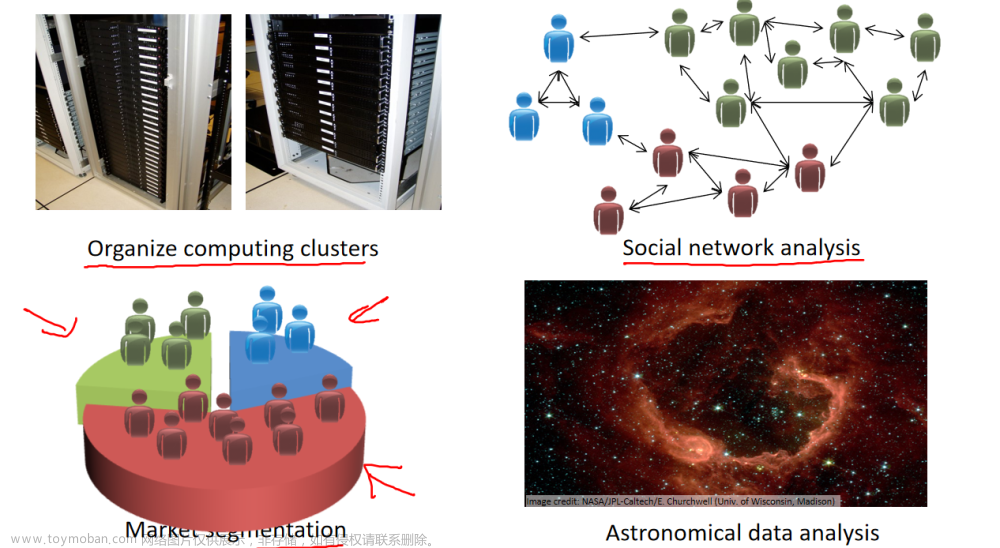
三、无监督学习Unsupervised Learning
1. 定义
只给算法一个数据集,但是不给数据集的正确答案,由算法自行分类。文章来源:https://www.toymoban.com/news/detail-599502.html
2. 聚类算法
(1)谷歌新闻每天收集几十万条新闻,并按主题分好类
(2)市场通过对用户进行分类,确定目标用户
(3)鸡尾酒算法:两个麦克风分别离两个人不同距离,录制两段录音,将两个人的声音分离开来(只需一行代码就可实现,但实现的过程要花大量的时间)文章来源地址https://www.toymoban.com/news/detail-599502.html
到了这里,关于【机器学习】吴恩达课程1-Introduction的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!