1.kafka概述
1.1 kafka的前世今生
kafka最初是LinkedIn的一个内部基础设施系统。最初开发的起因是,LinkedIn虽然有了数据库和其他系统可以用来存储数据,但是缺乏一个可以帮助处理持续数据流的组件。
所以在设计理念上,开发者不想只是开发一个能够存储数据的系统,如关系数据库、Nosql数据库、搜索引擎等等,更希望把数据看成一个持续变化和不断增长的流,并基于这样的想法构建出一个数据系统,一个数据架构。
Kafka外在表现很像消息系统,允许发布和订阅消息流,但是它和传统的消息系统有很大的差异:
- Kafka是个现代分布式系统,以集群的方式运行,可以自由伸缩。
- Kafka可以按照要求存储数据,保存多久都可以,
- 流式处理将数据处理的层次提示到了新高度,消息系统只会传递数据,Kafka的流式处理能力可以让我们用很少的代码就能动态地处理派生流和数据集。
Kafka不仅仅是一个消息中间件,同时它是一个流平台,这个平台上可以发布和订阅数据流(Kafka的流,有一个单独的包Stream的处理),并把他们保存起来,进行处理,这个是Kafka作者的设计理念。
大数据领域,Kafka还可以看成实时版的Hadoop,但是还是有些区别,Hadoop可以存储和定期处理大量的数据文件,往往以TB计数,而Kafka可以存储和持续处理大型的数据流。Hadoop主要用在数据分析上,而Kafka因为低延迟,更适合于核心的业务应用上。
1.2 主要用途
- 异步处理
- 应用解耦
- 流量削峰
- 日志处理
- 分布式消息处理
- 流式计算
2.预置环境和软件准备
2.1 环境安装包要求
- 虚拟机3台(我这里用了5台虚拟机:kafka01/kafka02/kafka03/kafka04/kafka05)
- CentOS == 7.9
- JDK >=1.8.0_181
- kafka_2.13-3.2.0
2.2 设置虚拟主机节点的主机名称
可以忽略, 不是特别重要
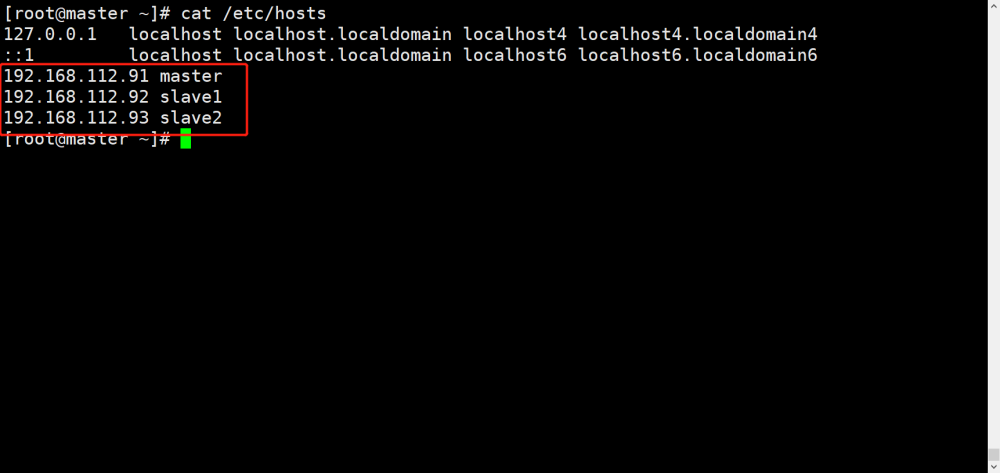
2.3 hosts文件配置

2.4 安装包下载
直接下载 kafka_2.13-3.2.0到虚拟机的命令如下
wget https://archive.apache.org/dist/kafka/3.2.0/kafka_2.13-3.2.0.tgz
2.5 解压到指定安装目录
解压 kafka_2.13-3.2.0到指定安装目录下
mkdir -p /home/saturn/software/kafka/kafka320
tar -zxf kafka_2.13-3.2.0.tgz -C /home/saturn/software/kafka/kafka320
mv /home/saturn/software/kafka/kafka320/kafka_2.13-3.2.0 /home/saturn/software/kafka/kafka320/kafka
2.6 配置kafka系统变量
vim ~/.bashrc 或者vim ~/.bash_profile或者vim /etc/profile都可以
#修改成你自己的jdk安装目录
JAVA_HOME=/home/saturn/software/java/jdk8
#修改成你自己的kafka安装目录
KAFKA_HOME=/home/saturn/software/kafka/kafka320/kafka
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$KAFKA_HOME/bin
保存修改之后执行以下命令让配置立即生效
source ~/.bash_profile
3.搭建kafka集群的几种方式介绍
3.1.使用zookeeper集群进行kafka集群搭建
3.1.1.配置zookeeper集群
kafka_2.13-3.2.0自带了zookeeper服务, 不需要额外搭建zookeeper集群服务,如果不想使用也可以使用自己搭建的zookeeper集群。
下面主要介绍如何使用kafka_2.13-3.2.0自带了zookeeper服务来搭建zookeeper集群
主要就是修改$KAFKA_HOME/config/zookeeper.properties, 如果是自己搭建的zookeeper集群, 修改的就是zoo.cfg配置文件, 修改zookeeper.properties配置文件如下
主要就是配置每台zookeeper节点的dataDir参数和增加集群配置,如下
# the directory where the snapshot is stored.
dataDir=/home/saturn/soft_data/zookeeper_data
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
server.0=kafka01:2888:3888
server.1=kafka02:2888:3888
server.2=kafka03:2888:3888
server.3=kafka04:2888:3888
server.4=kafka05:2888:3888
修改完毕之后, 保存修改, 其他的4个节点上的zookeeper.properties也做同样修改, 修改完成之后保存即可。
然后再我们设置的zookeeper的数据保存目录dataDir目录下,创建一个myid的`文本文件
kafka01节点上的$dataDir/myid文件内容如下:
0
保存退出
kafka02节点上的$dataDir/myid文件内容如下:
1
保存退出
其他的三个节点上的设置也同上。
注意:每一台节点上的myid文件中写的id数字需要与在zookeeper.properties中配置的保持一致, 如果当前节点是kafka01,则myid文件中写入的id就是0, 如果当前节点是kafka02,则myid文件中写入的id就是1,就是这个意思,不知道有没有表达清楚。
3.1.2.启动zookeeper集群
因为我之前已经配置了kafka的系统环境变量, 我这里可以直接使用kafka的bin目录下的可执行shell脚本来启动kafka的zookeeper服务
zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
或者进入到$KAFKA_HOME/config目录下执行
cd $KAFKA_HOME/config
zookeeper-server-start.sh ./zookeeper.properties
如果你没有配置kafka的系统环境变量, 可以使用一下两个命令来进行启动
cd /你的kafka的安装目录/bin
./zookeeper-server-start.sh ../config/zookeeper.properties
或者使用绝对路径
/你的kafka的安装目录/bin/zookeeper-server-start.sh /你的kafka的安装目录/config/zookeeper.properties
将kafka01/kafka02``kafka03``kafka04``kafka05的zookeeper服务都通过以上任意一种方式启动起来,启动成功之后检查zookeeper的运行状态
jps

或者
ps -ef|grep zookeeper

3.1.3.配置kafka集群
主要就是修改$KAFKA_HOME/config/server.properties, 修改的主要配置内容包含以下几项:
现在以kafka01节点上的配置修改为例进行说明, 其他的主机节点(kafka02,kafka03,kafka04,kafka05)修改都类似
##broker节点的唯一标识,集群中的每一台都需要唯一
broker.id=0
##指定 Kafka 代理绑定的网络接口和端口号,以接收来自客户端和其他代理的连接
listeners=PLAINTEXT://kafka01:9092
##指定 Kafka 日志文件的存储目录。Kafka 使用日志来存储消息。
log.dirs=/home/saturn/soft_data/kafka_data/kafka-logs
##存储消费者位移(offsets)的主题的副本因子
offsets.topic.replication.factor=3
##指定用于协调 Kafka 集群的 ZooKeeper 连接字符串
zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181,kafka04:2181,kafka05:2181/kafka
##zookeeper连接的超时时间设置
zookeeper.connection.timeout.ms=30000
其他主机节点需要修改的就是broker.id及listeners中的域名配置, 其他配置参数调优可以在之后再进行修改操作。
3.1.4.启动kafka集群
因为我之前已经配置了kafka的系统环境变量, 我这里可以直接使用kafka的bin目录下的可执行shell脚本来启动kafka的zookeeper服务
kafka-server-start.sh $KAFKA_HOME/config/server.properties
或者进入到$KAFKA_HOME/config目录下执行
cd $KAFKA_HOME/config
kafka-server-start.sh ./server.properties
如果你没有配置kafka的系统环境变量, 可以使用一下两个命令来进行启动
cd /你的kafka的安装目录/bin
./kafka-server-start.sh ../config/server.properties
或者使用绝对路径
/你的kafka的安装目录/bin/kafka-server-start.sh /你的kafka的安装目录/config/server.properties
将kafka01/kafka02``kafka03``kafka04``kafka05的broker服务都通过以上任意一种方式启动起来,启动成功之后检查kafka的运行状态
jps
或者
ps -ef|grep kafka

通过以上步骤, 我们截止zookeeper搭建kafka集群的操作就全部完成了,整个过程也很简单, 但是需要心细, 尤其是集群参数配置修改这块儿,不熟练可以多操作演练几次就好了。
3.2.使用kraft进行kafka集群搭建
kafka在3.x的版本之后提供了了另外一种方式取代使用zookeeper分布式协调的功能, 就是kraft,
如果我们希望想使用kraft来进行kafka集群的操作, 可以按照一下步骤进行操作配置。
3.2.1.kraft的配置文件
在kafka安装目录下的config目录下有一个kraft目录
如果需要使用kraft来启动kafka,就必须修改这个目录下的kafka的配置文件
下面说说搭建kafka集群都需要修改那些配置参数:
这里我们使用kafka01来进行演示
修改kafka01机器上 config/kraft/server.properties文件,部分参数需要根据自己需要进行修改
process.roles=broker,controller
#这里需要修改
node.id=1
#这里需要修改(我这里kafka集群一共5台节点。所以这里配置的是5个, 你有多少个就配置多少个)
controller.quorum.voters=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093,4@kafka04:9093,5@kafka03:9093
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
#这里需要修改(这里需要根据当前节点的域名或者IP进行修改,如果是kafka01就修改成kafka01的域名或者公网IP)
advertised.listeners=PLAINTEXT://kafka01:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
#这里需要修改(修改成你自定义的kraft日志存储目录)
#log.dirs=/tmp/kraft-combined-logs
#log.dirs=/home/saturn/soft_data/zookeeper_data/kraft-combined-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
其他4台机器上的机器的 advertised.listeners和 node.id也需要修改
3.2.2.kraft初始化kafka集群
初始化集群数据目录:
kafka-storage.sh random-uuid
会生成一个随机的clusterId字符串,这个字符串在下面的命令中需要使用
每台机器执行:
##此处-t参数后面跟的字符串就是上面生成的随机的clusterId字符串
bin/kafka-storage.sh format -t EzhjsV8IS3SwDFK42SbSnA -c $KAFKA_HOME//config/kraft/server.properties
#启动kafka集群
kafka-server-start.sh -daemon $KAFKA_HOME/config/kraft/server.properties
4. kafka的命令行操作演示
4.1.kafka中topic脚本参数说明及使用示例
4.1.1.kafka-topics.sh参数说明
| 参数名称 | 是否必传 | 解释说明 |
|---|---|---|
| –bootstrap-server | 是 | 指定 Kafka 代理的地址和端口号 |
| –create | 否 | 创建一个新的主题 |
| –list | 否 | 列出当前 Kafka 集群中的所有主题 |
| –topic | 否 | 指定要创建或操作的主题名称 |
| –describe | 否 | 显示指定主题的详细信息,包括分区和副本的分配情况 |
| –delete | 否 | 删除指定的主题 |
| –force | 否 | 强制删除,删除主题时不需要确认提示 |
| –if-not-exists | 否 | 如果在创建主题时设置,则仅当主题尚不存在时才会执行该操作。 |
| –if-exists | 否 | 如果在更改、删除或描述主题时设置,则仅当主题存在时才会执行该操作。 |
| –partitions | 否 | 指定要为主题创建的分区数量 |
| –replication-factor | 否 | 指定主题的副本因子,即每个分区的副本数量 |
| –version | 否 | 查看kafka的版本号 |
| –help | 否 | 查看kafka-topics.sh的参数选项说明 |
4.1.2.kafka-topics.sh的实操使用案例
- 列出所有主题
kafka-topics.sh --bootstrap-server localhost:9092 --list
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
- 列出主题test01的详细信息
kafka-topic.sh --bootstrap-server localhost:9092 --topic test01 --describe
如果我们希望从外网的kafkaClient可访问我们创建的topic,这里在进行--bootstrap-server参数设置的时候最好使用当前节点的域名:9092或者公网IP:9092来进行topic创建, 一下的topic操作命令以及producer端以及consumer端的操作都是如此, 请知!
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
- 创建主题名 test02 ,1副本,1分区
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test02 --replication-factor 1 --partitions 1
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
- 创建主题名为test01(如果不存在则创建)
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test02 --replication-factor 1 --partitions 1 --if-not-exists
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
- 修改主题test02的分区数从1个修改成2个(注意:分区无法被删除)
kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic test01 --partitions 2
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
**解释说明:**可能有同学对上面说的这个分区无法被删除不太理解,为什么不能删, 因为我们的消息都回被投放到分区,消息被投放到分区的策略如果时随机的话, 一旦当前topic被使用, 我们无法确定消息被投放到那个分区中去了, 是否已经被消费,如果此时分区被删除, 就无法保证消息被正常的消费, 从而导致数据丢失, 这是我们无法接受的,所以分区只能扩容, 不能缩容。
-
删除不存在的主题test03
-
删除主题test02(如果存在名称为test02的主题则删除)
4.2.kafka中producer脚本参数说明及使用示例
kafka-console-producer.sh 是 Kafka 提供的一个命令行工具,用于从控制台向 Kafka 主题发送消息。
4.2.1.kafka-console-producer.sh参数说明
| 参数名称 | 是否必传 | 解释说明 |
|---|---|---|
| –broker-list(3.x已弃用) | 是 | 指定 Kafka 代理的地址和端口号,多个代理以逗号分隔(3.x版本已过时,使用–boostrap-server) |
| –boostrap-server | 是 | 指定 Kafka 代理的地址和端口号,多个代理以逗号分隔() |
| –topic | 是 | 指定要发送消息的主题名称 |
| –compression-codec | 否 | 设置消息的压缩编解码器,可选值为 “none”、“gzip”、“snappy” 或 “lz4” |
| –sync | 否 | 每条消息都等待服务器确认后再发送下一条消息 |
| –timeout | 否 | 设置发送消息的超时时间,单位为毫秒 |
| –batch-size | 否 | 生产者在发送到代理之前等待的消息累积大小。较大的批量大小可以提高吞吐量,但可能会增加延迟。默认值为16KB。 |
| –max-message-size | 否 | 设置发送消息的最大大小限制 |
| –property | 否 | 设置生产者的属性 |
| –help | 否 | 该命令将显示 kafka-console-producer.sh 的完整帮助文档,包括参数说明和示例用法 |
Kafka 生产者(Producer)具有多个配置参数,用于控制其行为和性能。以下是 Kafka 生产者的一些常用配置参数及其解释说明:
| 参数名称 | 解释说明 |
|---|---|
| bootstrap.servers | Kafka 代理的地址和端口列表,用于建立与 Kafka 集群的连接。例如:bootstrap.servers=localhost:9092
|
| acks | 指定生产者发送消息后需要收到的确认数。可选值包括: 0:生产者不等待任何确认,直接将消息发送出去。这是最低延迟和最高吞吐量的配置,但可能会导致消息丢失。 1:生产者在主分区(leader)收到消息后收到确认。这提供了更好的可靠性,但仍然存在丢失消息的风险。 all:生产者在所有副本都收到消息后才收到确认。这是最安全的配置,但会带来较高的延迟。 |
| retries | 发送消息时的重试次数。如果消息发送失败,生产者将自动重试。默认值为0,表示不进行重试。 |
| batch.size | 生产者在发送到代理之前等待的消息累积大小。较大的批量大小可以提高吞吐量,但可能会增加延迟。默认值为16KB。 |
| linger.ms | 控制生产者在发送批量之前等待的时间。较高的值可以增加批量大小和吞吐量,但会增加一定的延迟。默认值为0,表示没有等待。 |
| buffer.memory | 生产者用于缓冲待发送消息的总内存大小。这个缓冲区用于存储尚未发送到服务器的消息。默认值为32MB。 |
| compression.type | 指定消息的压缩类型。可选值包括: - none:不压缩消息。- gzip:使用 GZIP 压缩算法压缩消息。- snappy:使用 Snappy 压缩算法压缩消息。- lz4:使用 LZ4 压缩算法压缩消息。 |
| max.in.flight.requests.per.connection | 控制生产者在没有收到任何确认之前可以发送的最大未确认请求数量。较高的值可以提高吞吐量,但可能会导致消息重排。默认值为5。 |
| max.request.size | 控制单个消息的最大大小。默认值为1MB。 |
| key.serializer | 指定的键序列化器类。这些序列化器将键和值对象转换为字节数组以进行传输。 |
| value.serializer | 指定的值序列化器类。这些序列化器将键和值对象转换为字节数组以进行传输。 |
更多配置参数参见Apache Kafka Procuder Configs
4.2.2.kafka-console-producer.sh的实操使用案例
- 创建生产者-控制台(全部使用默认参数)
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test01
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
- 创建生产者-控制台(设置同步发送消息,每条消息都等待服务器确认后再发送下一条消息)
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test01 --sync
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
- 创建生产者-控制台(设置其他的属性)
kafka-console-producer.sh --broker-list localhost:9092 --topic test01 --property acks=all --property retries=3
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
4.3.kafka中consumer脚本参数说明及使用示例
kafka-console-consumer.sh 是 Kafka 提供的一个命令行工具,用于从 Kafka 主题中消费消息。
4.3.1.kafka-console-consumer.sh参数说明
| 参数名称 | 是否必传 | 解释说明 |
|---|---|---|
| –boostrap-server | 是 | 指定 Kafka 代理的地址和端口号,多个代理以逗号分隔() |
| –topic | 是 | 指定要消费消息的主题名称 |
| –from-beginning | 否 | 从主题的开头开始消费消息,即使消费组的偏移量已存在 |
| –consumer.config | 否 | 指定消费者的配置文件 |
| –partition | 否 | 指定要消费的分区号 |
| –group | 否 | 指定消费者所属的消费组。 |
| –offset | 否 | 指定要从哪个偏移量开始消费消息 |
| –max-messages | 否 | 指定要消费的最大消息数量 |
| –timeout-ms | 否 | 设置消费者在没有新消息时等待的超时时间(毫秒) |
| –property | 否 | 设置消费者的属性 |
| –help | 否 | 该命令将显示 kafka-console-producer.sh 的完整帮助文档,包括参数说明和示例用法 |
Kafka 消费者(Consumer)具有多个配置参数,用于控制其行为和性能。以下是 Kafka 生产者的一些常用配置参数及其解释说明:
| 参数名称 | 解释说明 |
|---|---|
| bootstrap.servers | Kafka 代理的地址和端口列表,用于建立与 Kafka 集群的连接。例如:bootstrap.servers=localhost:9092
|
| group.id | 消费者所属的消费组的唯一标识符。消费者通过组ID进行协调,以实现消息的分区和负载均衡。 |
| enable.auto.commit | 指定是否启用自动提交消费位移(offset)。如果设置为 true,消费者将定期自动提交位移;如果设置为 false,则需要手动提交位移。默认值为 true。 |
| auto.commit.interval.ms | 自动提交位移的时间间隔(毫秒)。只有当 enable.auto.commit 设置为 true 时才有效。默认值为 5000 毫秒。 |
| fetch.min.bytes | 每次拉取请求的最小字节数。如果可用数据少于此值,则消费者将等待更多数据的到来。默认值为 1。 |
| fetch.max.wait.ms | 等待从服务器获取数据的最长时间(毫秒)。如果在指定的时间内没有可用数据,则消费者将返回空结果。默认值为 500 毫秒。 |
| max.poll.records | 每次调用 poll() 方法时返回的最大记录数。这个值限制了每次轮询期间可以处理的最大记录数。默认值为 500。 |
| auto.offset.reset | 当消费者在初始加入消费组或者没有可用位移时的重置行为。可选值包括: earliest:从最早的可用位移开始消费。 latest:从最新的可用位移开始消费。 none:如果没有可用位移,则抛出异常。 |
| key.serializer | 指定的键序列化器类。这些序列化器将键和值对象转换为字节数组以进行传输。 |
| value.serializer | 指定的值序列化器类。这些序列化器将键和值对象转换为字节数组以进行传输。 |
更多配置参数参见Apache Kafka Consumer Configs
4.3.2.kafka-console-consumer.sh的实操使用案例
- 创建消费者-控制台(全部使用默认参数)
进入到kafka的安装目录下的config目录下(比如:/opt/bigdata/kafka/config)执行命令(这里需要先配置kafka的系统变量,就是把kafka的bin目录添加到系统环境变量里面, 跟java/go/python配置系统环境变量是一样的)
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test01 --from-beginning --consumer.config ./consumer.properties
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。
生产者端生产消息
消费者端消费消息
4.5.kafka启动命令
kafka-server-start.sh -deamon $KAFKA_HOME/config/server.properties
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。文章来源:https://www.toymoban.com/news/detail-599609.html
4.4.kafka停止命令
kafka-server-stop.sh
以上命令, 如果配置系统环境变量, 请先cd命令切换到kafka的安装路径的bin目录下再执行。文章来源地址https://www.toymoban.com/news/detail-599609.html
到了这里,关于分布式消息流处理平台kafka(一)-kafka单机、集群环境搭建流程及使用入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!