这篇简要说下清华开源项目 ChatGLM 本地部署的详细教程。清华开源项目 ChatGLM-6B 已发布开源版本,这一项目可以直接部署在本地计算机上做测试,无需联网即可体验与 AI 聊天的乐趣。
项目地址:GitHub - THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model
官网介绍:
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
第一步,本地安装 Python
这一步暂略,可以自行下载安装 Python 环境。
Python 下载地址:Download Python | Python.org
注意:安装 >9 以上版本,建议安装 10。
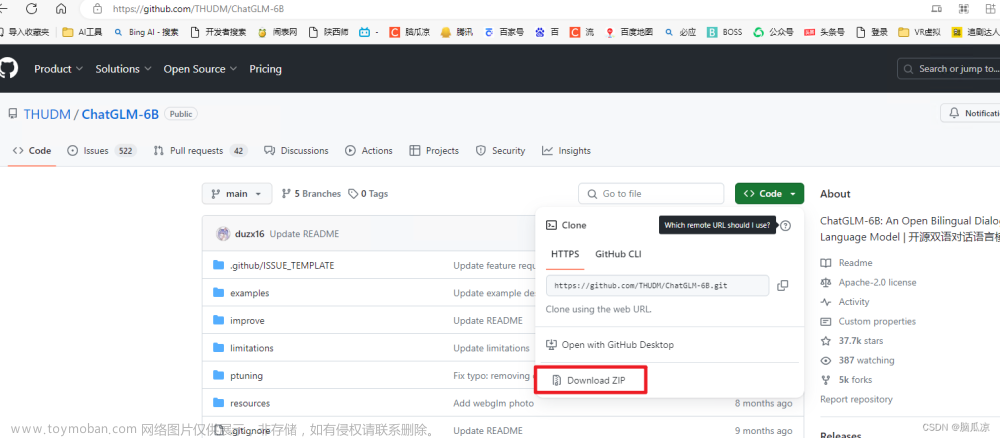
第二步,下载项目程序包
地址见上面的项目地址,直接下载下来并解压。我这里解压到 E:\chatGPT\ 下。

第三步,下载模型包 chatglm
下载地址:https://huggingface.co/THUDM/chatglm-6b/tree/main
官网介绍:
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
注意:下载后放到第二步程序包下,自行创建目录 chatglm-6b,如下:

第四步,下载依赖包
Window + R 快捷键打开运行窗口,输入 cmd 打开控制台命令行,进入到程序目录下。

分别执行如下两条命令:
pip install -r requirements.txt
pip install gradio
注意:如果执行有报错,请查阅文章末尾的错误处理。

等待依赖包下载成功,结果如下:

第五步,运行网页版 demo
执行如下命令,运行网页版本的 demo,如下:
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
执行结果如下:

注意:如果执行提示信息和上图对不上,请查阅文章末尾的错误处理。
第七步,测试网页版程序
浏览器打开地址 并访问,输入问题,可以看到 ChatGLM 会给予回复。

Very Good!查看电脑性能,感觉 CPU 和内存都要爆掉了 ^ ^


第八步,运行命令行 Demo
执行如下命令,运行命令行版本的 demo,如下:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。

错误一:下载依赖包超时
E:\chatGPT\ChatGLM-6B-main>pip install -r requirements.txt
Collecting protobuf<3.20.1,>=3.19.5
Downloading protobuf-3.20.0-cp310-cp310-win_amd64.whl (903 kB)
---------------------------------------- 903.8/903.8 kB 4.0 kB/s eta 0:00:00
Collecting transformers==4.27.1
Downloading transformers-4.27.1-py3-none-any.whl (6.7 MB)
----------- ---------------------------- 2.0/6.7 MB 5.4 kB/s eta 0:14:29
ERROR: Exception:
Traceback (most recent call last):
File "D:\Python\Python310\lib\site-packages\pip\_vendor\urllib3\response.py", line 438, in _error_catcher
yield
File "D:\Python\Python310\lib\site-packages\pip\_vendor\urllib3\response.py", line 561, in read
data = self._fp_read(amt) if not fp_closed else b""
File "D:\Python\Python310\lib\site-packages\pip\_vendor\urllib3\response.py", line 527, in _fp_read
return self._fp.read(amt) if amt is not None else self._fp.read()
File "D:\Python\Python310\lib\site-packages\pip\_vendor\cachecontrol\filewrapper.py", line 90, in read
data = self.__fp.read(amt)
File "D:\Python\Python310\lib\http\client.py", line 465, in read
s = self.fp.read(amt)
File "D:\Python\Python310\lib\socket.py", line 705, in readinto
return self._sock.recv_into(b)
File "D:\Python\Python310\lib\ssl.py", line 1274, in recv_into
return self.read(nbytes, buffer)
File "D:\Python\Python310\lib\ssl.py", line 1130, in read
return self._sslobj.read(len, buffer)
TimeoutError: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Python\Python310\lib\site-packages\pip\_internal\cli\base_command.py", line 160, in exc_logging_wrapper
status = run_func(*args)
File "D:\Python\Python310\lib\site-packages\pip\_internal\cli\req_command.py", line 247, in wrapper
return func(self, options, args)
File "D:\Python\Python310\lib\site-packages\pip\_internal\commands\install.py", line 419, in run
requirement_set = resolver.resolve(
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\resolver.py", line 92, in resolve
result = self._result = resolver.resolve(
File "D:\Python\Python310\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 481, in resolve
state = resolution.resolve(requirements, max_rounds=max_rounds)
File "D:\Python\Python310\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 348, in resolve
self._add_to_criteria(self.state.criteria, r, parent=None)
File "D:\Python\Python310\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 172, in _add_to_criteria
if not criterion.candidates:
File "D:\Python\Python310\lib\site-packages\pip\_vendor\resolvelib\structs.py", line 151, in __bool__
return bool(self._sequence)
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\found_candidates.py", line 155, in __bool__
return any(self)
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\found_candidates.py", line 143, in <genexpr>
return (c for c in iterator if id(c) not in self._incompatible_ids)
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\found_candidates.py", line 47, in _iter_built
candidate = func()
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\factory.py", line 206, in _make_candidate_from_link
self._link_candidate_cache[link] = LinkCandidate(
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 297, in __init__
super().__init__(
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 162, in __init__
self.dist = self._prepare()
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 231, in _prepare
dist = self._prepare_distribution()
File "D:\Python\Python310\lib\site-packages\pip\_internal\resolution\resolvelib\candidates.py", line 308, in _prepare_distribution
return preparer.prepare_linked_requirement(self._ireq, parallel_builds=True)
File "D:\Python\Python310\lib\site-packages\pip\_internal\operations\prepare.py", line 491, in prepare_linked_requirement
return self._prepare_linked_requirement(req, parallel_builds)
File "D:\Python\Python310\lib\site-packages\pip\_internal\operations\prepare.py", line 536, in _prepare_linked_requirement
local_file = unpack_url(
File "D:\Python\Python310\lib\site-packages\pip\_internal\operations\prepare.py", line 166, in unpack_url
file = get_http_url(
File "D:\Python\Python310\lib\site-packages\pip\_internal\operations\prepare.py", line 107, in get_http_url
from_path, content_type = download(link, temp_dir.path)
File "D:\Python\Python310\lib\site-packages\pip\_internal\network\download.py", line 147, in __call__
for chunk in chunks:
File "D:\Python\Python310\lib\site-packages\pip\_internal\cli\progress_bars.py", line 53, in _rich_progress_bar
for chunk in iterable:
File "D:\Python\Python310\lib\site-packages\pip\_internal\network\utils.py", line 63, in response_chunks
for chunk in response.raw.stream(
File "D:\Python\Python310\lib\site-packages\pip\_vendor\urllib3\response.py", line 622, in stream
data = self.read(amt=amt, decode_content=decode_content)
File "D:\Python\Python310\lib\site-packages\pip\_vendor\urllib3\response.py", line 560, in read
with self._error_catcher():
File "D:\Python\Python310\lib\contextlib.py", line 153, in __exit__
self.gen.throw(typ, value, traceback)
File "D:\Python\Python310\lib\site-packages\pip\_vendor\urllib3\response.py", line 443, in _error_catcher
raise ReadTimeoutError(self._pool, None, "Read timed out.")
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.
E:\chatGPT\ChatGLM-6B-main>可以看到错误信息提示超时,应该是网络问题,可以尝试在命令中加上超时时间设置的参数,命令修改后如下:
pip --default-timeout=1688 install -r requirements.txt
问题二:又一次实时下载模型包

当运行程序时,如果提示信息中看到又一次下载模型包,而没有使用第三步提前准备的模型包时,需要把模型包复制到程序运行时的缓存目录中,缓存路径可能如下:
C:\Users\用户目录\.cache\huggingface\hub\models--THUDM--chatglm-6b\snapshots\fb23542cfe773f89b72a6ff58c3a57895b664a23
模型包拷贝到该目录后再次运行程序即可。文章来源:https://www.toymoban.com/news/detail-599660.html
Good Luck!文章来源地址https://www.toymoban.com/news/detail-599660.html
到了这里,关于ChatGLM 本地部署搭建及测试运行的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!