HDFS
整体概述举例:

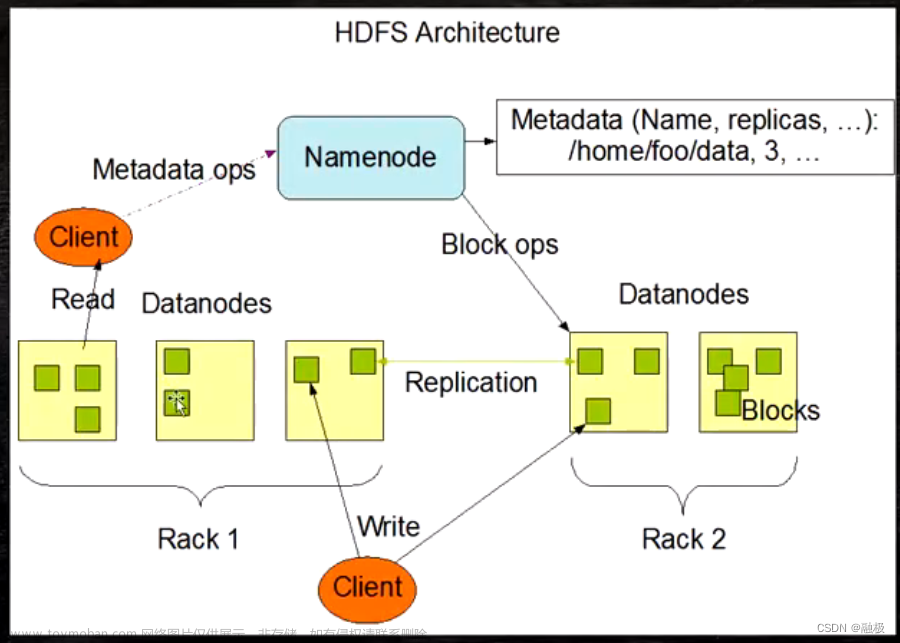
包括机架 rack1、rack2 包括5个Datanode,一个Namenode(主角色)带领5个Datanode(从角色),每一个rack中包含不同的block模块文件为分块存储模式。块与块之间通过replication进行副本备份,进行冗余存储,Namenode对存储的元数据进行记录。该架构可以概括为一个抽象统一的目录树结构。
-
主从架构
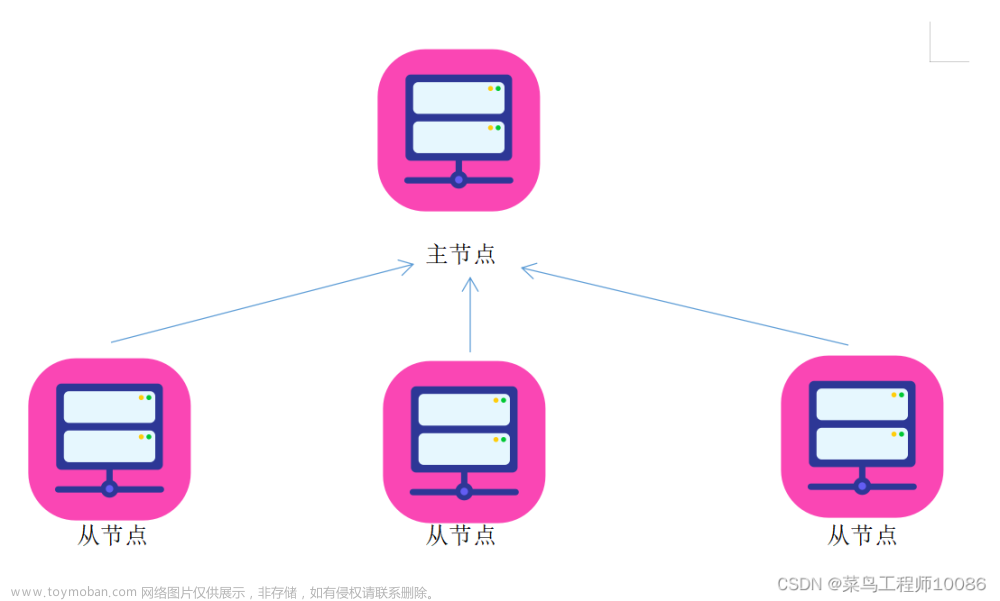
HDFS集群是标准的master/slave主从架构群,一般一个HDFS集群有一个Namenode和一定数目的Datanode组成,Namenode是HDFS主节点(维护元数据),Datanode(管理数据块)是HDFS从节点,两种角色共同完成分布式文件的存储服务。
-
分块存储
HDFS中文件在物理上是分块存储的,每一块默认大小是128M,不足128M则自身为一块。
块的大小可以通过配置参数来规定,位于hdfs-default.xml中,dfs.blocksize。
-
副本机制
文件的每个block都会有副本,副本系数可以在文件创建的时候指定,也可以在之后通过命令改变,副本数量由参数dfs.replication控制,默认数为3,连同本身共三块副本。
-
元数据(解释型数据)管理
HDFS中元数据包括两种类型:
1)文件自身属性信息:文件名称、权限,修改时间、文件大小、复制因子、数据块大小。
2)文件块位置映射信息:记录文件块和Datenode之间的映射信息,即哪个块位于哪个节点上。
-
抽象目录树(namespace)
即传统的层次文件组织结构。用户可以创建目录,然后将文件保存在目录中,Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下。
-
数据块存储
文件各个block的具体存储管理由DataNode节点承担,每一个block都可以在多个DataNode上存储。
常用操作
文件系统的shell命令 hadoop fs [generic options]
hadoop fs -ls file:/// #操作本地文件系统
hadoop fs -ls hdfs://node1:8020/ #操作HDFS分布文件系统
hadoop fs -ls / #直接根目录,没有指定协议,将加载读取fs.defaultFS
2.创建文件夹 hadoop fs -mkdir [-p]
… (-p 沿着路径创建父目录)
3.查看指定目录下内容 hadoop fs -ls [-h] [-R] [
…]
4.上传文件到HDFS指定目录下 hadoop fs -put [-f] [-p] … ( -f覆盖目标文件【已经存在下】,-p保留访问和修改时间,所有权和权限,localsrc本地文件系统, dst目标文件系统)
5.查看HDFS文件内容 hadoop fs -cat … 读取指定文件全部内容,显示在标准输出控制台。
6.下载HDFS文件 hadoop fs -get [-f] [-p] … (下载文件到本地文件系统指定目录, localdst必须是目录, -f 覆盖目标文件 -p保留访问和修改时间,所有权和权限)
7.拷贝HDFS文件 hadoop fs -cp [-f] …(-f 覆盖目标文件)
8.追加数据到HDFS文件中 hadoop fs -appendToFile …(将所有给定本地文件的内容追加到给定dst文件,dst如果不存在,将创建该文件)文章来源:https://www.toymoban.com/news/detail-599706.html
工作流程
 文章来源地址https://www.toymoban.com/news/detail-599706.html
文章来源地址https://www.toymoban.com/news/detail-599706.html
- 管道传输
- ACK校验
- 副本原则
到了这里,关于HDFS Hadoop分布式文件存储系统整体概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!