全文链接:http://tecdat.cn/?p=22813
本教程为读者提供了使用频率学派的广义线性模型(GLM)的基本介绍。具体来说,本教程重点介绍逻辑回归在二元结果和计数/比例结果情况下的使用,以及模型评估的方法(点击文末“阅读原文”获取完整代码数据)。
本教程使用教育数据例子进行模型的应用。此外,本教程还简要演示了用R对GLM模型进行的多层次扩展。最后,还讨论了GLM框架中的更多分布和链接函数。
相关视频
本教程包含以下结构。
1. 准备工作。
2. 介绍GLM。
3. 加载教育数据。
4. 数据准备。
5. 二元(伯努利)Logistic回归。
6. 二项式 Logistic 回归。
7. 多层次Logistic回归。
8. 其他族和链接函数。
本教程介绍了:
- 假设检验和统计推断的基本知识。
- 回归的基本知识。
- R语言编码的基本知识。
- 进行绘图和数据处理的基本知识。
广义线性模型(GLM)简介
对于y是连续值得情况,我们可以用这种方式处理,但当y是离散值我们用普通线性模型就不合适了,这时我们引用另外一种模型 --- Generalised Linear Models 广义线性模型。
为了获取GLM模型,我们列出3个条件:
 ,也就是y|x为指数族分布,指数族分布形式:
,也就是y|x为指数族分布,指数族分布形式: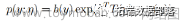
2. 如果我们判断y的假设为  ,则
,则 。
。
3. 自然参数和输入x呈线性关系:
这3个条件的来由我们不讨论,我们只知道做这样的假设是基于“设计”的选择,而非必然。
我们以泊松回归为例, y服从泊松分布 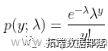 ,化为指数族形式,我们可以得到
,化为指数族形式,我们可以得到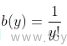
 。所以
。所以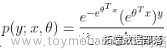
之后即为最大似然法的过程。
教育数据
本教程中使用的数据是教育数据。
该数据来源于全国性的小学教育调查。数据中的每一行都是指一个学生。结果变量留级是一个二分变量,表示一个学生在小学教育期间是否留过级。学校变量表示一个学生所在的学校。个人层面的预测因素包括。 性别(0=女性,1=男性)和学前教育(受过学前教育,0=没有,1=有)。学校层面是学校平均SES(社会经济地位)得分。
本教程利用教育数据试图回答的主要研究问题是。
忽略数据的结构,性别和学前教育对学生是否留级的影响是什么?
忽略数据的结构,学校平均SES对学生留级比例的影响是什么?
考虑到数据的结构,性别、学前教育和学校平均SES对学生是否留级有什么影响?
这三个问题分别用以下这些模型来回答:二元逻辑回归;二项逻辑回归;多层次二元逻辑回归。
数据准备
加载必要的软件包
# 如果你还没有安装这些包,请使用install.packages("package_name")命令。
library(lme4) # 用于多层次模型
library(tidyverse) # 用于数据处理和绘图导入数据
head(Edu)
数据处理
mutate(学校 = factor(学校),
性别 = if_else(性别 == 0, "girl", "boy"),
性别 = factor(性别, levels = c("girl", "boy")),
受过学前教育 = if_else(受过学前教育 == 0, "no", "yes"),
受过学前教育 = factor(受过学前教育, levels = c("no", "yes")))
检查缺失的数据
summarise_each((~sum(is.na(.))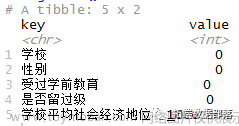
数据中,经济地位变量有1066个观测值缺失。对缺失数据的处理本身就是一个复杂的话题。为了方便起见,我们在本教程中简单地将数据缺失的案例删除。
二元逻辑回归
探索数据:按性别和学前教育分类的留级数量
group_by(性别) %>%
summarise(是否留过级 = sum(是否留过级))

看来,留级的学生人数在男女之间有很大的不同,更多的男学生留级。更多没有接受过学前教育的学生留级。这一观察结果表明,性别和学前教育可能对留级有预测作用。
构建二元逻辑回归模型
R默认安装了基础包,其中包括运行GLM的glm函数。glm的参数与lm的参数相似:公式和数据。然而,glm需要一个额外的参数:family,它指定了结果变量的假设分布;在family中我们还需要指定链接函数。family的默认值是gaussian(link = "identity"),这导致了一个线性模型,相当于由lm指定的模型。在二元逻辑回归的情况下,glm要求我们指定一个带有logit链接的二项分布,即family = binomial(link = "logit") 。
glm(formula ,
family = binomial(link = "logit"))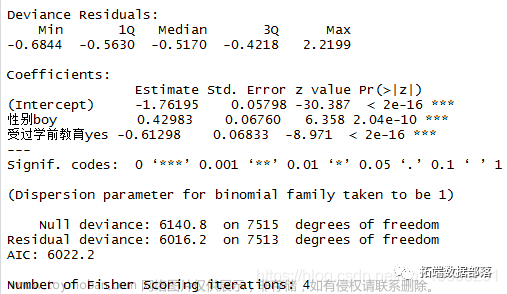
解释
从上面的总结输出中,我们可以看到,性别对学生留级的概率有正向和显著的预测,而学前教育则有负向和显著的预测。具体来说,与女孩相比,男孩更有可能留级。以前上过学的学生不太可能导致留级。
为了解释参数估计值,我们需要对估计值进行指数化处理。

请注意,参数估计的解释与几率而不是概率有关。赔率的定义是。P(事件发生)/P(事件未发生)。在本分析中,假设其他一切保持不变,与女孩相比,男孩增加了54%的留级几率;与没有学前教育相比,假设其他一切保持不变,拥有学前教育降低了(1-0.54)%=46%的留级几率。
参数效应的可视化
为了使参数效应的解释更加容易,我们可以对参数效应可视化。
plot(Effects) 文章来源地址https://www.toymoban.com/news/detail-599967.html
文章来源地址https://www.toymoban.com/news/detail-599967.html
请注意,在这两张图中,Y刻度指的是留级的概率,而不是几率。概率比几率更容易解释。每个变量的概率分数是通过假设模型中的其他变量是常数并采取其平均值来计算的。正如我们所看到的,假设一个学生有平均的学前教育,作为一个男孩比作为一个女孩有更高的留级概率(~0.16)~0.11)。同样,假设一个学生有一个平均的性别,有学前教育的学生比没有学前教育的学生留级的概率低(~0.11)(~0.18)。请注意,在这两幅图中,还包括了估计值的置信区间,以使我们对估计值的不确定性有一些了解。
请注意,平均学前教育和性别的概念可能听起来很奇怪,因为它们是分类变量(即因素)。如果你对假设一个平均因素的想法感到奇怪,你可以指定你的预期因素水平作为参考点。
predictors = list( values=c(性别boy=0, 受过学前教育yes = 0))文章来源:https://www.toymoban.com/news/detail-599967.html
设置性别boy = 0意味着在学前教育效应图中,性别变量的参考水平被设置为0;学前教育yes = 0导致0成为性别效应图中学前教育变量的参考水平。
因此,正如上面两幅图所示,假设学生没有接受过学前教育,作为男孩的留级概率(~0.20)比作为女孩的留级概率(~0.14)要高;假设学生是女性,有学前教育的留级概率(~0.09)比没有学前教育的留级概率(~0.15)要低。
点击标题查阅往期内容
多水平模型、分层线性模型HLM、混合效应模型研究教师的受欢迎程度
左右滑动查看更多
01
02
03
04
模型评估:拟合度
评价逻辑回归模型的拟合度有不同的方法。
似然比检验
如果一个逻辑回归模型与预测因子较少的模型相比,显示出拟合度的提高,则该模型对数据有较好的拟合度。这是用似然比检验进行的,它将完整模型下数据的似然性与较少预测因素的模型下数据的似然性进行比较。从一个模型中删除预测变量几乎总是会使模型的拟合度降低(即模型的对数似然率较低),但测试观察到的模型拟合度差异是否具有统计学意义是很有用的。
#指定一个只有`性别'变量的模型
#使用\`anova()\`函数来运行似然比测试
anova(ModelTest, Model, test ="Chisq")
我们可以看到,同时包含性别和学前教育的预测因子的模型比只包含性别变量的模型对数据的拟合效果要好得多。请注意,这种方法也可以用来确定是否有必要包括一个或一组变量。
AIC
Akaike信息准则(AIC)是另一个模型选择的衡量标准。与似然比检验不同,AIC的计算不仅要考虑模型的拟合度,还要考虑模型的简单性。通过这种方式,AIC处理了模型的拟合度和复杂性之间的权衡,因此,不鼓励过度拟合。较小的AIC是首选。
在AIC值较小的情况下,同时具有性别和学前教育预测因子的模型优于只具有性别预测因子的模型。
正确分类率
正确分类率是另一个有用的衡量标准,可以看出模型对数据的合适程度。
#使用\`predict()\`函数,从拟合的模型中计算出原始数据中学生的预测概率
Pred <- if_else(Pred > 0.5, 1, 0)
ConfusionMatrix <- table(Pred, TRUE)
#正确的分类率
我们可以看到,该模型对所有观测值的85.8%进行了正确分类。然而,仔细观察可以发现,模型预测所有的观察值都属于 "0 "类,也就是说,所有的学生都被预测为不留级。考虑到留级变量的多数类别是0(不),该模型在分类上的表现并不比简单地将所有观测值分配到多数类别0(不)更好。
AUC(曲线下面积)
使用正确分类率的一个替代方法是曲线下面积(AUC)测量。AUC测量区分度,即测试对有目标反应和无目标反应的人进行正确分类的能力。在目前的数据中,目标变量是留级。我们从 "留级 "组和 "不留级 "组中随机抽取一名学生。预测概率较高的学生应该是 "留级 "组中的学生。AUC是随机抽出的对子的百分比。这个程序将AUC与正确分类率区分开来,因为AUC不依赖于结果变量中类的比例的变化。0.50的值意味着该模型的分类效果不比随机好。一个好的模型应该有一个远远高于0.50的AUC分数(最好高于0.80)。
# 计算用该模型预测类别的AUC
AUC <- performance(Pred, measure = "auc")
AUC <- AUC@y.values\[\[1\]\]
AUC
AUC分数为0.60,该模型的判别能力不强。
二项式 Logistic 回归
正如开头提到的,逻辑回归也可以用来为计数或比例数据建模。二项逻辑回归假设结果变量来自伯努利分布(这是二项分布的一个特例),其中试验次数n为1,因此结果变量只能是1或0。相反,二项逻辑回归假设目标事件的数量遵循二项分布,试验次数n,概率q。这样一来,二项逻辑回归允许结果变量取任何非负整数值,因此能够处理计数数据。
教育数据记录了集中在学校内的个别学生的信息。通过汇总各学校留级的学生人数,我们得到一个新的数据集,其中每一行代表一所学校,并有关于该学校留级学生的比例信息。学校平均社会经济地位(平均SES分数)也是在学校层面上的;因此,它可以用来预测在某个学校留级的学生的比例或数量。
转换数据
在这个新的数据集中,留级指的是留级的学生人数;TOTAL指的是某所学校的学生总数。
探索数据
ggplot(aes(x , y)) +
geom_smooth(method = "lm")
我们可以看到,留级的学生比例与学校平均社会经济地位的反对数呈负相关。请注意,我们将变量学校平均社会经济地位建模为其反对数,因为在二项式回归模型中,我们假设线性预测因子的反对数与结果(即事件比例)之间存在线性关系,而不是预测因子本身与结果之间存在线性关系。
拟合二项式Logistic回归模型
为了拟合二项式逻辑回归模型,我们也使用glm函数。唯一的区别是在公式中对结果变量的说明。我们需要指定目标事件的数量(留级)和非事件的数量(TOTAL-留级),并将它们包在cbind()中。
glm(cbind(是否留过级, TOTAL-是否留过级) ~ 学校平均社会经济地位,
family = binomial(logit))
解释
二项式回归模型的参数解释与二项式逻辑回归模型相同。从上面的模型总结中我们知道,一所学校的平均SES分数与该校学生留级的几率呈负相关。为了提高可解释性,我们再次使用summ()函数来计算学校平均社会经济地位的指数化系数估计。由于学校平均社会经济地位是一个连续的变量,我们可以将指数化的学校平均社会经济地位估计值标准化(通过将原始估计值与变量的SD相乘,然后将所得数字指数化)。
#注意,为了对二项回归模型使用summ()函数,我们需要将结果变量作为对象。
是否留过级 <- (filter(edu, !is.na(学校平均社会经济地位)), 是否留过级)
我们可以看到,随着学校平均社会经济地位的SD增加,学生留级的几率降低了1 - 85% = 15%。
我们可以直观地看到学校平均社会经济地位的效果。
plot(allEffects)
上面的图表显示了学校平均社会经济地位对学生留级概率的预期影响。在其他因素不变的情况下,随着学校平均社会经济地位的增加,一个学生留级的概率会降低(从0.19到0.10)。蓝色阴影区域表示每个学校平均社会经济地位值的预测值的95%置信区间。
多层次二元逻辑回归
前面介绍的二元逻辑回归模型仅限于对学生层面的预测因素的影响进行建模;二元逻辑回归仅限于对学校层面的预测因素的影响进行建模。为了同时纳入学生层面和学校层面的预测因素,我们可以使用多层次模型,特别是多层次二元逻辑回归。
除了上述动机外,还有更多使用多层次模型的理由。例如,由于数据是在学校内分类的,来自同一学校的学生很可能比来自其他学校的学生更相似。正因为如此,在一所学校,一个学生留级的概率可能很高,而在另一所学校,则很低。此外,即使是结果(即留级)和预测变量(如性别、学前教育、学校平均社会经济地位)之间的关系,在不同的学校也可能不同。还要注意的是,学校平均社会经济地位变量中存在缺失值。使用多层次模型可以较好地解决这些问题。
请看下面的图作为例子。该图显示了各学校留级学生的比例。我们可以看到不同学校之间的巨大差异。因此,我们可能需要多层次模型。
group_by(学校) %>%
summarise(PROP = sum(是否留过级)/n()) %>%
plot()
我们还可以通过学校来绘制性别和留级之间的关系,以了解性别和留级之间的关系是否因学校而异。
mutate(性别 = if_else(性别 == "boy", 1, 0)) %>%
ggplot(aes(x = 性别, y = 是否留过级, color = as.factor(学校))) +
在上面的图中,不同的颜色代表不同的学校。我们可以看到,不同学校的性别和留级之间的关系似乎有很大不同。
我们可以为学前教育和留级做同样的图。
mutate(性别 = if_else(性别 == "girl", 0, 1),
受过学前教育 = if_else(受过学前教育 == "yes", 1, 0)) %>%
group_by(学校) %>%
mutate(性别 = 性别 - mean(性别),
学前教育和留级之间的关系在不同的学校也显得相当不同。然而,我们也可以看到,大多数的关系都呈下降趋势,从0(以前没有上过学)到1(以前上过学),表明学前教育和留级之间的关系为负。
由于上述观察结果,我们可以得出结论,在目前的数据中需要建立多层次的模型,不仅要有随机截距(学校),还可能要有性别和学前教育的随机斜率。
中心化变量
在拟合多层次模型之前,有必要采用适当的中心化方法(即均值中心化)对预测变量进行中心化,因为中心化方法对模型估计的解释很重要。根据Enders和Tofighi(2007)的建议,我们应该对第一层次的预测因子性别和学前教育使用中心化,对第二层次的预测因子学校平均社会经济地位使用均值中心化。
受过学前教育 = if_else(受过学前教育 == "yes", 1, 0)) %>%
group_by(学校) %>%
mutate(性别 = 性别 - mean(性别),
受过学前教育 = 受过学前教育 - mean(受过学前教育)) %>%
ungroup() %>%
只有截距模型
为了指定一个多层次模型,我们使用lme4软件包。随机斜率项和聚类项应该用|分隔。注意,我们使用了一个额外的参数指定比默认值(10000)更大的最大迭代次数。因为一个多层次模型可能需要大量的迭代来收敛。
我们首先指定一个纯截距模型,以评估数据聚类结构的影响。
glmer(是否留过级 ~ 1 + (1|学校),
optCtrl = list(maxfun=2e5))
下面我们计算一下纯截距模型的ICC(类内相关)。
0.33的ICC意味着结果变量的33%的变化可以被数据的聚类结构所解释。这提供了证据表明,与非多层次模型相比,多层次模型可能会对模型的估计产生影响。因此,多层次模型的使用是必要的,也是有保证的。
完整模型
按部就班地建立一个多层次模型是很好的做法。然而,由于本文的重点不是多层次模型,我们直接从纯截距模型到我们最终感兴趣的全模型。在完整模型中,我们不仅包括性别、学前教育和学校平均社会经济地位的固定效应项和一个随机截距项,还包括性别和学前教育的随机斜率项。请注意,我们指定 family = binomial(link = "logit"),因为这个模型本质上是一个二元逻辑回归模型。
glmer(是否留过级 ~ 性别 + 受过学前教育 + 学校平均社会经济地位 + (1 + 性别 + 受过学前教育|学校)
结果(与固定效应有关)与之前二元逻辑回归和二项逻辑回归模型的结果相似。在学生层面上,性别对学生留级的几率有显著的正向影响,而学前教育有显著的负向影响。在学校层面上,学校地位对结果变量有显著的负向影响。我们也来看看随机效应项的方差。
同样,我们可以使用summ()函数来检索指数化的系数估计值,便于解释。
sum(Model_Full)
我们还可以显示参数估计的效果。请注意,由于第一级分类变量(性别和学前教育)是中心化的,因此在模型中它们被当作连续变量,在下面的效果图中也是如此。
plot((Model)
除了固定效应项之外,我们也来看看随机效应项。从之前的ICC值来看,我们知道有必要包括一个随机截距。但是,包括性别和学前教育的随机斜率的必要性就不太清楚了。为了弄清楚这一点,我们可以用似然比检验和AIC来判断随机斜率的加入是否能改善模型的拟合。
glmer(是否留过级 ~ 性别 + 受过学前教育 + 学校平均社会经济地位 + (1 + 受过学前教育|学校),#拟合一个不完整的模型,剔除`受过学前教育'的随机斜率项
glmer(是否留过级 ~ 性别 + 受过学前教育 + 学校平均社会经济地位 + (1 + 性别|学校),似然比检验
比较完整的模型和排除了`性别'的模型
将完整的模型与排除了 "受过学前教育 "的模型进行比较
从所有不显著的似然比检验结果(Pr(>Chisq)>0.05),我们可以得出结论,增加任何随机斜率项对模型拟合都没有明显的改善。
AIC
AIC #full模型
AIC##没有性别的模型
AIC ##没有受过学前教育的模型
AIC##没有随机斜率的模型
从AIC的结果来看,我们发现包括随机斜率项要么没有大幅提高AIC(用较低的AIC值表示),要么导致更差的AIC(即更高)。因此,我们也得出结论,没有必要包括随机效应项。
其他族(分布)和链接函数
到目前为止,我们已经介绍了二元和二项逻辑回归,这两种回归都来自于二项家族的logit链接。然而,还有许多分布族和链接函数,我们可以在glm分析中使用。例如,为了对二元结果进行建模,我们还可以使用probit链接或log-log(cloglog)来代替logit链接。为了给计数数据建模,我们也可以使用泊松回归,它假设结果变量来自泊松分布,并使用对数作为链接函数。
参考文献
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). _Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software, 67_(1), 1-48. doi:10.18637/jss.v067.i01
Enders, C. K., & Tofighi, D. (2007). Centering predictor variables in cross-sectional multilevel models: A new look at an old issue. _Psychological Methods, 12_(2), 121-138. doi:10.1037/1082-989X.12.2.121
本文中分析的数据分享到会员群,扫描下面二维码即可加群!
点击文末“阅读原文”
获取全文完整资料。
本文选自《R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据》。
点击标题查阅往期内容
R语言线性混合效应模型(固定效应&随机效应)和交互可视化3案例
非线性混合效应 NLME模型对抗哮喘药物茶碱动力学研究
生态学模拟对广义线性混合模型GLMM进行功率(功效、效能、效力)分析power analysis环境监测数据
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
如何用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言 线性混合效应模型实战案例
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言如何用潜类别混合效应模型(LCMM)分析抑郁症状
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言建立和可视化混合效应模型mixed effect model
R语言LME4混合效应模型研究教师的受欢迎程度
R语言 线性混合效应模型实战案例
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
基于R语言的lmer混合线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言分层线性模型案例
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
用SPSS估计HLM多层(层次)线性模型模型
到了这里,关于数据分享|R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据...的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!