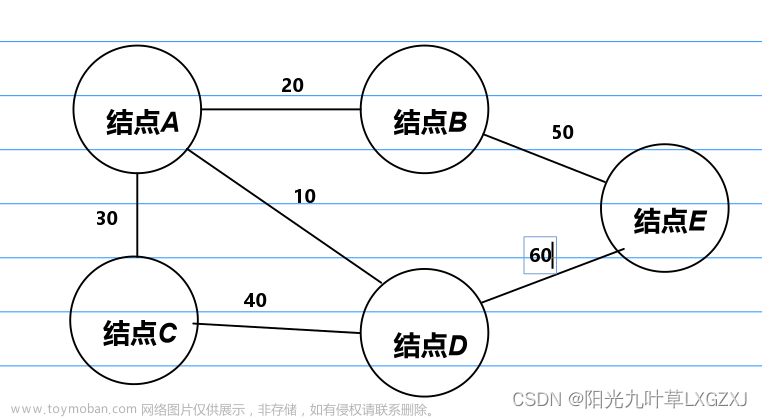
二分图,即可以将图中的所有顶点分层两个点集,每个点集内部没有边
判定图为二分图的充要条件:有向连通图不含奇数环
1、染色法
可以解决二分图判断的问题
步骤与基本思路
遍历图中每一个点,若该点未被染色,则遍历该点所相邻的点,相邻的点中未被染色的进行染色操作,已被染色的判断颜色是否合法,合法继续遍历,不合法退出
染色法板子
bool flag = true;
for (int i = 1; i <= n; i ++ )
{
if (!color[i]) // 未被染色则开始遍历
{
if (!dfs(i, 1))
{
flag = false;
break;
}
}
}
bool dfs(int u, int c)
{
color[u] = c; // 对该点进行染色
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (!color[j]) // 未被染色的点进行染色
{
if (!dfs(j, 3 - c)) return false;
}
else if (color[j] == c) return false; // 已染色的点判断是否合法
}
return true;
}2、匈牙利算法
可以解决最大匹配数的问题,也就是二分图的两个点集可以连多少条一一对应的边
步骤与基本思路
(1)遍历第一个点集的所有点,每个点遍历之前要记得把第二个点集的状态清空文章来源:https://www.toymoban.com/news/detail-600018.html
(2)依次遍历这些点相邻的点,若该点未被遍历过,则判断该点是否满足未与前面的点匹配过或前面与它匹配的点有其他的匹配方案,若满足任意条件则让现在的两点匹配,不满足则说明当前第一个点集的这个点没有匹配对象文章来源地址https://www.toymoban.com/news/detail-600018.html
匈牙利算法板子
for (int i = 1; i <= n1; i ++ )
{
memset(st, false, sizeof st); // 清空第二个点集的状态
if (find(i)) res ++ ;
}
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j]) // 若该点未被遍历过
{
st[j] = true;
// 该点是否满足 未被匹配过 or 匹配的第一个点集的点有其他成功匹配方案
if (match[j] == 0 || find(match[j]))
{
match[j] = x; // 匹配现在的这两点
return true;
}
}
}
return false;
}到了这里,关于【图论】二分图的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!