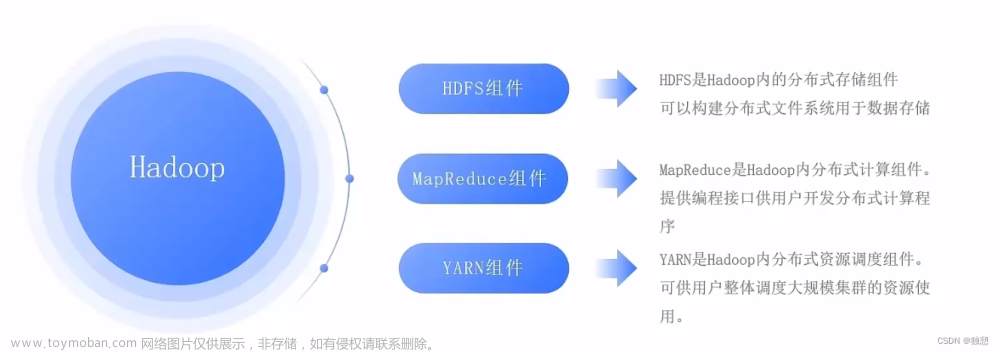
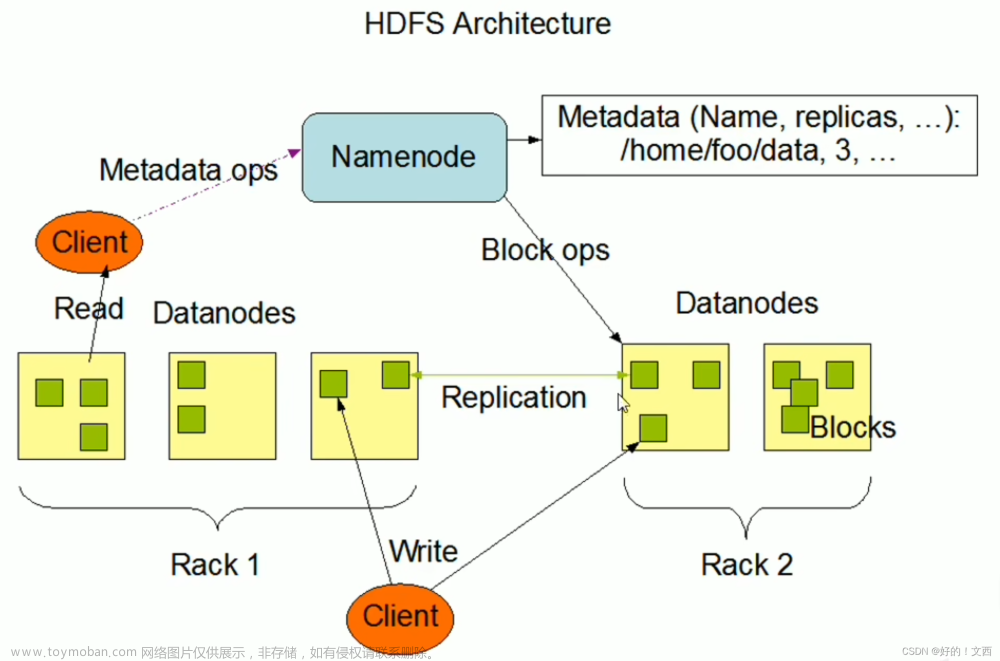
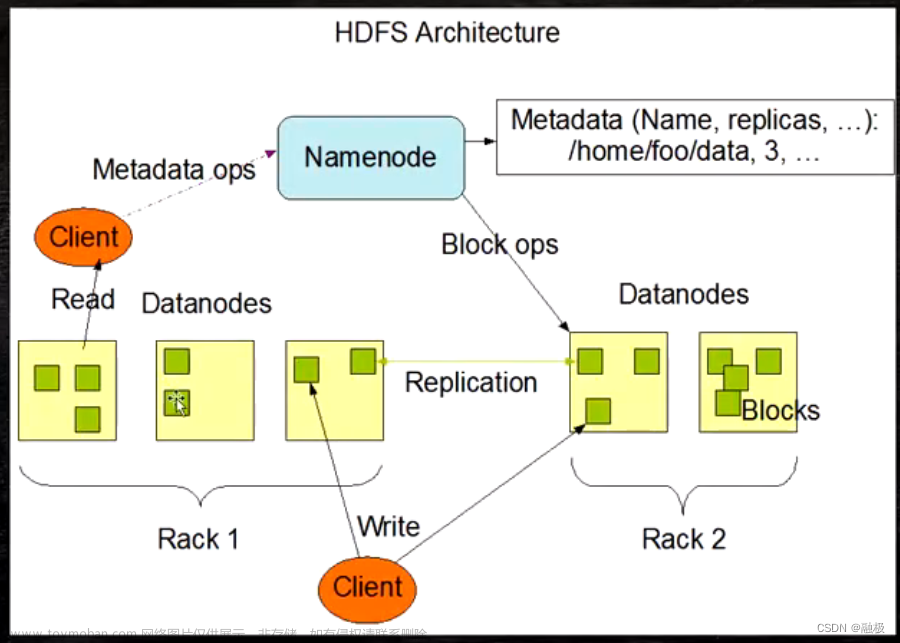
Apache Hadoop是一个分布式计算系统,它主要由以下几个组件组成:
-
Hadoop Distributed File System(HDFS):这是Hadoop的分布式文件系统,负责存储大量的数据,并且能够以容错的方式进行读写。
-
MapReduce:这是Hadoop的核心组件,它负责处理大规模的数据集,并将它们分成若干个小任务,分布式地在集群中的节点上进行处理。
-
YARN(Yet Another Resource Negotiator):这是Hadoop的资源管理组件,负责为MapReduce任务分配资源,并监控任务的执行情况。
-
Hadoop Common:这是Hadoop的基础组件,包含了Hadoop系统中所有其他组件所依赖的公共库和工具。
-
Hadoop Ozone:这是Hadoop的对象存储系统,主要用于存储大量的小文件。文章来源:https://www.toymoban.com/news/detail-600160.html
-
Hadoop EcoSystem:Hadoop生态系统包括许多其他的开源项目,如Apache Hive、Apache Pig、Apache Spark等,这些项目建立在Hadoop之上,为数据处理提供了更为丰富的功能。文章来源地址https://www.toymoban.com/news/detail-600160.html
到了这里,关于hadoop的组件有哪些的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!