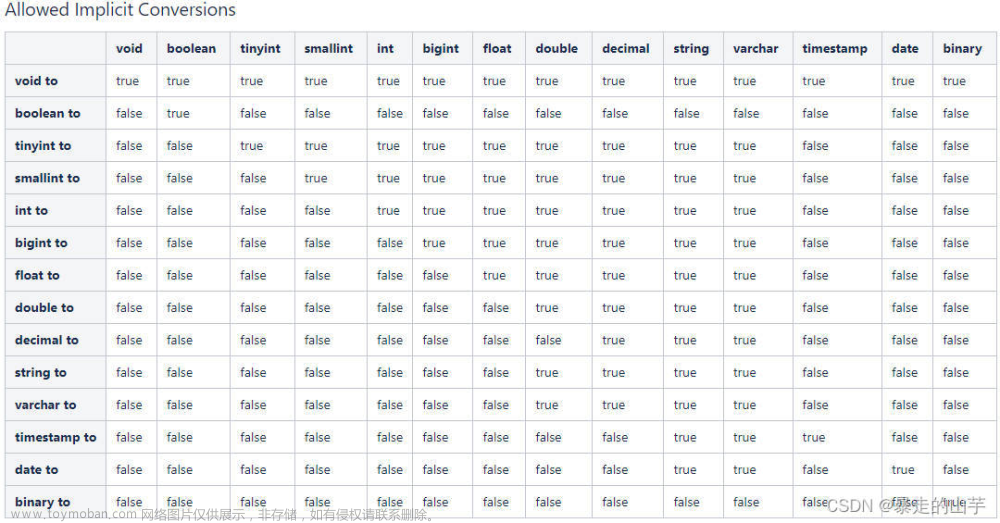
count(1)和count()比较
单独看三种返回数据的查询结果来看,count() 和 count(1) 几乎可以说是没有区别的。count(*) 和 count(1) 都会把值为 null 的行都进行统计。
第一种count()
第二种count(1)
可以很清楚的看到,虽然查询的结果是一样的,但是查询时间效率上count()用时2.674秒,而count(1)用时才0.29秒,足足差了10倍,因此在生产环境中强烈建议不要使用count(*)直接使用count(1)
第三种count(字段名)
count(字段名) 则剔除值为 null 的行后再统计计数,包括 count(distinct 字段名) 也是会剔除值为 null 的行后再去重计数 可以看到count(字段名)是最耗时的,查询时间打到38秒,是因为count(1)和count(*)没有被转化成MR任务,如果是数据量比较大的情况下或者同等查询条件下,count(字段名)并不会比其他两种慢文章来源:https://www.toymoban.com/news/detail-600203.html
可以看到count(字段名)是最耗时的,查询时间打到38秒,是因为count(1)和count(*)没有被转化成MR任务,如果是数据量比较大的情况下或者同等查询条件下,count(字段名)并不会比其他两种慢文章来源:https://www.toymoban.com/news/detail-600203.html
总结就是优先使用count(1)和count(字段名)文章来源地址https://www.toymoban.com/news/detail-600203.html
到了这里,关于HIve中count(1),count(*),count(字段名)三种统计的区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!