目录
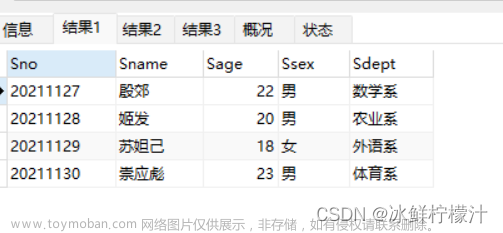
模版表
一、ORDER BY语法
1.1语法
1.2升序
1.3降序
1.4多高字段排序
二、AND/OR--且/或
2.1AND
2.2OR
2.3嵌套/多条件
三、distinct 查询不重复记录
3.1语法
四、GROUP BY语法
4.1语法
五、限制结果条目(limit)
5.1语法
5.2实验
五、设置别名(alias----as)
5.1语法
5.2实验
5.4查询info表的字段数量,以number显示
5.5 AS 还可以作为连接语句的操作符。 创建t1表,将info表的查询记录全部插入info_bak表
六、通配符
6.1 %
6.2 _
七、接下来的内容请看MySQL高阶语句之二
MySQL高阶语句之二
模版表
create table info (id int,name varchar(10) primary key not null ,score decimal(5,2),address varchar(20),hobbid int(5));
insert into ky29 values(1,'liuyi',80,'beijing',2);
insert into ky29 values(2,'wangwu',90,'shengzheng',2);
insert into ky29 values(3,'lisi',60,'shanghai',4);
insert into ky29 values(4,'tianqi',99,'hangzhou',5);
insert into ky29 values(5,'jiaoshou',98,'laowo',3);
insert into ky29 values(6,'hanmeimei',10,'nanjing',3);
insert into ky29 values(7,'lilei',11,'nanjing',5);
select * from info;
一、ORDER BY语法
使用 SELECT 语句可以将需要的数据从 MySQL 数据库中查询出来,如果对查询的结果进行排序,可以使用 ORDER BY 语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
1.1语法
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC;ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略。SELECT 语句中如果没有指定具体的排序方式,则默认按 ASC方式进行排序。
DESC 是按降序方式进 行排列。当然 ORDER BY 前面也可以使用 WHERE 子句对查询结果进一步过滤。
1.2升序
#以score参照,做升序
#不写默认是升序
select id,name,score from info3 order by score;
1.3降序
#以score为对象,做降序
select id,name,score from info3 order by score desc;
1.4多高字段排序
ORDER BY 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定 但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
mysql> select id,name,score,hobbid from info3 order by hobbid desc,id desc;
+------+-----------+-------+--------+
| id | name | score | hobbid |
+------+-----------+-------+--------+
| 7 | jixiaoman | 63.00 | 5 |
| 4 | tangsan | 50.00 | 5 |
| 3 | lisi | 60.00 | 4 |
| 6 | lilei | 18.00 | 3 |
| 5 | hanmei | 10.00 | 3 |
| 2 | wangwu | 90.00 | 2 |
| 1 | luiyi | 80.00 | 2 |
+------+-----------+-------+--------+
7 rows in set (0.00 sec)
二、AND/OR--且/或
2.1AND
mysql> select * from info3 where score > 70 and score <= 90;
+------+--------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+--------+-------+------------+--------+
| 1 | luiyi | 80.00 | beijing | 2 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+--------+-------+------------+--------+
2 rows in set (0.00 sec)
2.2OR
mysql> select * from info3 where score > 70 or score <= 90;
+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 5 | hanmei | 10.00 | nanjing | 3 |
| 7 | jixiaoman | 63.00 | guizhou | 5 |
| 6 | lilei | 18.00 | kunshan | 3 |
| 3 | lisi | 60.00 | shandong | 4 |
| 1 | luiyi | 80.00 | beijing | 2 |
| 4 | tangsan | 50.00 | laowo | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
7 rows in set (0.00 sec)
2.3嵌套/多条件
#嵌套方式,先执行嵌套里面的,在执行外面的。
mysql> select * from info3 where score > 70 or (score >60 and score <90);
+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 7 | jixiaoman | 63.00 | guizhou | 5 |
| 1 | luiyi | 80.00 | beijing | 2 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
3 rows in set (0.00 sec)
三、distinct 查询不重复记录
3.1语法
select distinct 字段 from 表名﹔mysql> select distinct hobbid from info3;
+--------+
| hobbid |
+--------+
| 3 |
| 5 |
| 4 |
| 2 |
+--------+
4 rows in set (0.00 sec)
四、GROUP BY语法
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
4.1语法
SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator value GROUP BY column_name;按hobbid相同的分组,计算相同分数的学生个数(基于name个数进行计数)
mysql> select count(name),hobbid from info3 group by hobbid;
+-------------+--------+
| count(name) | hobbid |
+-------------+--------+
| 2 | 2 |
| 2 | 3 |
| 1 | 4 |
| 2 | 5 |
+-------------+--------+
4 rows in set (0.00 sec)
结合where语句,筛选分数大于等于70的分组,计算学生个数
mysql> select count(name),hobbid from info3 where score >=70 gr
oup by hobbid;
+-------------+--------+
| count(name) | hobbid |
+-------------+--------+
| 2 | 2 |
+-------------+--------+
1 row in set (0.00 sec)
结合order by把计算出的学生个数按升序排列
mysql> select count(name),score,hobbid from info3 where score>=10 group by hobbid order by count(name) asc;
+-------------+-------+--------+
| count(name) | score | hobbid |
+-------------+-------+--------+
| 1 | 60.00 | 4 |
| 2 | 10.00 | 3 |
| 2 | 63.00 | 5 |
| 2 | 80.00 | 2 |
+-------------+-------+--------+
4 rows in set (0.00 sec)
五、限制结果条目(limit)
limit 限制输出的结果记录
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
LIMIT 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。 如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的 位置偏移量是 0,第二条是 1,以此类推。第二个参数是设置返回记录行的最大数目。
5.1语法
SELECT column1, column2, ... FROM table_name LIMIT [offset,] number5.2实验
查询所有信息显示前4行记录
mysql> select * from info3 limit 4;
+------+-----------+-------+----------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+----------+--------+
| 5 | hanmei | 10.00 | nanjing | 3 |
| 7 | jixiaoman | 63.00 | guizhou | 5 |
| 6 | lilei | 18.00 | kunshan | 3 |
| 3 | lisi | 60.00 | shandong | 4 |
+------+-----------+-------+----------+--------+
4 rows in set (0.00 sec)
从第5行开始,往后显示3行内容
mysql> select * from info3 limit 4,3;
+------+---------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+---------+-------+------------+--------+
| 1 | luiyi | 80.00 | beijing | 2 |
| 4 | tangsan | 50.00 | laowo | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+---------+-------+------------+--------+
3 rows in set (0.00 sec)
结合order by语句,按id的大小升序排列显示前三行
mysql> select * from info3 order by id limit 3;
+------+--------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+--------+-------+------------+--------+
| 1 | luiyi | 80.00 | beijing | 2 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
| 3 | lisi | 60.00 | shandong | 4 |
+------+--------+-------+------------+--------+
3 rows in set (0.00 sec)
五、设置别名(alias----as)
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者 多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性
5.1语法
#对于列的别名:
SELECT column_name AS alias_name FROM table_name;
#对于表的别名:
SELECT column_name(s) FROM table_name AS alias_name;在使用 AS 后,可以用 alias_name 代替 table_name,其中 AS 语句是可选的。AS 之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名 或字段名是不会被改变的
5.2实验
mysql> select id as 序号,name as 姓名,score as 成绩 from info3 order by id;
+--------+-----------+--------+
| 序号 | 姓名 | 成绩 |
+--------+-----------+--------+
| 1 | luiyi | 80.00 |
| 2 | wangwu | 90.00 |
| 3 | lisi | 60.00 |
| 4 | tangsan | 50.00 |
| 5 | hanmei | 10.00 |
| 6 | lilei | 18.00 |
| 7 | jixiaoman | 63.00 |
+--------+-----------+--------+
7 rows in set (0.00 sec)
5.4查询info表的字段数量,以number显示
mysql> select count(*) 姓名 from info3;
+--------+
| 姓名 |
+--------+
| 7 |
+--------+
1 row in set (0.00 sec)
mysql> select count(*) number from info3;
+--------+
| number |
+--------+
| 7 |
+--------+
1 row in set (0.00 sec)
mysql> select count(*) 数量 from info3;
+--------+
| 数量 |
+--------+
| 7 |
+--------+
1 row in set (0.00 sec)
mysql> select count(*) as 数量 from info3;
+--------+
| 数量 |
+--------+
| 7 |
+--------+
1 row in set (0.00 sec)
5.5 AS 还可以作为连接语句的操作符。 创建t1表,将info表的查询记录全部插入info_bak表
此处AS起到的作用:
1、创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
2、但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,那么附表的:default字段会默认设置一个0 相似。
mysql> create table info_bak (select * from info3);
Query OK, 7 rows affected (0.01 sec)
Records: 7 Duplicates: 0 Warnings: 0
mysql> show tables;
+----------------+
| Tables_in_text |
+----------------+
| info1 |
| info2 |
| info3 |
| info_bak |
+----------------+
4 rows in set (0.00 sec)
mysql> desc info_bak;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(10) | NO | | NULL | |
| score | decimal(5,2) | YES | | NULL | |
| address | varchar(20) | YES | | NULL | |
| hobbid | int(5) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
5 rows in set (0.00 sec)
mysql> select * from info_bak;
+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 5 | hanmei | 10.00 | nanjing | 3 |
| 7 | jixiaoman | 63.00 | guizhou | 5 |
| 6 | lilei | 18.00 | kunshan | 3 |
| 3 | lisi | 60.00 | shandong | 4 |
| 1 | luiyi | 80.00 | beijing | 2 |
| 4 | tangsan | 50.00 | laowo | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
7 rows in set (0.00 sec)
六、通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通常通配符都是跟 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
%:表示零个、一个或多个字符文章来源:https://www.toymoban.com/news/detail-600455.html
_:下划线表示单个字符文章来源地址https://www.toymoban.com/news/detail-600455.html
6.1 %
mysql> select id,name from info3 where name like 'li%'
-> ;
+------+-------+
| id | name |
+------+-------+
| 6 | lilei |
| 3 | lisi |
+------+-------+
2 rows in set (0.00 sec)
6.2 _
mysql> select id,name from info3 where name like 'wang__';
+------+--------+
| id | name |
+------+--------+
| 2 | wangwu |
+------+--------+
1 row in set (0.00 sec)
七、接下来的内容请看MySQL高阶语句之二
MySQL高阶语句之二
到了这里,关于MySQL高阶语句之一的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!