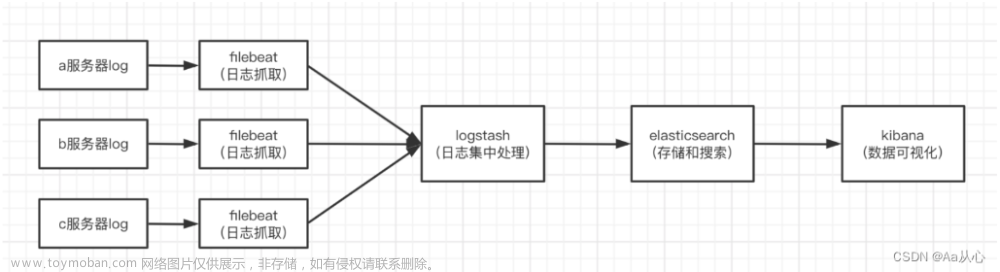
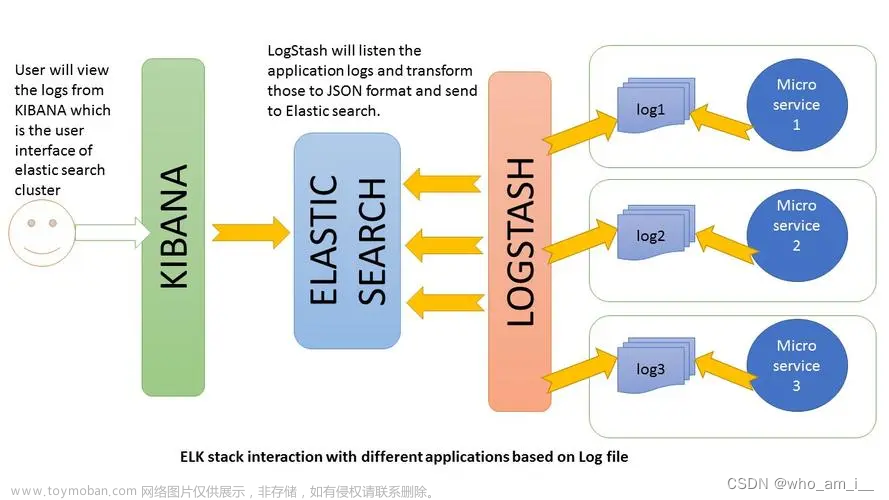
什么是ELK
-
Elasticsearch:Elasticsearch(以下简称ES) 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 ES是 Elastic Stack 的核心,采用集中式数据存储,可以通过机器学习来发现潜在问题。ES能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标)。支持 PB级数据的秒级检索。
-
Kibana:Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成
-
Logstash:Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到合适的的“存储库”中。
-
Beats:Beats 是一套免费且开源的轻量级数据采集器,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
为什么要使用ELK
-
严格按照开发标准来说,开发人员是不能登录生产服务器查看日志数据的
-
一个应用可能分布于多态服务器,难以查找
-
同一台服务区可能部署多个应用,日志分散难以管理
-
日志可能很大,单个文件通常能达到GB级别,日志无法准确定位,日志查询不方便且速度慢
-
通常日志文件以非结构化存储,不支持数据可视化查询。
-
不支持日志分析(比如慢查询日志分析、分析用户画像等)。
使用场景
-
采集业务日志
-
采集Nginx日志
-
采集数据库日志,如MySQL
-
监控集群性能指标
-
监听网络端口
-
心跳检测
Logstash
开源的流数据处理、转换(解析)和发送引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源
工作原理
Logstash的每个处理过程均以插件的形式实现,Logstash的数据处理过程主要包括: Inputs , Filters , Outputs 三部分

数据采集:Inputs
数据过滤:Filter
数据存储:output
Beats
Beats 是一套免费且开源的轻量级数据采集器,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
beats替换了logstash一部分功能(input 采集功能)。因为logstash比较重量级,占用较多资源;而Beats相对轻量级。
Beats的基本特性
开源:Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器,各司其职,功能分离。社区中维护了上百个beat
轻量级:体积小,职责单一、基于go语言开发,具有先天性能优势,不依赖于Java环境,对服务器资源占用极小。Beats 可以采集符合 Elastic Common Schema (ECS) 要求的数据,可以将数据转发至 Logstash 进行转换和解析。
可插拔:Filebeat 和 Metricbeat 中包含的一些模块能够简化从关键数据源(例如云平台、容器和系统,以及网络技术)采集、解析和可视化信息的过程。只需运行一行命令,即可开始探索。
高性能:对CPU、内存和IO的资源占用极小。
可扩展:由于Beats开源的特性,如果现有Beats不能满足开发需要,我们可以自行构建,并且完善Beats社区
组件
-
Filebeat:文件日志监控采集 ,主要用于收集日志数据
-
Metricbeat:进行指标采集,指标可以是系统的,也可以是众多中间件产品的,主要用于监控系统和软件的性能
-
Packetbeat: 是一个实时网络数据包分析器,通过网络抓包、协议分析,基于协议和端口对一些系统通信进行监控和数据收集。可以将其与Elasticsearch一起使用,以提供应用程序监视和性能分析系统。
-
Heartbeat:心跳检测 (在配置的Url中喊一句:喂,有活着的么?有的话吱个声!)
-
Winlogbeat:Windows事件日志
-
Auditbeat:审计数据(收集审计日志)
-
Functionbeat:云服务生成的日志和指标收集器
Kibana
Kibana 是一个免费且开放的可视化系统,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
之前用的比较多的就是kibana的dev tools的功能,用于写dsl
kibana中的discover支持可视化的查看数据

基于ELK搭建日志采集系统
流程

安装logstash
下载:
Past Releases of Elastic Stack Software | Elastic
直接解压
启动:切换到bin目录 ./logstash
./logstash -e 'input{stdin{}}' output{stdout{}}'
-e:加启动选择
stdin:标准化输入
stdout:标准化输出

在config/logstash-sample.conf中配置

启动时,加 -f指定配置文件
./bin/logstash config/logstash-sample.conf
结果

stdin、stdout:方便排查日志采集问题
FileBeat
安装地址:
Filebeat 7.13.0 | Elastic
原理

为什么要使用fileBeat
因为logstash有日志采集的功能,但是logstash比较重量级,如果放在业务服务器上,比较占用资源。所以,使用fileBeat在业务服务器上进行日志采集,然后把采集到的日志输出到logstash(单独的服务器)上,这样采集日志就不会占用业务服务器空间
filebeat配置
inputs配置

启动fileBeat

-e:对启动日志进行输出
-c:指定配置文件
将fileBeat的输出改为logstash(filebeat.yml)

logstash的默认端口号:5044
修改logstash的输入为beats(logstash-sample.conf)

修改logstash的输出为es(logstash-sample.conf)

output中可以加多个(stdout、elasticsearch等)
可以通过配置,将一部分日志归为一条日志(比如说一些错误日志)

multiline.type: pattern # 匹配格式是正则
multiline.pattern: '^\[' # 匹配的正则表达式
multiline.negate: true # 匹配上正则表示是一条数据(false表示匹配不上为新的一条数据)
multiline.match: after # 匹配不上的追加在上一条后面logstash添加filter过滤器
logstash最常用的filter是grok

kibana中可以写grok

将logstash中的filter配置成写的grok正则

启动filebeat前,先把data数据删除(避免之前的日志已经采集过了,没有产生新的日志 )
rm -rf data/区分input
一个beats可以有多个input,但是只能输出到同一个es的索引中,不方便做数据区分
可以给不同的input加标签区分

在logstash中进行判断,然后区分index

可以根据grok判断
想根据日志级别区分不同的日志,生成不同的index,可以根据grok中的LOGLEVEL判断
如果要自定义正则表达式的话,可以在logstash的patterns文件中写


也可以通过字符串判断

基于FileBeat采集nginx日志
安装nginx

查找nginx安装路径

修改nginx配置文件中日志采集格式为json

nginx.conf

改动后需要重启nginx
修改filebeat支持json输入


基于filebeat采集系统日志syslog

format是一种日志规范
采集系统日志

udp、tcp的默认端口是514

修改配置文件

重启系统服务

查看系统服务状态

在logstash中区分tcp、udp索引

使用logger测试tcp

使用netcat测试udp

后面的udp.yml是自己创建的文件

数据可视化操作
kibana的dashboard

管理index patterns

创建index pattern
方便更好的看一类es索引数据

创建dashboard文章来源:https://www.toymoban.com/news/detail-600592.html
 文章来源地址https://www.toymoban.com/news/detail-600592.html
文章来源地址https://www.toymoban.com/news/detail-600592.html
到了这里,关于ELK(elasticsearch+logstash+kibana+beats)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!