上篇文章说了G1不在是连续的老年代年轻代,而是分为不同的region,有eden,survivor,old,humongous,当大于百分之50region的数据则直接进入humongous,如果对象太大,会连续的存储,分为初始标记,并发标记,最终标记,筛选标记,其中只有并发标记不会STW,G1可以设置STW的时候,从而利用成本算法排序回收一部分垃圾。
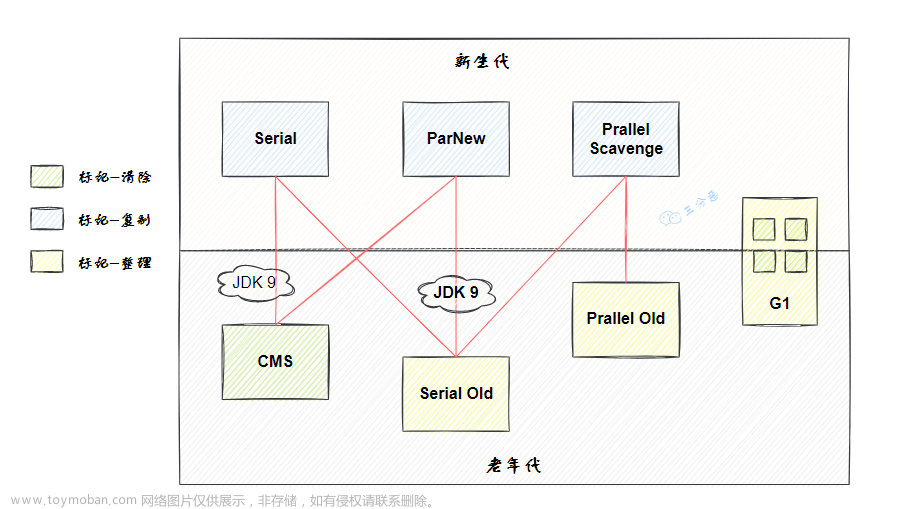
G1垃圾收集器-JVM(十三)
- G1垃圾收集器特性
G1在后台会维护一个优先列表,每次在允许收集的时间内,选择最大价值的region回收(garbage-first的由来),比如一个region花200ms回收10M垃圾,另一个花20ms回收20M的垃圾,肯定会优先选择后者,保证在优先时间内高效回收。
- 并发并行:G1充分利用多核CPU电脑性能缩短STW的时间,其他收集器需要STW,而G1可以通过并发来一起执行。
- 分代收集:已经抛弃物理分代收集概念,但仍然有region区域。
- 空间整理:碎片更少,底层采用的是复制算法。Cms采用的是标记清除。
- 可预测停顿:这是相对于其他垃圾收集器最大优势,可以自己设置stw时间。
(-XX:MaxGCPauseMills)
当然这个值设置太小也不好,如果设置20ms,很可能stw停顿时间太短,导致每次GC回收的垃圾有限,最终垃圾收集器的速率跟不上分配器速度,导致垃圾慢慢堆积,最后发生fullGC,时间一长反而性能更低,正常默认是200ms,设置200ms到300ms都比较合理。
- G1垃圾收集器分类
分为YoungGC、MixedGC、FullGC。
YoungGC:Minor GC并不是eden满了就触发,而是会看-XX:MaxGCPauseMills设定的值,如果远远小于这个值会就继续增加eden,直到计算接近这个值,才会触发minorGC。
MixedGC:不是fullGC,老年代占有率达到-XX:InitiatingHeapOccupancyPercent设置的值触发,这时候会用复制算法,回收所有youngGC和部分old区域以及大对象区域的region,主要部分是根据设定的STW时间值来计算成本,从region区域拷贝到另一个region,在拷贝过程中,如果发现区域不够用,则会触发fullGC。
(比如当老年代这个参数设置百分之50,但是其他区域都被年轻代占用了,那老年代有那么多区域要复制,没有足够多的空region来复制,这时候就会触发fullGC)
FullGC:停止系统其他线程,单线程进行标记、清理和整理。这个过程非常耗时,整理出来region给下次MixedGC使用。(Shenandoah优化成多线程)
- G1参数
开启G1参数:-XX:+UseG1GC
指定线程数:-XX:ParallelGCThreads
指定分区大小:-XX:G1HeapRegionSize,必须是2的N次幂,保证能分成2048个region,每个region最大32M。
目标暂停时间:-XX:MaxGCPauseMills
新生代初始空间:-XX:G1NewSizePercent,默认百分之5
新生代最大空间:-XX:G1MaxNewSizePercent,默认百分之60
-XX:TargetSurvivorRatio:survivor默认是百分之50,当survivor区域里的一批对象(年代1+年代2....+年代n)总和超过survivor的百分之50,此时会把年龄代1以上的对象都放入old。
-XX:MaxTenuringThreshold:最大年龄阀值(默认15)
-XX:InitiatingHeapOccupanyPercent:老年代占用空间整个堆阈值(默认45),则会发生MixedGC,比如2048个region,当有接近1000个region时候,则会发生MixedGC。
-XX:G1MixedGCLiveThresholdPercent(默认百分之85):判断region里存活的对象低于这个值才回收region,如果超过这个值,代表存活的对象太多,则回收意义不大,优先考虑回收其他region。
-XX:G1MixedGCCountTarget:在一次回收过程中指定做几次筛选回收(默认8次),在筛选回收阶段会分次回收,回收一会暂停回收,后面又继续开始,这样不至于让停顿时间太长。防止垃圾太多的情况,需要回收时间太长,所以垃圾太多的情况需要设置大一点,分段慢慢回收。
(正常设置1次就好)
-XX:G1HeapWastePercent(默认百分5):gc过程中空出来的region是否充足的阈值,在混合回收的时候,用复制算法,所以需要有空闲的region提供复制,一旦空闲的region到达了百分之5,立刻停止混合回收,代表这次混合回收结束。
所以-XX:MaxGCPauseMills这个参数不适合设置太小,不然每次STW时间太短导致清理不干净,触发fullGC。文章来源:https://www.toymoban.com/news/detail-600711.html
- 大内存的情况下适合G1
- 对象分配和晋升速度变化很大。
- 垃圾回收时间特别长,超过1s
- 8g以上堆内存可以用。
- 停顿时间500ms以上。
Kafka每个节点可以承受几十万的消息,假设按之前的算法算,每个消息1kb,那么3万消息就是30 000kb,涉及到库存等消息,30 000*200=6 000 000kb。600M每次进入eden,eden一共也才2个g不到,3s就会放满,则会频繁fullGC,这时候则需要增大机器内存,之前我们假设的内存是4核8G。所以为了满足kafka高吞吐的特性,机器内存要足够大,如果40个G的eden,这时候至少需要接近20s才可以放满。文章来源地址https://www.toymoban.com/news/detail-600711.html
到了这里,关于G1垃圾收集分类-JVM(十四)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!