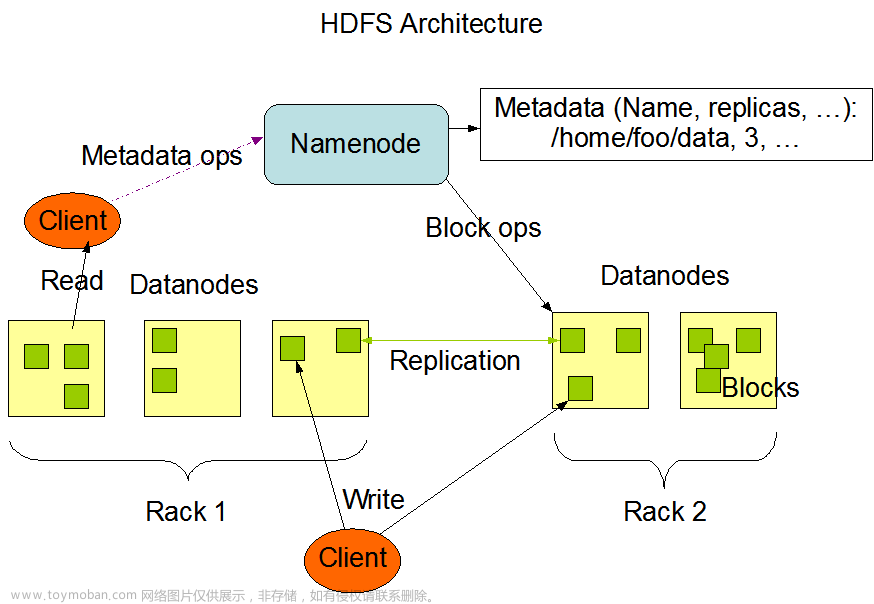
hdfs的写入流程

1.client发起文件上传请求,通过rpc与namenode建立通讯,namenode检查目标文件是否已经存在,父目录是否存在,返回是否可以上传
2.client请求第一个block该传输到哪些datanode服务器上
3.namenode根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用DataNode地址,如:a,b,c
4.client请求3台DataNode中的一台A上传数据(本质是一个rpc调用,建立pipeline),A收到请求会继续调动B,然后B调用C,将整个pipeline建立完成,后主机返回client
5.client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet会放入一个应答队列等待应答
6.数据被分割成一个个packet数据包在pipeline上一次传输,在pipeline反方向上,逐个发送ack(ack应答机制),最终由皮盆里呢中第一个DataNode节点A将pipeline ack发送给client;
7.当一个block传输完成之后,client在此请求namenode上传到第二个blocked到服务器
hdfs的读取流程

1.client向namenode发起rpc请求,来确定请求文件block所在的位置
2.namenode会视情况返回文件的部分或者全部block列表,对于每个block,namenode都会返回含有该block副本的datanode地址
3.这些返回的DataNode地址,会按照集群拓扑机构得出DataNode与客户端的距离,然后进行排序,排序两个规则,网络拓扑结构中距离client近的排靠前;心跳机制中超时汇报的DataNode状态为stale,这样的排靠后
4.client选取排序靠前的datanode来读取block,如果客户端本身就是DataNode,那么将从本地直接获取数据;底层上本质是建立socket stream(FSDataInputStream),重复的调用父类datainputstream的read方法,知道这个快上的数据读取完毕
5.当读完列表的block后,若文件读取还没有结束,客户端会继续想那么node获取下一批的block列表
6.读取完一个block都会进行checksum验证,如果读取DataNode时出现错误,客户端会同志namenode,然后再从下一个拥有block副本的datanode继续读
7.read方法是并行的读取block信息,不是一块一块的读取;namenode只是返回client请求包含块的DataNode地址,并不是返回请求快的数据文章来源:https://www.toymoban.com/news/detail-600973.html
8.最终读取来所有的block会合并成一个完整的最终文件文章来源地址https://www.toymoban.com/news/detail-600973.html
到了这里,关于hdfs的读写流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!