论文:DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
代码:无。。。
出处:NIPS2022 | 华为诺亚方舟 | 中山大学 | 香港科技大学
效果:
- 在 LVIS 的 1203 个类别上超越了 GLIP,DetCLIP-T 在预训练没有见过 LVIS 的情况下超越 GLIP-T 9.9%
一、背景

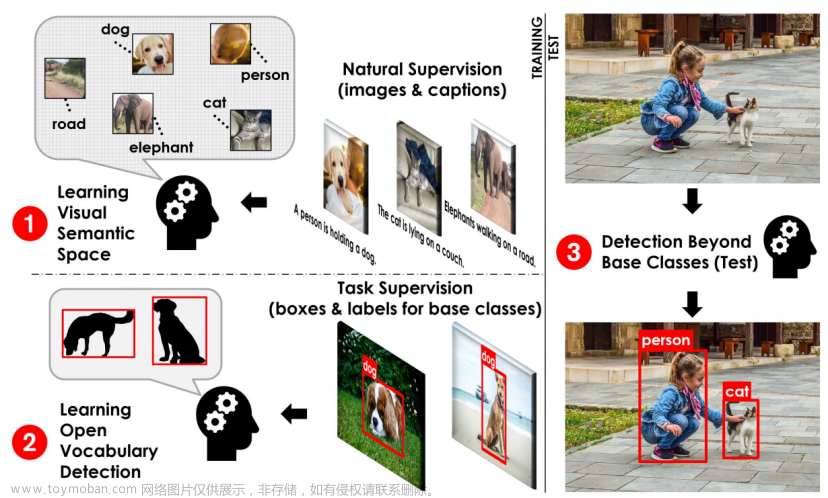
开放世界目标检测是一个通用且有挑战的方向,其目标是要识别和定位任意类别的目标
最近的工作 GLIP 将其构建成了一个 phrase grounding 任务,将所有待检测的类别整合成了一个句子,然后送入 text encoder 进行编码并和图像特征进行对齐
在 text encoder 中,会学习所有类别之间的 attention,这其实是没有必要且低效的,尤其是当类别数量增加时,效率更低
基于此,作者提出了 DetCLIP,dictionary-enriched visual-concept paralleled pre-training method,这里的 concept 指的就是检测任务中的类别名称、grounding 任务中的 phrase 等
- 设计了一个并行的结构来提高效率,不会将整个 prompt text 送入 text encoder,而是将每个 concept 都作为一个独立的个体,将所有的 concept 分别送入不同的 text encoder
- 这样能够避免模型受到不相关类别无效关联,并且能给每个 concept 都产生一个长描述
另外,预训练时候使用的数据集一般域间差别比较大且命名也有较大的不同,比如一个相同类别的目标在在不同数据集中的命名可能是不同的
这样就很难直接从命名上来获得这些类别之间的关联
所以作者重新构建了一个 concept dictionary,丰富联合不同数据集进行 pre-training 的 prompt text
- 首先,从现有的数据集中组合了一个 dictionary
- 然后,基于上面的 dictionary,DetCLIP 能够自动丰富概念和描述

二、方法
2.1 数据构建
一个好的开放世界目标检测器需要很丰富的训练数据,要覆盖到足够多的视觉概念
现有的目标检测数据集类别还是不够多,这也是受限于标注限制
grounding data 和 image-text pair 有很丰富的语义覆盖
所以,需要将这些不同类型的数据整合到一个统一的存储方式来进行后续的任务
如图 3 展示了使用不同类型的数据的不同,a-b 展示了传统的检测数据和 grounding 数据使用不同的数据输入,检测数据将类别当做固定的 label,grounding 数据将整个句子当做输入,构建每个单词之间的关系,然后将编码后的 token 和图像区域进行对齐
GLIP 将目标检测构建成了 grounding 任务,将类别组合成了一个句子,如图 3c
本文作者认为这样的做法有如下问题:
- 会导致不同类别名称间进行无用的交互
- 限制了对比学习中 negative sample 的数量
DetCLIP 如何破局:
- 引入了并行结构,如图 3d,会将每个类别名称单独送入 text encoder 来得到对应的编码结果,模型是从单独的 concept 中学习其语言特征的,可以提高学习效率,如图 4
- 此外,并行结构可以根据类别数量来很容易的扩展
不同数据如何适应这个并行结构:
-
检测数据:假设一个图中有 k 个 positive category,首先将类别数量扩展到 N (随机抽取负类别),N 是预定义好的数量,用于构造 alignment loss,然后将 N 个类别名称作为独立的句子送入 text encoder,并且使用 [end of sentence] token 的编码作为每个类别的 text embedding,最后,将所有 N 个 text embedding concat 起来和 gt 去计算 alignment loss,coco 示例如下:

-
grounding 数据:作者会从 grounding 标注的 caption 中抽取 positive phrase,然后同样扩展到长度 N,一个例子如下:

-
Image-text pair 数据:只有图像和对应的描述,没有标注框。为了获得目标框,首先使用 RPN 来生成与类别无关的 proposal,然后使用预训练好的 CLIP 或 FILIP 为这些 proposal 生成伪标签,然后和前面的处理方法一样


2.2 词汇字典搭建
由于现有的 detection/grounding/image-textpair 这些数据集有较大的 domain gap 和不同的 labeling space。
一个男孩可以被标注为 man、child、people,这些概念也会有包含或层级的关系
这些语义的关系可能会促进预训练,但仅从词汇名称中很难发现他们直接的关系
所以,作者构建了一个大规模的词汇字典,来将不同数据源的词汇统一到一个词汇空间,并且能够通过描述来提供不同词汇之间的关联
例如:
- 一个 car 的描述为:a motor vehicle with four wheels usually propelled by an internal combustion engine
- 一个 motorcycle 的描述为:a motor vehicle with two wheels and a strong frame
这样的描述即表达了 car 和 motorcycle 的不同,也表达它们之间的相同点
作者是如何构建的:
- 首先,从多个源头收集 concept:image-text pair 数据集(YFCC100m)、检测数据集中的类别(Object365、OpenImage)、物体数据集中的物体名称(Tings 数据集)。
- 然后,会先去重然后放入词汇字典中,还有一些特殊的操作,见文章,得到了包含约 14k 词汇和对应定义的字典
词典如何丰富:
- 对于输入的 concept,如果该 concept 在字典里,则会使用该 concept 对应的描述
- 如何不再字典里,会通过计算相似性矩阵,来找出与其最接近的 concept,并且找到对应的描述
- 丰富后的示例如下:

对与 grounding 或 image-text pair 数据,标注描述中指包含了主要的目标,也就是 partial labeling,所以会有两个问题:
- 缺少足够的 negative concept 用于学习更好的编码:DetCLIP 会从字典中随机抽取负样本描述,如图 5b 所示
- 缺少部分 positive concept 的标注:使用了和对 image-text pair 类似的处理方法,即生成伪标签,如图 7 所示
2.3 模型结构
如图 5 所示,DetCLIP 包含:
- 一个 image encoder 来对图像进行编码
- 一个 text encoder 来对 concept 进行编码
- 一个对齐计算模块来用于计算所有 region-word pairs 的对齐得分
loss 如下:


三、效果



 文章来源:https://www.toymoban.com/news/detail-601030.html
文章来源:https://www.toymoban.com/news/detail-601030.html


 文章来源地址https://www.toymoban.com/news/detail-601030.html
文章来源地址https://www.toymoban.com/news/detail-601030.html
到了这里,关于【多模态】16、DetCLIP | 构建超大词汇字典来进行开放世界目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!