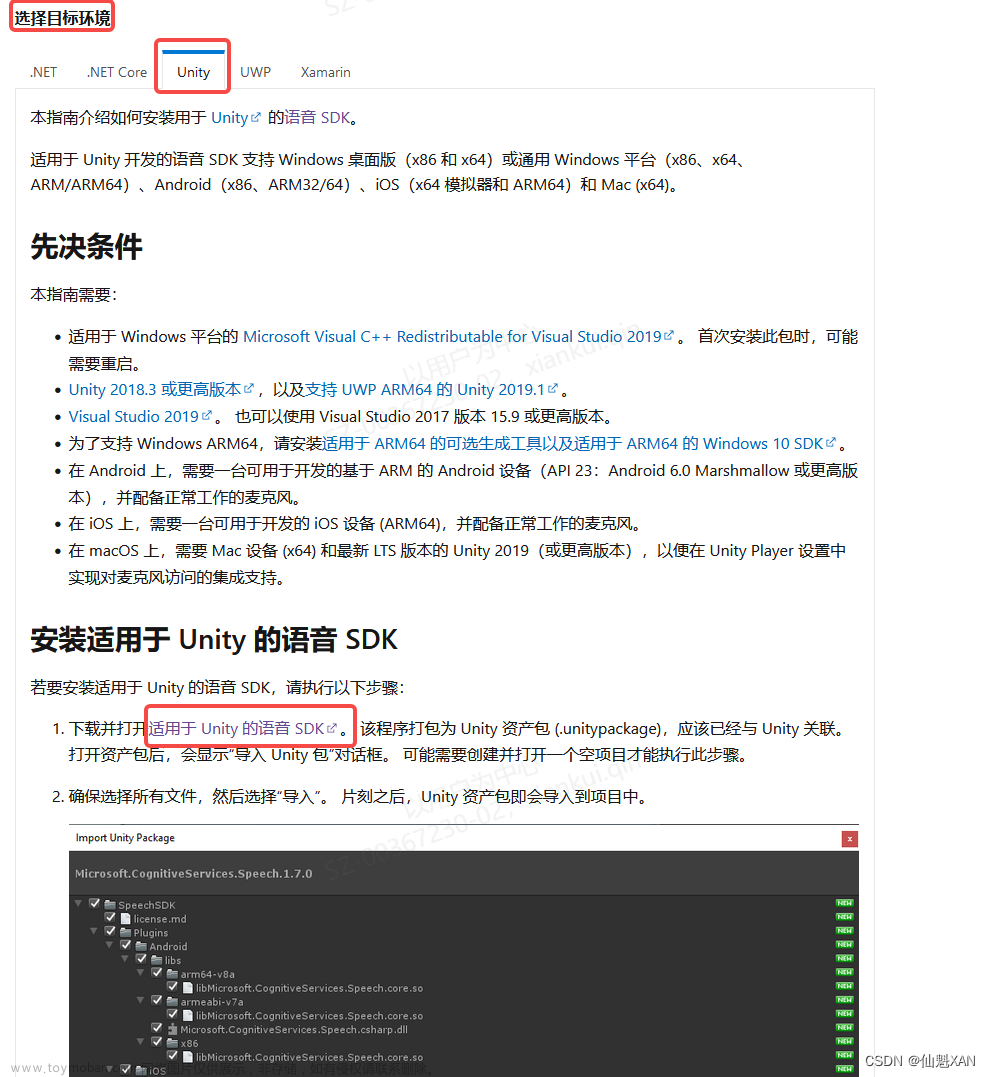
一、前言
AI二次元女友这个项目持续更新,在window端的语音识别和语音合成的功能,在上一篇博文里已经详细说明了微软Azure语音服务的代码实现。也是为了实现一次代码,多端复用这样的诉求,所以全部的代码实现都改成了web api的方式。然而在实测发布到webgl的时候,就发现了一个问题,因为这个项目涉及到麦克风录制声音,用作语音识别,结果在发布的时候,引擎报错,提示unity发布到webgl失败了,查了一下相关资料,原来是unity内置的microphone类是不支持webgl了,所以只好另找解决方案。
·我在网上也查了不少资料,从unity官方也得到了一些信息,解决方案的思路,参见unity官方文档,文档里描述了unity如何调用js的方法,涉及到unity端*.jslib的拓展方法,unity文档:
https://docs.unity3d.com/cn/2020.3/Manual/webgl-interactingwithbrowserscripting.html
因为自己技术能力也有限,所以找了好几个现成的解决方案,做了实测,最后找到一个博主提供的解决方案以及源码。把他的源码集成到我项目里,确实是解决了我的问题,是实现了发布到webgl之后,可以调用麦克风录音,并且通过Azure的语音识别,正确识别到文本了。这过程其实也遇到不少问题,花了点时间,不过最终都解决了,怕自己忘记了,所以就赶忙写个文档留存,以防未来需要的时候,可以查阅。我参考的博主的解决方案里,除了在unity端调用js代码外,还有js回传数据到unity。部分代码实现是在js里实现了,所以在发布webgl后,需要修改一点代码,并加入js库,具体配置方法,见下文。
二、发布Webgl
unity发布webgl项目的设置,首先确保引擎安装了webgl平台的拓展,这个在buildsetting里如果切换不到webgl平台,那就上官网下在安装包,安装上就可以了。转换一下平台即可。发布之前确认一下工程的路径,保证工程的路径是全英文的,不然导出webgl会报错。
发布设置方面:
1、Other Settings里,Color Space修改为Gamma

2、Publishing Settings里,勾选Decompression Fallback

如果说在发布webgl过程发现其他问题,自行到百度或其他渠道去搜一下,这方面的资料很多,基本上都可以找到相关问题的解决方案,以上是我在发布时遇到的一些配置问题,做一下记录。
三、脚本说明
项目涉及到unity端还有js端两部分的代码。
1、unity端代码说明
在unity端,参见官方解决方案,需要在unity的Plugins文件下,创建*jslib文件,在这个库里,按照unity官方提供的示例编写js代码,然后在C#脚本里按照指定的方式引用就可以在unity端调用js代码了。
jslib官方代码示例(这个文件要放在Plugins文件夹下面)
mergeInto(LibraryManager.library, {
Hello: function () {
window.alert("Hello, world!");
},
});在C#端,根据官方示例,编写以下代码就可以引用到js的方法了
[DllImport("__Internal")]
private static extern void Hello();以上是C#调用js代码的示例,在项目功能里已经把录音和结束录音的功能封装好了,直接调用就可以了,根据自己的需要,调用StartRecord()开始录制,调用StopRecord()结束录制
[DllImport("__Internal")]
private static extern void StartRecord();
[DllImport("__Internal")]
private static extern void StopRecord();2、js代码说明
源码提供了js代码,因为项目涉及到js端完成录制后,需要把录音数据回传到unity中使用,所以还需要增加一部分的js代码,实现上述功能。源码里提供了相关的代码,我们只需要在导出的webgl包里,修改相应的代码文件,就可以了。具体的修改方法,见下一节内容。
四、脚本配置
这节里详细说明一下在导出的webgl包中的代码配置内容。
1、添加js脚本
找到[recorder.wav.min.js]脚本,把脚本拷贝到输出的webgl包,index.html相同的文件夹下[根目录]即可。

2、修改index.html
先找到[AddToIndex.js]文件,后续需要添加的代码都在这个文件里了,直接复制就可以了。
①在index.html中引用/recorder.wav.min.js脚本
在[AddToIndex.js]文件,里拷贝"<script src="./recorder.wav.min.js"></script>",添加到index.html里,引用[recorder.wav.min.js]脚本。
<script src="./recorder.wav.min.js"></script>
<script>
var container = document.querySelector("#unity-container");
var canvas = document.querySelector("#unity-canvas");
var loadingBar = document.querySelector("#unity-loading-bar");
var progressBarFull = document.querySelector("#unity-progress-bar-full");
var fullscreenButton = document.querySelector("#unity-fullscreen-button");
var warningBanner = document.querySelector("#unity-warning");
....
后续面代码略
</script>②拷贝js处理代码到index.html中
[AddToIndex.js]里拷贝第7行到110行的代码,到<script>脚本里(可以直接添加到" document.body.appendChild(script);"这行代码后面)
document.body.appendChild(script);这行不要拷贝,就是告诉你从哪行开始粘贴
// 全局录音实例
let RecorderIns = null;
//全局Unity实例 (全局找 unityInstance , 然后等于它就行)
let UnityIns = null;
// 初始化 , 记得调用
function initRecord(opt = {}) {
let defaultOpt = {
serviceCode: "asr_aword",
audioFormat: "wav",
sampleRate: 44100,
sampleBit: 16,
audioChannels: 1,
bitRate: 96000,
audioData: null,
punctuation: "true",
model: null,
intermediateResult: null,
maxStartSilence: null,
maxEndSilence: null,
};
let options = Object.assign({}, defaultOpt, opt);
let sampleRate = options.sampleRate;
let bitRate = options.sampleBit;
if (RecorderIns) {
RecorderIns.close();
}
RecorderIns = Recorder({
type: "wav",
sampleRate: sampleRate,
bitRate: bitRate,
onProcess(buffers, powerLevel, bufferDuration, bufferSampleRate) {
// 60秒时长限制
const LEN = 59 * 1000;
if (bufferDuration > LEN) {
RecorderIns.recStop();
}
},
});
RecorderIns.open(
() => {
// 打开麦克风授权获得相关资源
console.log("打开麦克风成功");
},
(msg, isUserNotAllow) => {
// 用户拒绝未授权或不支持
console.log((isUserNotAllow ? "UserNotAllow," : "") + "无法录音:" + msg);
}
);
}
// 开始
function StartRecord() {
RecorderIns.start();
}
// 结束
function StopRecord() {
RecorderIns.stop(
(blob, duration) => {
console.log(
blob,
window.URL.createObjectURL(blob),
"时长:" + duration + "ms"
);
sendWavData(blob)
},
(msg) => {
console.log("录音失败:" + msg);
}
);
}
// 切片像unity发送音频数据
function sendWavData(blob) {
var reader = new FileReader();
reader.onload = function (e) {
var _value = reader.result;
var _partLength = 8192;
var _length = parseInt(_value.length / _partLength);
if (_length * _partLength < _value.length) _length += 1;
var _head = "Head|" + _length.toString() + "|" + _value.length.toString() + "|end" ;
// 发送数据头
UnityIns.SendMessage("SignalManager", "GetAudioData", _head);
for (var i = 0; i < _length; i++) {
var _sendValue = "";
if (i < _length - 1) {
_sendValue = _value.substr(i * _partLength, _partLength);
} else {
_sendValue = _value.substr(
i * _partLength,
_value.length - i * _partLength
);
}
_sendValue = "Part|" + i.toString() + "|" + _sendValue;
// 发送分片数据
UnityIns.SendMessage("SignalManager", "GetAudioData", _sendValue);
}
_value = null;
};
reader.readAsDataURL(blob);
}
③初始化代码
这里需要注意添加一下实例化代码,需要在index.html里找到unityInstance的实例化代码块里,添加"UnityIns = unityInstance; initRecord();" 这两行代码,(可以添加到"then((unityInstance) => {" 这段代码之后)
script.onload = () => {
createUnityInstance(canvas, config, (progress) => {
progressBarFull.style.width = 100 * progress + "%";
}).then((unityInstance) => {
UnityIns = unityInstance;//拷贝代码
initRecord();//拷贝代码
loadingBar.style.display = "none";
fullscreenButton.onclick = () => {
unityInstance.SetFullscreen(1);
};
}).catch((message) => {
alert(message);
});
};修改完上述代码,就配置完成了,可以部署webgl项目实测一下效果了。这里我实测原作者项目的时候,遇到过一个问题。因为我的项目是需要拿到录音数据,发送到语音识别api的,刚开始发现识别的结果有问题,一直不准确。后来在录制声音的配置上,把采样率调整未44100之后,就识别正常,这里做一下记录,我自己的源码就已经做过这个修改了。
五、结束语
这次这个方案,解决了unity语音识别功能发布到webgl失效的问题,现在这个项目可以顺利部署到webgl使用了。目前这个解决方案,在发布之后还需要做一些js的代码处理,相对麻烦一些,目前我还没有找到更简单的解决方案,未来如果找到更便捷的方案再做分享。
项目的源码,目前还没整理,待我整理好源码之后,再补充到这里,先留个空地,待后续补充上。
AI二次元女友项目源码:
Github地址:https://github.com/zhangliwei7758/unity-AI-Chat-Toolkit
Gitee地址:https://gitee.com/DammonSpace/unity-ai-chat-toolkit
项目视频可参见我的B站主页:
【重大更新->简单部署+跨平台】重构AI二次元小姐姐项目,发布了新的unity工具包,更易用+实用的AI套件,开源代码等你来拿!!
六、参考资料
这个解决方案也查阅了很多大佬的资料,以下是查阅和参考的相关资料传送门:
CSDN博客:https://blog.csdn.net/Wenhao_China/article/details/126779212?spm=1001.2014.3001.5502t
CSDN博文:https://blog.csdn.net/a987654sd/article/details/105551560
解决方案作者的源码地址:
Github:https://github.com/HiWenHao/UnityWebGLMicrophone
附加材料:
以下两个webgl使用microphone方案我尚未验证,也放在这里供参考
解决方案1:https://gitcode.net/mirrors/xiangyuecn/recorder?utm_source=csdn_github_accelerator文章来源:https://www.toymoban.com/news/detail-601112.html
解决方案2:https://github.com/tgraupmann/UnityWebGLMicrophone/tree/maste文章来源地址https://www.toymoban.com/news/detail-601112.html
到了这里,关于Unity+chatgpt+webgl实现声音录制+语音识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://imgs.yssmx.com/Uploads/2024/02/662057-1.png)