分词器
分词和分词器
Analysis∶文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词
Analysis是通过Analyzer来实现的。分词就是将文档通过Analyzer分成一个一个的Term,每一个Term都指向包含这个Term的文档。
分词器的组成
- character filters(字符过滤器) : 在文本进行过滤前需要先进行预先处理
- tokenizers(分词器) : 对词句进行响应的分词
- token filter(token过滤器) : 将切分的单词进行加工,如大小写转化,去除介词等
在ES中默认会使用标准分词器standardAnalyer,其中英语会进行单词分词,中文则是单字分词
分词顺序
character filter ===> tokenizers ===> token filter
构成数量
character filter(大于等于0) ===> tokenizers(至少有1个) ===> token filter(大于等于0)
ES中的分词器
- Standard Analyzer : 默认分词器,小写处理
- Simple Analyzer-按照单词切分(符号被过滤),小写处理,中文按照空格进行分词
- Stop Analyzer -小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer-按照空格切分,不转小写
- Keyword Analyzer-不分词,直接将输入当作输出
测试分词器
其中将standard修改为你要测试的即可
# 分词器
POST /_analyze
{
"analyzer": "standard",
"text": "你好我是张三 i am very happy"
}
指定分词器
分词器需要在指定映射的时候进行设置
#设置分词器
PUT /analy
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "standard"
}
}
}
}
IK分词器(中文分词)
https://github.com/medcl/elasticsearch-analysis-ik
需要我们注意的是IK分词词需要和你的ES版本相同
下载完后解压缩放入ES的/plugins目录下 然后我们重启一下
然后我们重启一下
测试使用IK分词器
ik分词器叫做ik_smart或ik_max_word他们俩在文本的拆分力度上有所不同,后者更加细致
# IK分词器
POST /_analyze
{
"analyzer": "ik_smart",
"text": "你好我是张三 i am very happy"
}
这里可以看到对中文的分词已经出来了
IK分词器自定义扩展词和停用词IK支持自定义扩展词典和停用词典
- 扩展词典:就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典。
- 停用词典:就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典。
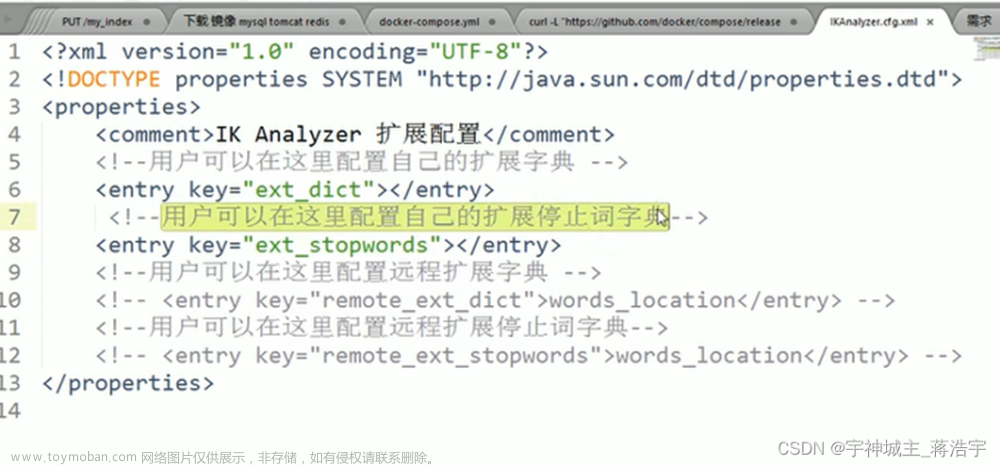
我们可以直接去config/IKAnalyzer.cfg.xml文件中进行定义,你问我怎么知道的?人家README里写的


1. 修改xml文件
我们在扩展词典的配置中设置我们扩展词典的文件叫做self_ext.dic,这样我们就配置好了扩展词典的位置
2.创建扩展词典文件
由于我们现在只是配置了扩展词典的名字,但是实际上我们还没有这个词典,所以我们要对应创建出来

3.编写扩展词典
如下我们编辑self_ext.dic文件,这里注意扩展词只能每行写一个
我这里设置了张三,李四,王五作为扩展词
4.重启ES
5.测试扩展词
POST /_analyze
{
"analyzer": "ik_smart",
"text": "你好我是张三李四王五 i am very happy"
}
当然停用词也是一样
但是推荐大家直接使用定义好的扩展词和停用词文章来源:https://www.toymoban.com/news/detail-601130.html
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">extra_main.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">extra_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
 文章来源地址https://www.toymoban.com/news/detail-601130.html
文章来源地址https://www.toymoban.com/news/detail-601130.html
到了这里,关于ElasticSearch系列——分词器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!