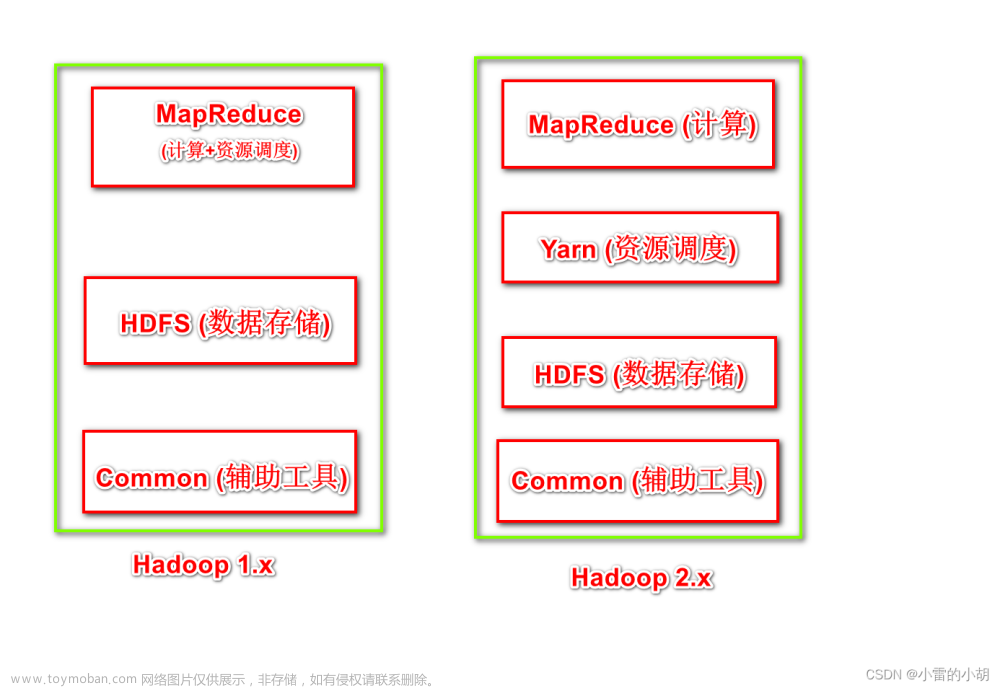
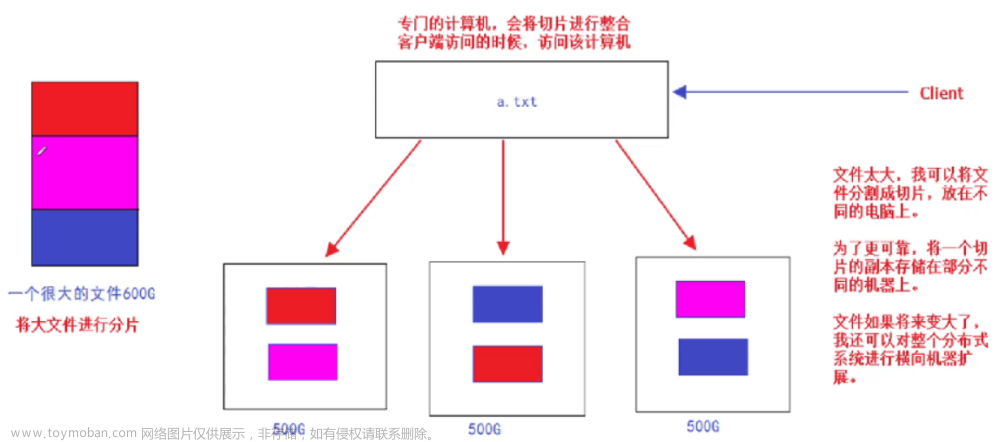
hadoop集群简介
- hadoop加群包括两个集群:hdfs集群,yarn集群
- 两个集群逻辑上分离,通常物理上在一起
- 两个集群都是标准的主从架构集群

- 逻辑上分离:两个集群相互之间没有依赖,互不影响
- 物理上在一起:某些角色今晚往往部署在同一台物理服务器上
- MapReduce集群呢?
- MapReduce是计算框架、代码层面的组件没有集群之说

- MapReduce是计算框架、代码层面的组件没有集群之说
hadoop部署模式

Hadoop集群安装
1.集群角色规划
- 角色规划的准则
- 根据软件工作特性和服务器硬件资源情况合理分配
- 比如依赖内存工作的namanode是不是不花在大内存机器上
- 角色规划注意事项
- 资源上有抢夺冲突的,尽量不要部署在一起
- 共偶作上需要相互配合的,尽量部署在一起

2.服务器基础环境准备
- 防火墙关闭(三台机器)
- systemctl stop firewalld. service #关闭防火墙
- systemtl disable firewalld. service #禁止防火墙开启自启
- ssh免密登录(node1执行—>node1|node2|node3)
- ssh-keygen #四个回车 生成公钥、私钥
- ssh-copy-id node1,ssh-cpoy-id node2,ssh-coppy-id node3
- 集群时间同步(三台机器)
- yum -y install ntpdata
- ntpdate ntp2.aliyun.com
- JDK 1.8安装(三台机器)
3.上传安装包
- 创建同一工作目录(三台机器)
- mkdir -p /export/server/ #软件安装路径
- mkdir -p /export/data/ #数据安装路径
- mkdir -p /export/softwarw/ #安装包存放路径
- 上传、解压安装包
hadoop-3.1.4-bin-snappy-CentOS7.tar.gz
tar zvxf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /export/server
hadoop安装包目录结构

5.编辑hadoop配置文件
- hadoop-env.sh
- cd /esport/server/hadoop-3.1.4/etc/hadoop/
- vim hadoop-env.sh

- core-site.xml
- cd /export/server/hadoop-3.1.4/etc/hadoop/
- vim sore-site.xml

-
hafs-site.xml
- cd /export/server/hadoop-3.1.4/etc/hadoop/
- vim hdfs-site.xml

-
mapred-site.xml
- cd /export/server/hadoop-3.1.4/etc/hadoop/
- vim mared-site.xml

-
yarn-site.xml
- cd /export/server/hadoop3.1.4/etc/hadoop
- vim yarn-site.xml

-
workers文章来源:https://www.toymoban.com/news/detail-601754.html
- cd /export/server/hadoop-3.1.4/etc/hadoop
- vim workers

6.分发安装包
- 在node1机器上奖hadoop安装包scp同步到其他机器
- cd /export/server/
- scp -r hadoop-3.1.4 root@node2: /export/server/
- scp -r hadoop-3.1.4 root@node3: /export/server/
7.配置hadoop环境变量
- 在node1上配置hadoop换件变量
- vim /etc/profile
- export HADOOP_HOME=/export/server/hadoop-3.1.4
- export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin:$HADOOP_HOME/bin
- 将修改后的环境变量同步到其他机器
- scp /etc/profile root@node2:/etc/
- scp /etc/profile root@node3:/etc/
- 重新加载环境变量,验证是否生效(三台机器)
- sourece /etc/profile
- hadoop #验证是否生效

8.NameNode format(格式化操作)
- 首次启动hdfs时,必须对齐进行格式化操作
- format本质上是初始化工作,进行hdfs清理和准备工作
- 命令:hdfs namenode -format
 文章来源地址https://www.toymoban.com/news/detail-601754.html
文章来源地址https://www.toymoban.com/news/detail-601754.html
- 首次启动之前需要format操作
- format只能进行一次,后续不在需要
- 如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别,通过删除所有机器hadoop.tmp.dir目录重新format解决
hadoop集群启动关闭-手动逐个进程启停
- 每台机器上每次手动启动关闭一个角色进程
- hdfs集群
- hafs --daemon start namenode|datanode|decondarynamenoe
- hafs --daemon stop namenode|datanode|decondarynamenoe
- yarn集群
- yarn --daemon start resourcemanager|nodemanager
- yarn --daemon stop resourcemanager|nodemanager
shell脚本一键启停
- 在node1上,使用软件自带的shell脚本一键启动
- 前提:配置好机器之间的shh免密登录和workers文件
- hdfs集群
- start-dfs.sh
- stop-dfs.sh
- yarn集群
- start-yarn.sh
- stop-yarn.sh
- hadoop集群
- start-all.sh
- stop-all.sh

到了这里,关于Hadoop简介以及集群搭建详细过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!