业务场景描述
1、业务库使用pg数据库, 业务数据可以改动任意时间段数据
2、监听采集业务库数据,实时捕捉业务库数据变更,同时实时变更目标表和报表数据
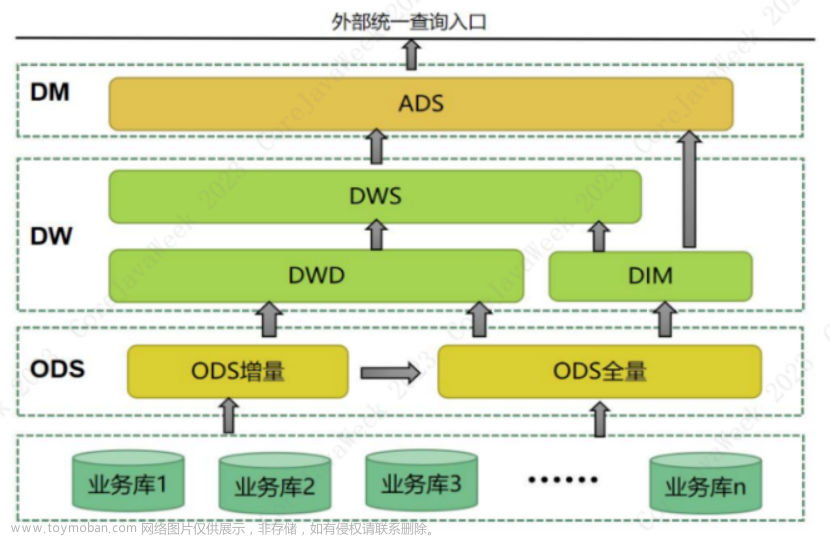
数仓架构
实时数据流图与分层设计说明
1、debezium采集pg库表数据同步到kafka 【kafka模式】
2、flink 消费kafka写入pg或kafka 【upset-kafka,新版kafka可以基于source 过滤重复数据,降低下游重复计算压力】
3、重复第二步,截止计算完成
同时写入pg和kafka 的目的:
1、若验证pg表数据不一致,消费kafka数据分析数据异常原因
2、多层计算任务可以再次消费kafka数据进行实时计算
数仓分层
ods
1、表结构基本同业务表结构,做数据合并或同步操作,数据写入pg,目的是写入pg库的目的是为了与计算完成的表进行关联
2、表结构基本同业务表结构,做数据合并或同步操作,数据写入Kafka,供下游实时计算使用,同时还能为下游过滤重复数据【新版kafka支持】
3、日期字段格式化处理【因debezium采集datetime日期类型会强转为bigint类型,且比当前时区加8个时区,要编写java代码进行日期格式转换处理,不一定非java】
dim
维度表计算任务
dwd
主要是做明细事实表规范化处理层
1、数仓整体字段命名一致性与规范化处理【看数仓开发规范】,复杂字符串解析【如json、数组等类型】
dws
主要基于明细数据做轻度汇总
1、事实明细表关联维度表进行某个维度上的汇总操作
2、source 维度表时,只需要source维度表的id字段
数仓建模注意项
1、事实表之间的关联关系是一对一 ,一对多,多对一,多对多
2、若主表与join表是一对多或多对多 , 实时数仓etl的时候要把主表和join表的主键取出来做联合主键,不然写入数据库或kafka,数据可能会乱序,从而引起数据漏数,导致数据不一致。【致命问题】
数仓建模开发规范
命名规范
1、字段命名规范
日期、数值、字符串等字段类型同一规范化命名
2、库名、表名命名规范
结合业务线和表的作用或用途来规范化命名
3、模型字段排序规范
事实表模型规范
1、主键在前,维度表字段id紧追其后,维度字段从大到小排序【或小到大】,事实指标在维度表字段后,最后加计算时间字段。
2、事实表建议不要加维度表id对应的name值【实时数仓非常不建议,若name值可以修改,轻则会导致下游数据回撤,重则可能导致写有数据乱序或漏数,具体场景原因分析,下次遇到再分析】
维度表模型规范
主键在前, 维度字段从大到小排序【或小到大】,维度id和id对应的name值可以放一起【或先放id字段,name值同一放在后面】
问题与原因分析
1、debezium 采集pg 表,数据类型问题
因debezium采集datetime日期类型会强转为bigint类型,且比当前时区加8个时区,要编写java代码进行日期格式转换处理,不一定非java
2、业务库出现大批量刷表数据,debezium采集connector 可能会挂
原因分析:
业务库若大批量刷表,debezium的connector服务无法承接大批量增量采集数据的压力;
解决方法:
1、暂停debezium增量同步任务,理论上不需要暂停可以撑住【真实场景:业务刷新某个业务表的某个字段,表数据量1.5亿】
2、评估影响采集端压力,在不暂停采集任务的同时,持续观察下游计算任务稳定,保证计算任务若失败快速从checkpoint 恢复
3、业务库出现大批量刷表数据,实时计算任务会出现长时间延迟或内存溢出或任务失败
原因分析:
1、大批量数据发往下游,计算任务会出现大批量数据回撤
2、因刷新数据问题,数据库日志位移会落后,追赶数据库日志需要耗费一点时间
3、大批量数据发往下游,分配给任务的内存过小,导致内存溢出,从而导致任务失败
解决方法:
1、新增upset-kafka过滤层,可以按source字段过滤重复数据,有效避免下游任务出现大量数据回撤
2、因内存溢出导致任务失败,通过增加内存,再次从checkpoint 启动即可
3、业务库会修改维度表数据,导致实时任务出现数据延迟【或数据恢复耗时较长】
原因分析:
1、维度表与事实表关系:一对多
2、把维度表的name值加到source ,【批量】修改维度表某个字段的name值,因一条维度记录会关联到非常多的事实数据,导致下游关联任务发生大量数据回撤【若有多个依赖任务,每个依赖任务都会受到影响】
解决方法:
4、多表关联多并发数据乱序
问题描述:
1、多表(left)join时,(left)join的表出现多次修改,多并发sink到pg的表数据出现数据乱序
sql 如下:
select A.id , B.name
from A
left join B on B.id = A.id -- id 仅为关联条件,不是表主键
原因分析:
1、主键不变,修改id的name值,left join的表出现多次修改,即kafka会收到多条修改数据同时也会收到对修改记录的删除数据【如:主键,null ; 代表回撤主键对应的数据】;
1、 仅仅靠左表joinkey1并不能保证下游数据的唯一性。
2、flink sql内部在高并发下,以joinkey1和joinkey2的拼接字符串做哈希,然后根据哈希值分配给不同的并发(线程)计算。
3、在joinkey1或者joinkey2发生update的话,会将变更信息发送到下游kafka。
4、初始化或者变更数多时,每次批次处理数据对于同一条a_source.id,有多条不同joinkey值的数据,一起处理。
5、对于相同a_source.id(即下游唯一的id),不同的joinkey数据会发送到不同的并发线程处理,导致下游相同a.source_id写入kafka相同的分区,不同并发处理能力不同,从而相同a.source_id的变更信息数据并不会按照变更时间进行处理,导致数据乱序。
解决方法:
1、把每个表的主键和left join关联条件字段放一起做联合主键,修改sql如下
select A.pk_id || B.pk_id || B.id as pk_id ,A.id , B.name -- pk_id 分别是表A、B的主键字段
from A
left join B on B.id = A.id -- id 仅为关联条件,不是表主键
5、多并发写入pg库表死锁
问题描述
1、事实表关联维度表计算,在一个实时计算间隔内维度表出现一个id对应多个name值,导致sink到pg时,对应的表记录死锁了
解决方案:
1、维度表的name值不参与实时计算,实时任务计算完成后,在pg表关联维度表取name值
2、在实时任务中使用max(name),保证发往下游只有一条name的记录
6、明细数据一致性对比验证
业务库与实时库表主键对比
7、数据容错与恢复
1、增量checkpoint , 可以设置保留checkpoint的个数,
在配置文件【flink-conf.yaml】中加:state.checkpoints.num-retained:24
2、全量checkpoint
8、下游表没有数据或漏数分析
原因分析:
1、pg表A字段(join 关联字段)类型为varchar , flink source 表时,A字段类型是int , 使用debezium 采集, source 表数据时,A字段数值不能转换,值为null,关联条件不匹配导致没有数据输出
2、pg表A字段(join 关联字段)类型为date ,若使用debezium 采集, A字段数值会转换为 bignint 类型, 若flink source 表的A字段类型是int , 类型值准确性丢失,导致表数据关联失败,没有数据输出
解决:修改pg表A字段类型,重跑任务解决
注意:这种情况任务不会报错,要排查数据情况才能发现
9、实时思想
1、join 和where 条件一样,本质都是对from 主表 数据的筛选
2、left join 只是在主表上加字段,不会筛选主表数据,但会影响sink端的数据回撤,具体解析看上面内容
3、sink 到下游每条记录都有应该有主键
10、多表关联比单表计算性能慢的原因分析
业务场景:
exactly-once 模式
flink upset-kafka模式
Alignment happens only for operators with multiple predecessors (joins) as well as operators with multiple senders (after a stream repartitioning/shuffle). Because of that, dataflows with only embarrassingly parallel streaming operations (map(), flatMap(), filter(), …) actually give exactly once guarantees even in at least once mode.
flink 官网:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/concepts/stateful-stream-processing/#exactly-once-vs-at-least-once文章来源:https://www.toymoban.com/news/detail-601899.html
11、flink sql - 多表关联乱序的思考
1、dwd 明细数据不关联code ,取name
2、dws 要拆分多个code,取name后拼接成一行;使用单并发跑
3、代码任务管理:逻辑相同的代码放在一个任务里跑,
1)一个表并发到多个表
2) 多表关联逻辑,单并发跑
以上的情况分两个任务,即使source 有一部分一样文章来源地址https://www.toymoban.com/news/detail-601899.html
到了这里,关于flink 实时数仓构建与开发[记录一些坑]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!