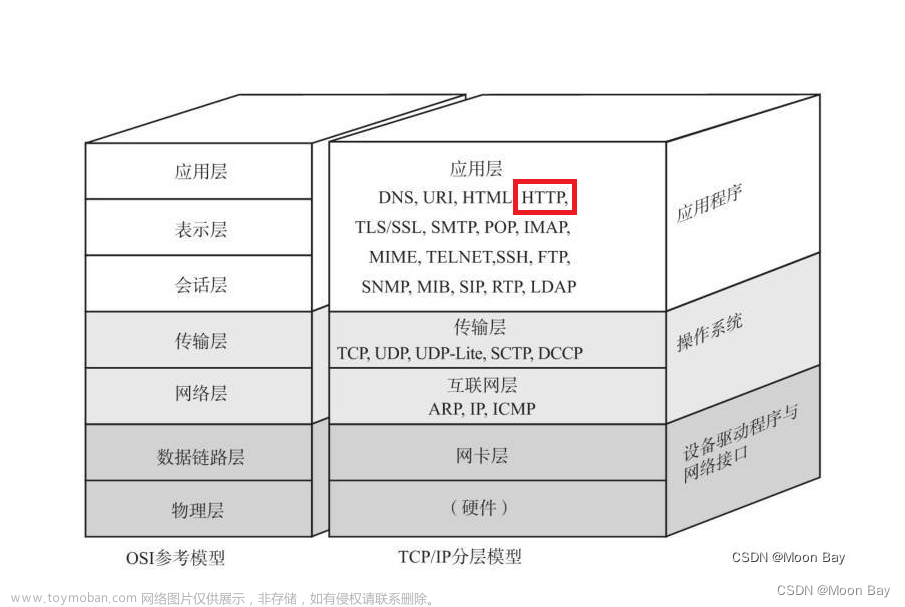
HTTP简介
HTTP(HyperText Transfer Protocol)即超文本传输协议,是一种详细规定了浏览器和万维网服务器之间互相通信的规则,它是万维网交换信息的基础,它允许将HTML(超文本标记语言)文档从Web服务器传送到Web浏览器。
HTTP基于TCP/IP通信协议来传递数据。
HTTP协议工作于客户端-服务端架构上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
HTTP默认端口号为80,但是你也可以改为8080或者其他端口。
HTTP请求与响应
HTTP遵循请求(Request)/应答(Response)模型,Web浏览器向Web服务器发送请求时,Web服务器处理请求并返回适当的应答。
HTTP请求
HTTP请求报文格式就如下图所示:
一个HTTP请求报文由四个部分组成:请求行、请求头、空行、请求体。
请求行
请求行由请求方法字段、URL字段和HTTP协议版本字段 3 个字段组成,它们用空格分隔。比如 GET /data/info.html HTTP/1.1。
HTTP请求方法:
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了五种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
URL字段:
URL由四部分组成: 协议, 路径, ?, &
- 协议:http或者https
- 路径://ts2.cn.mm.bing.net/th
- ?:问号前是URL组成部分,问号后是URL参数部分
- &:用于分割参数
例子:https://ts2.cn.mm.bing.net/th?pid=Wdp&w=300&h=304&qlt=60&c=1&rs=1
请求头
HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者 POST)。如有必要,客户程序还可以选择发送其他的请求头。大多数请求头并不是必需的,但Content-Length除外。对于POST请求来说 Content-Length必须出现。
常见的请求头字段含义:
Accept: 浏览器可接受的MIME类型。
Accept-Charset:浏览器可接受的字符集。
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间。
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。
Content-Length:表示请求消息正文的长度。
Host: 客户机想访问的主机名。Host头域指定请求资源的Intenet主机和端口号,必须表示请求url的原始服务器或网关的位置。HTTP/1.1请求必须包含主机头域,否则系统会以400状态码返回。
If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间。只有当所请求的内容在指定的时间后又经过修改才返回它,否则返回304“Not Modified”应答。
Referer:客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的(防盗链)。包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
User-Agent:User-Agent头域的内容包含发出请求的用户信息。浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。
Cookie:客户机通过这个头可以向服务器带数据,这是最重要的请求头信息之一。
Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。
From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
Connection:处理完这次请求后是否断开连接还是继续保持连接。如果Servlet看到这里的值为“Keep- Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用长连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入 ByteArrayOutputStream,然后在正式写出内容之前计算它的大小。
Range:Range头域可以请求实体的一个或者多个子范围。例如,
表示头500个字节:bytes=0-499
表示第二个500字节:bytes=500-999
表示最后500个字节:bytes=-500
表示500字节以后的范围:bytes=500-
第一个和最后一个字节:bytes=0-0,-1
同时指定几个范围:bytes=500-600,601-999
但是服务器可以忽略此请求头,如果无条件GET包含Range请求头,响应会以状态码206(PartialContent)返回而不是以200 (OK)。
UA-Pixels,UA-Color,UA-OS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
空行
它的作用是通过一个空行,告诉服务器请求头部到此为止。
请求体
若方法字段是GET,则此项为空,没有数据
若方法字段是POST,则通常来说此处放置的就是要提交的数据,比如要使用POST方法提交一个表单,其中有user字段中数据为“admin”, password字段为123456,那么这里的请求数据就是 user=admin&password=123456,使用&来连接各个字段。
HTTP响应
HTTP响应报文格式就如下图所示:
HTTP响应报文由三部分组成:响应行、响应头、空行、响应体。
响应行
响应行一般由协议版本、状态码、状态码描述组成。
比如 HTTP/1.1 200 OK。其中协议版本HTTP/1.1或者HTTP/1.0,200就是它的状态码,OK则为它的描述。
常见状态码:
- 100~199:表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程。
- 200~299:表示成功接收请求并已完成整个处理过程,常用200。
- 300~399:为完成整个处理过程,客户需进一步细化请求。例如:301表示请求的资源已被永久的移动到新URL,返回信息会包括新的URL,浏览器会自动定向到新URL,今后任何新的请求都应使用新的URL代替。302与301类似,但资源只是临时被移动,客户端应继续使用原有URL。304和307表示服务器要求客户自己从缓存拿数据。
- 400~499:客户端的请求有错误。401表示请求要求身份验证。403表示客户端权限不够,服务器拒绝访问。404表示请求的资源在web服务器中没有。499用来记录服务端向客户端发送 HTTP 请求前,客户端已经关闭连接的一种情况,该状态码属于Nginx。
- 500~599:服务器端出现错误。500表示服务器内部错误,无法完成请求。 501表示服务器不具有完成请求的功能。502表示网关错误。503表示因暂时超载或临时维护而导致服务不可用。504表示客户端所发出的请求没有到达网关而出现网关超时。 505表示服务器不支持请求中所用的 HTTP 协议版本。
响应头
响应头用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据。
设置HTTP响应头往往和状态码结合起来。例如,有好几个表示“文档位置已经改变”的状态代码都伴随着一个Location头,而401(Unauthorized)状态代码则必须伴随一个WWW-Authenticate头。然而,即使在没有设置特殊含义的状态代码时,指定应答头也是很有用的。应答头可以用来完成:设置Cookie,指定修改日期,指示浏览器按照指定的间隔刷新页面,声明文档的长度以便利用持久HTTP连接,……等等许多其他任务。
常见的响应头字段含义:
Allow:服务器支持哪些请求方法(如GET、POST等)。
Content-Encoding:文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE4、IE5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader(“Accept- Encoding”))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。
Content-Length:表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStram,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。
Content- Type:表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置 Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。
Date:当前的GMT时间,例如,Date:Mon,31Dec200104:25:57GMT。Date描述的时间表示世界标准时,换算成本地时间,需要知道用户所在的时区。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。
Expires:告诉浏览器把回送的资源缓存多长时间,-1或0则是不缓存。
Last-Modified:文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。
Location:这个头配合302状态码使用,用于重定向接收者到一个新URL地址。表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。
Refresh:告诉浏览器隔多久刷新一次,以秒计。
Server:服务器通过这个头告诉浏览器服务器的类型。Server响应头包含处理请求的原始服务器的软件信息。此域能包含多个产品标识和注释,产品标识一般按照重要性排序。Servlet一般不设置这个值,而是由Web服务器自己设置。
Set-Cookie:设置和页面关联的Cookie。Servlet不应使用response.setHeader(“Set-Cookie”, …),而是应使用HttpServletResponse提供的专用方法addCookie。
Transfer-Encoding:告诉浏览器数据的传送格式。
WWW-Authenticate:客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader(“WWW-Authenticate”, “BASIC realm=\”executives\”“)。注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问。
setDateHeader方法和setIntHeadr方法专门用来设置包含日期和整数值的应答头,前者避免了把Java时间转换为GMT时间字符串的麻烦,后者则避免了把整数转换为字符串的麻烦。
HttpServletResponse还提供了许多设置
setContentType:设置Content-Type头。大多数Servlet都要用到这个方法。
setContentLength:设置Content-Length头。对于支持持久HTTP连接的浏览器来说,这个函数是很有用的。
addCookie:设置一个Cookie(Servlet API中没有setCookie方法,因为应答往往包含多个Set-Cookie头)。
空行
响应头部的最后会有一个空行,表示响应头部结束,接下来为响应数据。与请求报文一致。
响应体
响应体就是响应的消息体,如果是纯数据就是返回纯数据,如果请求的是HTML页面,那么返回的就是HTML代码,如果是JS就是JS代码,如此之类。
HTTP请求方法GET和POST之间的区别
幂等的意味着对同一URL的多个请求应该返回同样的结果。
- 总的来说,GET 用于获取信息,是无副作用的,是幂等的,且可缓存。POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存(POST在带有明确缓存请求头的情况下是可以被缓存的,但并不常用)。
- GET请求的数据和参数会暴露在起请求行的URL中,POST可以把提交的数据和参数放置在请求体中,也可以拼接在请求行的URL中。因此,POST方法相对于GET方法更加安全一些。
- GET的请求体一般是空的。POST的请求体不是空的。
- GET是通过URL提交数据,因此GET可提交的数据量就跟URL所能达到的最大长度有直接关系。URL的最大长度由特定的浏览器及服务器来限制。POST理论上讲是没有大小限制的,HTTP协议规范也没有进行大小限制,但实际上post所能传递的数据量大小取决于服务器的设置和内存大小。
HTTP为什么是无状态的
因为HTTP的每个请求都是完全独立的,每个请求包含了处理这个请求所需的完整的数据,协议本身并不记录用户的信息的状态。
既然HTTP协议是无状态的,不会记录用户信息,那么怎么样才能让HTTP协议记录用户信息呢?换句话说,服务器怎么判断发来HTTP请求的是哪个用户?于是,两种用于保持HTTP状态的技术就应运而生了,一个是 cookie,而另一个则是 session。
cookie原理
由服务器产生内容,浏览器收到内容后保存在本地,即cookie;当浏览器再次访问时,浏览器会自动带上cookie,这样服务器就能通过cookie的内容来判断是哪个用户在访问服务器。
session 原理
会话,指用户登录网站后的一系列动作,比如浏览商品添加到购物车并购买。会话跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。
cookie 和 session 的区别
常用的会话跟踪技术是cookie与session。由于HTTP是无状态的,因此需要用session或者cookie识别不同的用户。客户机通过cookie可以向服务器带数据,服务器通过session可以向客户端带数据。
session和cookie的区别如下:
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。session的sessionID是放在cookie里,要想攻破session的话,第一要攻破cookie。攻破cookie后,cookie里面的sessionID是加密的,而且session过期时sessionid也会失效,想在短时间内功破加了密的sessionID很难。
cookie如何设置
cookie可以使用 setcookie(name,value,expire,path,domain,secure)来设置,cookie的参数如下:
参数 描述文章来源:https://www.toymoban.com/news/detail-602104.html
name: 必需,规定 cookie 的名称。
value: 必需,规定 cookie 的值。
expire:可选,规定 cookie 的有效期。
path: 可选,规定 cookie 的服务器路径。
domain:可选,规定 cookie 的域名。
secure:可选,规定是否通过安全的 HTTPS 连接来传输 cookie。
cookie被禁止后如何使用session
cookie被禁止后可以利用URL重写来继续使用session。URL重写的本质是在每次请求的URL后面加上一个sessionid=xxxx这样的参数,在服务端解析时,获取到sessionid对应的值,并根据其获取到对应的Session对象,从而保证了交互状态一致。文章来源地址https://www.toymoban.com/news/detail-602104.html
到了这里,关于HTTP超本文传输协议的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[计算机网络]深度学习传输层TCP协议](https://imgs.yssmx.com/Uploads/2024/02/828694-1.gif)
![[计算机网络]---Http协议](https://imgs.yssmx.com/Uploads/2024/02/826218-1.png)