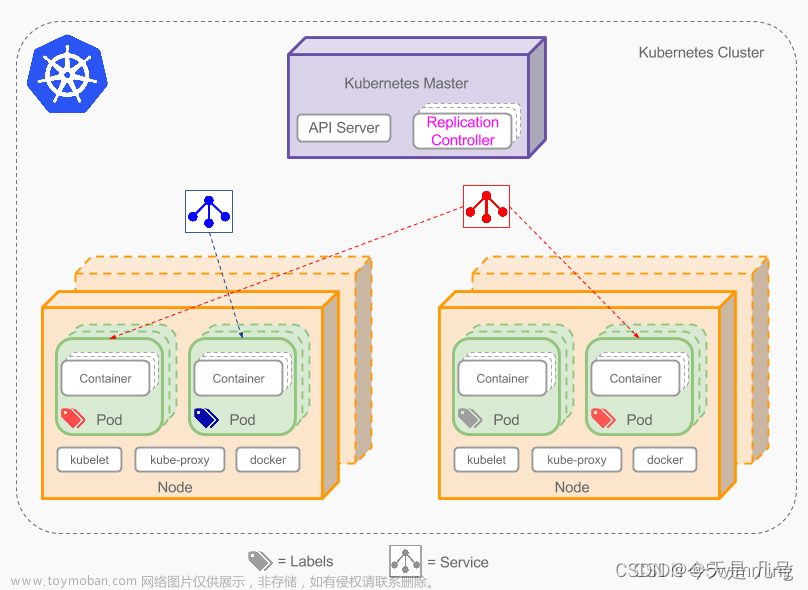
Pod 作为k8s创建,调度,管理的基本单位。由上级的Controller对Node上安装的Kubelet发送指令对Pod进行管理,因此我们需要详细了解关于Pod。
其中最为基本的操作就是Pod的创建,删除,调度,查看!
对于Pod的创建,相关联的就有,对Pod的资源分配,资源限制;对Pod的创建调度,基于Pod的高可用性,将Pod调度到不同数据中心的Node节点;以及对Pod应用的数据存储

Pod和API server的通信
节点与控制面板通信:
所有从节点(或运行于其上的 Pod)发出的 API 调用都终止于 API 服务器。Kubernetes 采用的是中心辐射型(Hub-and-Spoke)API 模式。
想要连接到 API 服务器的 Pod 可以使用服务账号安全地进行连接。 当 Pod 被实例化时,Kubernetes 自动把公共根证书和一个有效的持有者令牌注入到 Pod 里。 kubernetes 服务(位于 default 名字空间中)配置了一个虚拟 IP 地址, 用于(通过 kube-proxy)转发请求到 API 服务器的 HTTPS 末端。
从控制面(API 服务器)到节点有两种主要的通信路径
1.API 服务器到集群中每个节点上运行的 kubelet 进程
2.从 API 服务器通过它的代理功能连接到任何节点、Pod 或者服务。
API 服务器到 kubelet
从 API 服务器到 kubelet 的连接用于:
- 获取 Pod 日志。
- 挂接(通过 kubectl)到运行中的 Pod。
- 提供 kubelet 的端口转发功能。
API 服务器到节点、Pod 和服务
从 API 服务器到节点、Pod 或服务的连接默认为纯 HTTP 方式,因此既没有认证,也没有加密。
这些连接可通过给 API URL 中的节点、Pod 或服务名称添加前缀 https: 来运行在安全的 HTTPS 连接上。 不过这些连接既不会验证 HTTPS 末端提供的证书,也不会提供客户端证书。
因此,虽然连接是加密的,仍无法提供任何完整性保证。 这些连接 目前还不能安全地 在非受信网络或公共网络上运行。
SSH 隧道
Kubernetes 支持使用 SSH 隧道来保护从控制面到节点的通信路径。 在这种配置下,API 服务器建立一个到集群中各节点的 SSH 隧道(连接到在 22 端口监听的 SSH 服务器) 并通过这个隧道传输所有到 kubelet、节点、Pod 或服务的请求。 这一隧道保证通信不会被暴露到集群节点所运行的网络之外。
加快Pod启动
k8s 1.27版本加入的特性
镜像拉取默认是串行作业,kubelet 一次只发送一个镜像拉取请求, 其他的镜像需要等待正在处理的拉取请求完成。
可以启用镜像拉取的并行作业设置
serializeImagePulls 默认为true,设置为false # kubelet 中配置
为防止因拉取镜像导致的服务器过载,可设置并行拉取数量
maxParallelImagePulls n # kubelet 中配置
提高了 kubelet 默认 API 每秒查询限值
在多个Pod创建时,需要大带宽访问 kube-apiserver。如在突然扩缩情况,kubelet 需要同步 Pod 状态并准备 ConfigMap、Secret 或卷。
v1.27之前版本,kubeAPIQPS 的默认值为 5,kubeAPIBurst 的默认值为 10;以前在具有 50 个以上 Pod 的节点中,我们经常在 Pod 启动期间在 kubelet 上遇到 volume mount timeout。
v1.27版本将kubeAPIQPS的默认值提高到了 50 kubeAPIBurst` 的默认值提高到了100
事件驱动的容器状态更新
Kubernetes 为 kubelet 提供了2种方法来检测 Pod 的生命周期事件
基于事件的 机制已进阶至 Beta,但默认被禁用
必要时提高 Pod 资源限值
某些 Pod 在启动过程中可能会耗用大量的 CPU 或内存。 如果 CPU 限值较低,则可能会显著降低 Pod 启动过程的速度。
Kubernetes v1.22 引入了一个名为 MemoryQoS 的特性门控
memoryThrottlingFactor # 默认值最初为 0.8,Kubernetes v1.27 中更改为 0.9
减小该因子(将为容器 cgroup 设置较低的上限)会增加了回收压力。 提高此因子将减少回收压力。
更改Pod的资源
如果 Pod 设置了 CPU 或内存资源,更改资源值会导致 Pod 重新启动。这对于运行的负载来说是一个破坏性的操作。
v1.27 中,alpha 特性,允许用户调整分配给 Pod 的 CPU 和内存资源大小,而无需重新启动容器。
这也意味着 Pod 定义中的 resource 字段不能再被视为 Pod 实际资源的指标。监控程序必须 查看 Pod 状态中的新字段来获取实际资源状况。
用户可以控制在资 源调整时容器的行为:
restartPolicy
Pod 状态中添加了新字段 resize:显示上次请求待处理的调整状态
resize的值:
- Proposed:此值表示请求调整已被确认,并且请求已被验证和记录。
- InProgress:此值表示节点已接受调整请求,并正在将其应用于 Pod 的容器。
- Deferred:此值意味着在此时无法批准请求的调整,节点将继续重试。 当其他 Pod 退出并释放节点资源时,调整可能会被真正实施。
- Infeasible:此值是一种信号,表示节点无法承接所请求的调整值。 如果所请求的调整超过节点可分配给 Pod 的最大资源,则可能会发生这种情况。
应用场景
- 正在运行的 Pod 资源限制或者请求过多或过少。
- 一些过度预配资源的 Pod 调度到某个节点,会导致资源利用率较低的集群上因为 CPU 或内存不足而无法调度 Pod。
- 驱逐某些需要较多资源的有状态 Pod 是一项成本较高或破坏性的操作。 这种场景下,缩小节点中的其他优先级较低的 Pod 的资源,或者移走这些 Pod 的成本更低。
使用特性功能,需要配合启用“特性门控”-InPlacePodVerticalScaling
root@vbuild:~/go/src/k8s.io/kubernetes# FEATURE_GATES=InPlacePodVerticalScaling=true ./hack/local-up-cluster.sh
Pod 的持久卷的单个访问模式
k8s v1.22 中引入的一种新的访问模式, 适用于 PersistentVolume(PVs) 和 PersistentVolumeClaim(PVCs)
什么是持久卷的单个访问模式(ReadWriteOncePod)?
此访问模式使你能够将存储卷访问限制在集群中的单个 Pod 上,确保一次只有一个 Pod 可以写入存储卷。
应用场景:对需要单一写入者访问存储的有状态工作负载。
在 v1.27 及更高版本的集群中将默认启用该功能
如何开始使用 ReadWriteOncePod?
ReadWriteOncePod 仅支持 CSI 卷。 在使用此功能之前,你需要将以下 CSI Sidecars更新至以下版本或更高版本:
- csi-provisioner:v3.0.0+
- csi-attacher:v3.3.0+
- csi-resizer:v1.3.0+
要开始使用 ReadWriteOncePod,请创建具有 ReadWriteOncePod 访问模式的 PVC:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: single-writer-only
spec:
accessModes:
- ReadWriteOncePod #仅允许一个容器访问且独占写入权限。
resources:
requests:
storage: 1Gi
Pod 拓扑分布约束
为实现高可用并提升资源利用率,可以使用 拓扑分布约束(Topology Spread Constraints) 来控制 Pod 在集群内故障域之间的分布, 例如区域(Region)、可用区(Zone)、节点和其他用户自定义拓扑域
假设你有一个最多包含二十个节点的集群,你想要运行一个自动扩缩的 工作负载(k8s上运行的应用程序),请问要使用多少个副本?
答案可能是最少 2 个 Pod,最多 15 个 Pod。
考虑一个问题:当只有2个Pod时,如果这两个Pod正好都生成在一个Node节点上,如果该Node节点出现宕机现象,则产生单点故障问题!
考虑另一个问题:假设你有 3 个节点,每个节点运行 5 个 Pod。这些节点有足够的容量能够运行许多副本; 但与这个工作负载互动的客户端分散在三个不同的数据中心(或基础设施可用区),网络延迟可能会高于自己的预期, 由于在不同的可用区之间发送网络流量会产生一些网络成本
通过 topologySpreadConstraints字段进行配置
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# 配置一个拓扑分布约束
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # 可选;自从 v1.25 开始成为 Beta
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # 可选;自从 v1.27 开始成为 Beta
nodeAffinityPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
nodeTaintsPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
### 其他 Pod 字段置于此处
更多信息可以通过kubectl explain Pod.spec.topologySpreadConstraints命令获取,或者参阅 Pod API 调度
部分字段含义
- maxSkew 描述这些 Pod 可能被均匀分布的程度。你必须指定此字段且该数值必须大于零。 其语义将随着
whenUnsatisfiable的值发生变化:
- 如果你选择
whenUnsatisfiable: DoNotSchedule,则maxSkew定义目标拓扑中匹配 Pod 的数量与 全局最小值(符合条件的域中匹配的最小 Pod 数量,如果符合条件的域数量小于 MinDomains 则为零) 之间的最大允许差值。例如,如果你有 3 个可用区,分别有 2、2 和 1 个匹配的 Pod,则MaxSkew设为 1, 且全局最小值为 1。- 如果你选择
whenUnsatisfiable: ScheduleAnyway,则该调度器会更为偏向能够降低偏差值的拓扑域。
minDomains 表示符合条件的域的最小数量。此字段是可选的。域是拓扑的一个特定实例。 符合条件的域是其节点与节点选择器匹配的域。
说明:
minDomains字段是一个 Beta 字段,在 1.25 中默认被禁用。 你可以通过启用MinDomainsInPodTopologySpread特性门控来启用该字段。
- 指定的
minDomains值必须大于 0。你可以结合whenUnsatisfiable: DoNotSchedule仅指定minDomains。- 当符合条件的、拓扑键匹配的域的数量小于
minDomains时,拓扑分布将“全局最小值”(global minimum)设为 0, 然后进行skew计算。“全局最小值” 是一个符合条件的域中匹配 Pod 的最小数量, 如果符合条件的域的数量小于minDomains,则全局最小值为零。- 当符合条件的拓扑键匹配域的个数等于或大于
minDomains时,该值对调度没有影响。- 如果你未指定
minDomains,则约束行为类似于minDomains等于 1。
- topologyKey 是节点标签的键。如果节点使用此键标记并且具有相同的标签值, 则将这些节点视为处于同一拓扑域中。我们将拓扑域中(即键值对)的每个实例称为一个域。 调度器将尝试在每个拓扑域中放置数量均衡的 Pod。 另外,我们将符合条件的域定义为其节点满足 nodeAffinityPolicy 和 nodeTaintsPolicy 要求的域。
- whenUnsatisfiable 指示如果 Pod 不满足分布约束时如何处理:
DoNotSchedule(默认)告诉调度器不要调度。ScheduleAnyway告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对节点进行排序。
- labelSelector 用于查找匹配的 Pod。匹配此标签的 Pod 将被统计,以确定相应拓扑域中 Pod 的数量。 有关详细信息,请参考标签选择算符。
- matchLabelKeys 是一个 Pod 标签键的列表,用于选择需要计算分布方式的 Pod 集合。 这些键用于从 Pod 标签中查找值,这些键值标签与
labelSelector进行逻辑与运算,以选择一组已有的 Pod, 通过这些 Pod 计算新来 Pod 的分布方式。matchLabelKeys和labelSelector中禁止存在相同的键。 未设置labelSelector时无法设置matchLabelKeys。Pod 标签中不存在的键将被忽略。 null 或空列表意味着仅与labelSelector匹配。
借助 matchLabelKeys,你无需在变更 Pod 修订版本时更新 pod.spec。 控制器或 Operator 只需要将不同修订版的标签键设为不同的值。 调度器将根据 matchLabelKeys 自动确定取值。例如,如果你正在配置一个 Deployment, 则你可以使用由 Deployment 控制器自动添加的、以 pod-template-hash 为键的标签来区分同一个 Deployment 的不同修订版。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: foo
matchLabelKeys:
- pod-template-hash
说明:
matchLabelKeys字段是 1.27 中默认启用的一个 Beta 级别字段。 你可以通过禁用MatchLabelKeysInPodTopologySpread特性门控来禁用此字段。
nodeAffinityPolicy 表示我们在计算 Pod 拓扑分布偏差时将如何处理 Pod 的 nodeAffinity/nodeSelector。 选项为:
- Honor:只有与 nodeAffinity/nodeSelector 匹配的节点才会包括到计算中。
- Ignore:nodeAffinity/nodeSelector 被忽略。所有节点均包括到计算中。
如果此值为 nil,此行为等同于 Honor 策略。
说明:
nodeAffinityPolicy是 1.26 中默认启用的一个 Beta 级别字段。 你可以通过禁用NodeInclusionPolicyInPodTopologySpread特性门控来禁用此字段。
nodeTaintsPolicy 表示我们在计算 Pod 拓扑分布偏差时将如何处理节点污点。选项为:
- Honor:包括不带污点的节点以及污点被新 Pod 所容忍的节点。
- Ignore:节点污点被忽略。包括所有节点。
如果此值为 null,此行为等同于 Ignore 策略。
说明:
nodeTaintsPolicy是一个 Beta 级别字段,在 1.26 版本默认启用。 你可以通过禁用NodeInclusionPolicyInPodTopologySpread特性门控来禁用此字段。
Pod 拓扑分布中的最小域数
k8s v1.25 在 topologySpreadConstraints 中引入了两个新字段 nodeAffinityPolicy 和 nodeTaintPolicy 来定义节点
该特性在 v1.25 中作为 Alpha 引入。默认被禁用,因此如果要在 v1.25 中使用此特性, 则必须显式启用特性门控 NodeInclusionPolicyInPodTopologySpread。 在接下来的 v1.26 版本中,相关特性进阶至 Beta 并默认被启用。
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# 配置拓扑分布约束
topologySpreadConstraints:
- maxSkew: <integer>
# ...
nodeAffinityPolicy: [Honor|Ignore]
nodeTaintsPolicy: [Honor|Ignore]
# 在此处添加其他 Pod 字段
nodeAffinityPolicy 字段指示 Kubernetes 如何处理 Pod 的 nodeAffinity 或 nodeSelector 以计算 Pod 拓扑分布。
如果是
Honor,则 kube-scheduler 在计算分布偏差时会过滤掉不匹配nodeAffinity/nodeSelector的节点。如果是
Ignore,则会包括所有节点,不会管它们是否与 Pod 的nodeAffinity/nodeSelector匹配。为了向后兼容,
nodeAffinityPolicy默认为Honor。
nodeTaintsPolicy 字段定义 Kubernetes 计算 Pod 拓扑分布时如何对待节点污点。
如果是
Honor,则只有配置了污点的节点上的传入 Pod 带有容忍标签时该节点才会被包括在分布偏差的计算中。如果是
Ignore,则在计算分布偏差时 kube-scheduler 根本不会考虑节点污点, 因此带有未容忍污点的 Pod 的节点也会被包括进去。为了向后兼容,
nodeTaintsPolicy默认为Ignore。
Kubernetes v1.25 引入了一个名为 matchLabelKeys 的新字段到 topologySpreadConstraints 中。matchLabelKeys 是一个 Pod 标签键列表, 用于选择计算分布方式的 Pod。这些键用于查找 Pod 被调度时的标签值, 这些键值标签与 labelSelector 进行逻辑与运算,为新增 Pod 计算分布方式选择现有 Pod 组。
借助 matchLabelKeys,你无需在修订版变化时更新 pod.spec。 控制器或 Operator 管理滚动升级时只需针对不同修订版为相同的标签键设置不同的值即可。 调度程序将基于 matchLabelKeys 自动完成赋值。例如,如果你正配置 Deployment, 则可以使用由 Deployment 控制器自动添加的 pod-template-hash 的标签键来区分单个 Deployment 中的不同修订版。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: foo
matchLabelKeys:
- pod-template-hash
参考:Kubernetes 1.27:关于加快 Pod 启动的进展
Kubernetes 1.27: 原地调整 Pod 资源 (alpha)
Kubernetes 1.27:持久卷的单个 Pod 访问模式升级到 Beta
Kubernetes 1.27:更多精细粒度的 Pod 拓扑分布策略进阶至 Beta文章来源:https://www.toymoban.com/news/detail-602565.html
Pod 拓扑分布约束文章来源地址https://www.toymoban.com/news/detail-602565.html
到了这里,关于关于K8s的Pod的详解(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[云原生] K8s之pod控制器详解](https://imgs.yssmx.com/Uploads/2024/03/838367-1.png)