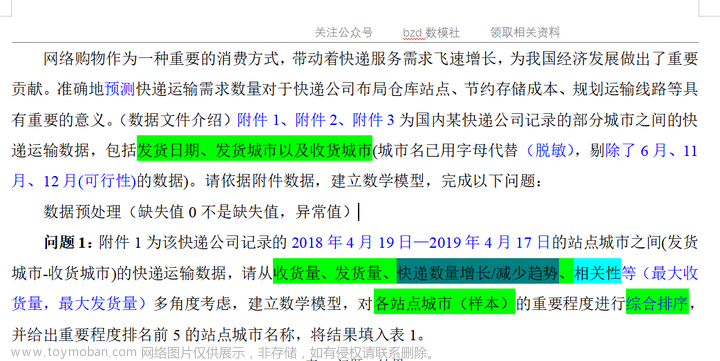
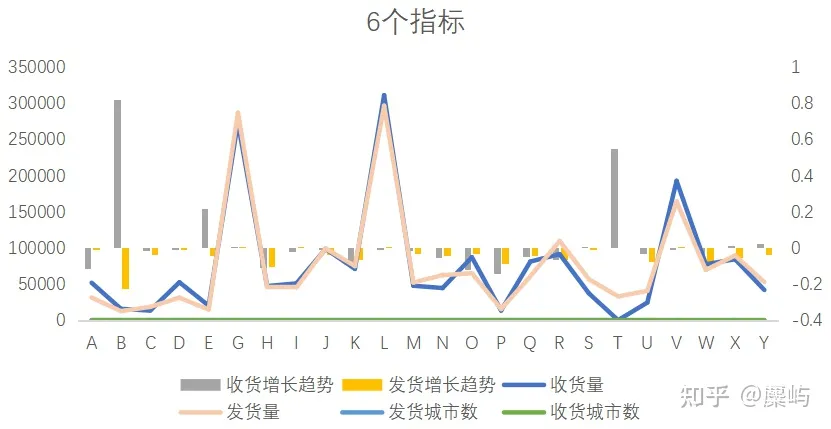
第一问
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
import pandas as pd
# In[4]:
# 导入附件1
data = pd.read_excel(r"C:\Users\Desktop\2023-51MCM-Problem B\附件1(Attachment 1)2023-51MCM-Problem B.xlsx").values
# In[8]:
date = np.unique(data[:,0]) # 日期
city = np.unique(data[:,[1,2]]) # 城市
# In[68]:
#####选取“收货量”相关指标
t1 =[] # 收货总量
t2 =[] # 日均收货量
t3 =[] # 单日最大收货量
t4 =[] # 日收货量极差 @
for i in range(city.shape[0]):
if data[data[:,2]==city[i]].shape[0]!=0:
t1+= [np.sum(data[data[:,2]==city[i]][:,-1])]
t2+= [np.mean(data[data[:,2]==city[i]][:,-1])]
t3+= [np.max(data[data[:,2]==city[i]][:,-1])]
t4+= [np.ptp(data[data[:,2]==city[i]][:,-1])]
else:
t1+= [0]
t2+= [0]
t3+= [0]
t4+= [0]
t1 = np.array(t1)[:,None]
t2 = np.array(t2)[:,None]
t3 = np.array(t3)[:,None]
t4 = np.array(t4)[:,None]
#######选取“发货量”相关指标
t5 =[] # 发货总量
t6 =[] # 日均发货量
t7 =[] # 单日最大发货量
t8 =[] # 日发货量极差 @
for i in range(city.shape[0]):
if data[data[:,1]==city[i]].shape[0]!=0:
t5+= [np.sum(data[data[:,1]==city[i]][:,-1])]
t6+= [np.mean(data[data[:,1]==city[i]][:,-1])]
t7+= [np.max(data[data[:,1]==city[i]][:,-1])]
t8+= [np.ptp(data[data[:,1]==city[i]][:,-1])]
else:
t5+= [0]
t6+= [0]
t7+= [0]
t8+= [0]
t5 = np.array(t5)[:,None]
t6 = np.array(t6)[:,None]
t7 = np.array(t7)[:,None]
t8 = np.array(t8)[:,None]
########选取"快递数量变化"相关指标
nd1 = np.zeros(shape=(date.shape[0],city.shape[0])) # 城市每日的发货
nd2 = np.zeros(shape=(date.shape[0],city.shape[0])) # 城市每日的收货
for i in range(date.shape[0]):
d1 = data[data[:,0]==date[i]]
for j in range(city.shape[0]):
d2 = d1[d1[:,1]==city[j]] # 发
d3 = d1[d1[:,2]==city[j]] # 收
nd1[i,j] = np.sum(d2[:,-1])
nd2[i,j] = np.sum(d3[:,-1])
nd11 = np.array([nd1[i+1]-nd1[i] for i in range(nd1.shape[0]-1)])
nd22 = np.array([nd2[i+1]-nd2[i] for i in range(nd2.shape[0]-1)])
t9 = nd11.max(axis=0)[:,None] # 发货量最大增幅
t10 = nd11.min(axis=0)[:,None] # 发货量最小增幅
t11 = nd11.mean(axis=0)[:,None] # 发货量平均增幅
t12 = nd11.std(axis=0)[:,None] # 发货量增幅标准差 @
t13 = nd22.max(axis=0)[:,None] # 收货量最大增幅
t14 = nd22.min(axis=0)[:,None] # 收货量最小增幅
t15 = nd22.mean(axis=0)[:,None] # 收货量平均增幅
t16 = nd22.std(axis=0)[:,None] # "收货量增幅标准差" @
########选取"相关性"相关指标
t17 = [] # 上游发货城市总数
t18 = [] # 下游发货城市总数
for i in range(city.shape[0]):
d1 = data[data[:,2]==city[i]][:,1]
t17+=[np.unique(d1).shape[0]]
d2 = data[data[:,1]==city[i]][:,2]
t18+=[np.unique(d2).shape[0]]
md1 = np.zeros(shape=(date.shape[0],city.shape[0])) # 每日上游城市数
md2 = np.zeros(shape=(date.shape[0],city.shape[0])) # 每日下游城市数
for i in range(date.shape[0]):
d1 = data[data[:,0]==date[i]]
for j in range(city.shape[0]):
md1[i,j] = np.unique(d1[d1[:,2]==city[j]][:,1]).shape[0]
md2[i,j] = np.unique(d1[d1[:,1]==city[j]][:,2]).shape[0]
t19 = md1.max(axis=0)[:,None] # 单日最大上游城市数
t20 = md2.max(axis=0)[:,None] # 单日最大下游城市数
# In[71]:
datat = t1.copy()
for i in range(2,21):
t = eval("t%d"%i)
datat = np.c_["1",datat,t]
# In[73]:
col = ["收货总量","日均收货量","单日最大收货量","日收货量极差","发货总量","日均发货量","单日最大发货量","日发货量极差",
"发货量最大增幅","发货量最小增幅","发货量平均增幅","发货量增幅标准差","收货量最大增幅","收货量最小增幅","收货量平均增幅",
"收货量增幅标准差","上游发货城市总数","下游发货城市总数","单日最大上游城市数","单日最大下游城市数"]
# In[77]:
#pd.DataFrame(datat,index = city,columns=col).to_excel(r"C:\Users\Desktop\城市指标数据.xlsx")
# In[86]:
# 对数据进行正向化
t4 = (t4.max()-t4)/t4.ptp()
t8 = (t8.max()-t8)/t8.ptp()
t12 = (t12.max()-t12)/t12.ptp()
t16 = (t16.max()-t16)/t16.ptp()
# In[91]:
datat1 = t1.copy()
for i in range(2,21):
t = eval("t%d"%i)
datat1 = np.c_["1",datat1,t]
# In[92]:
# 对数据进行归一化
datat1 = (datat1-datat1.min(axis=0))/datat1.ptp()
# In[93]:
#pd.DataFrame(datat1,index = city,columns=col).to_excel(r"C:\Users\MATH_MGD\Desktop\城市指标数据(正向化-标准化).xlsx")
# In[98]:
# 使用熵权法加权
def EWM(A):
"""
熵权法 the entropy weight method
参数说明:
A :为原始数据矩阵A=a(i,j),表示第i个对象的j个指标,数据结构为np.array,shape=(n,m)
返回值说明
return ST,P,E,G,W,S
ST : 得分排名从小到大
P : 概率矩阵
E : 指标的熵
G : 指标混乱度
W : 指标权重
S : 评价对象得分
"""
n,m = A.shape
if 0 in A:
A += 0.00001
P = A/A.sum(axis=0)
E = (-1/np.log(n))*np.sum(P*np.log(P),axis=0)
G = 1-E
W = G/G.sum()
W = np.round(W,4)
return W
w = EWM(datat1)
# In[99]:
datat2 = datat1*w
# In[100]:
# pd.DataFrame(datat2,index = city,columns=col).to_excel(r"C:\Users\MATH_MGD\Desktop\城市指标数据(加权后).xlsx")
# In[101]:
def min_to_max(x):
y = (np.max(x)-x)/(np.max(x)-np.min(x))
return y.copy()
def mid_to_max(x,c):
y = np.zeros_like(x)
y[x>c] =1-(x[x>c]-c)/np.ptp(x)
y[x<=c] =1-(c-x[x<=c])/np.ptp(x)
return y.copy()
def range_to_max(x,a,b):
y = np.ones_like(x)
y[x>b] =1-(x[x>b]-b)/np.ptp(x)
y[x<a] =1-(a-x[x<a])/np.ptp(x)
return y.copy()
def TOPSIS(data,fm1=[],fm2=[],c=[],fm3=[],a=[],b=[],w=None):
values = data.copy()
if w == None:
w = np.ones(shape=(1,values.shape[1]))
for i in range(len(fm1)):
values[:,fm1[i]] = min_to_max(values[:,fm1[i]])
for i in range(len(fm2)):
values[:,fm2[i]] = mid_to_max(values[:,fm2[i]],c[i])
for i in range(len(fm3)):
values[:,fm3[i]] = range_to_max(values[:,fm3[i]],a[i],b[i])
values1 = (values-values.min(axis=0))/values.ptp(axis=0)
values2 = w*values1
M = values2.max(axis=0)
m = values2.min(axis=0)
D = np.sum((values2-M)**2,axis=1)**0.5
d = np.sum((values2-m)**2,axis=1)**0.5
f = d/(d+D)
return f
TOPSIS(datat2)
# In[ ]:
第二问:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM
import datetime
# In[5]:
data = pd.read_excel(r"C:\Users\Desktop\2023-51MCM-Problem B\附件1(Attachment 1)2023-51MCM-Problem B.xlsx").values
# In[13]:
lines = np.unique(np.array([i[0]+i[1]for i in data[:,[1,2]]]))
lines = np.array([[i[0],i[1]] for i in lines])
# In[29]:
all_pre = []
# In[30]:
for i in range(lines.shape[0]):
y = data[np.logical_and(data[:,1]==lines[i,0],data[:,2]==lines[i,1])][:,-1].astype(np.float64)
# 将数据划分为训练集和测试集
train_size = int(len(y) * 0.8)
train, test = y[:train_size], y[train_size:]
# 数据归一化
scaler = MinMaxScaler()
train = scaler.fit_transform(train.reshape(-1, 1))
test = scaler.transform(test.reshape(-1, 1))
# 创建数据生成器
def create_dataset(data, look_back=1):
X, Y = [], []
for i in range(len(data) - look_back):
X.append(data[i:(i + look_back), 0])
Y.append(data[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 7
X_train, y_train = create_dataset(train, look_back)
X_test, y_test = create_dataset(test, look_back)
# 重塑数据以适应LSTM模型的输入格式
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 创建LSTM模型
model = Sequential()
model.add(LSTM(50, input_shape=(look_back, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1)
# 预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 将预测结果转换回原始尺度
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 计算预测准确性,例如使用均方误差(MSE)作为评估指标
train_mse = np.mean((train_predict - y_train) ** 2)
test_mse = np.mean((test_predict - y_test) ** 2)
# 计算预测日期与最后一个训练日期之间的天数
last_train_date = datetime.date(2019, 4, 17)
start_pred_date = datetime.date(2019, 4, 18)
end_pred_date = datetime.date(2019, 4, 20)
days_to_predict = (end_pred_date-start_pred_date).days
# 使用训练数据的最后一部分来开始预测
input_data = train[-look_back:]
predictions = []
# 预测每一天的货量
for i in range(days_to_predict):
input_data_reshaped = input_data.reshape(1, look_back, 1)
pred = model.predict(input_data_reshaped)
predictions.append(pred[0, 0])
# 更新输入数据,用预测值替换最早的值
input_data = np.roll(input_data, -1)
input_data[-1] = pred
# 将预测值转换回原始尺度
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1))
tdays = []
# 打印预测结果
for i, pred in enumerate(predictions, start=1):
pred_date = start_pred_date + datetime.timedelta(days=i - 1)
tdays += [pred[0]]
all_pre+=[tdays]
# In[41]:
all_pre = np.array(all_pre)
all_pre
#pd.DataFrame(np.c_["1",lines,all_pre],columns=["起点","终点","2023年4月28日","2023年4月29日"]).to_excel(r"C:\Users\MATH_MGD\Desktop\第二问预测结果.xlsx")
# In[ ]:
第三问:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM
import datetime
# In[7]:
data = pd.read_excel(r"C:\Users\Desktop\2023-51MCM-Problem B\附件2(Attachment 2)2023-51MCM-Problem B.xlsx").values
# In[14]:
lines = np.unique(np.array([i[0]+i[1]for i in data[:,[1,2]]]))
lines = np.array([[i[0],i[1]] for i in lines])
date = np.unique(data[:,0])
# In[15]:
d = np.zeros(shape=(lines.shape[0],date.shape[0]))
d1 = np.zeros(shape=(lines.shape[0],date.shape[0]))
for i in range(d.shape[0]):
data1 = data[np.logical_and(data[:,1]==lines[i,0],data[:,2]==lines[i,1])]
for j in range(d.shape[1]):
data2 = data1[data1[:,0]==date[j]]
if data2.shape[0]==0:
d[i,j]=0
d1[i,j]=0
else:
d[i,j]=1
d1[i,j]=data2[0,-1]
# In[20]:
all_pre1 = []
def create_dataset(data, look_back=1):
X, Y = [], []
for i in range(len(data) - look_back):
X.append(data[i:(i + look_back), 0])
Y.append(data[i + look_back, 0])
return np.array(X), np.array(Y)
for i in range(lines.shape[0]):
y = d[i]
# 将数据划分为训练集和测试集
train_size = int(len(y) * 0.8)
train, test = y[:train_size], y[train_size:]
# 数据归一化
scaler = MinMaxScaler()
train = scaler.fit_transform(train.reshape(-1, 1))
test = scaler.transform(test.reshape(-1, 1))
# 创建数据生成器
look_back = 7
X_train, y_train = create_dataset(train, look_back)
X_test, y_test = create_dataset(test, look_back)
# 重塑数据以适应LSTM模型的输入格式
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 创建LSTM模型
model = Sequential()
model.add(LSTM(50, input_shape=(look_back, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X_train, y_train, epochs=20, batch_size=1, verbose=1)
# 预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 将预测结果转换回原始尺度
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 计算预测准确性,例如使用均方误差(MSE)作为评估指标
train_mse = np.mean((train_predict - y_train) ** 2)
test_mse = np.mean((test_predict - y_test) ** 2)
# 计算预测日期与最后一个训练日期之间的天数
last_train_date = datetime.date(2019, 4, 17)
start_pred_date = datetime.date(2019, 4, 18)
end_pred_date = datetime.date(2019, 4, 20)
days_to_predict = (end_pred_date-start_pred_date).days
# 使用训练数据的最后一部分来开始预测
input_data = train[-look_back:]
predictions = []
# 预测每一天的货量
for i in range(days_to_predict):
input_data_reshaped = input_data.reshape(1, look_back, 1)
pred = model.predict(input_data_reshaped)
predictions.append(pred[0, 0])
# 更新输入数据,用预测值替换最早的值
input_data = np.roll(input_data, -1)
input_data[-1] = pred
# 将预测值转换回原始尺度
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1))
tdays = []
# 打印预测结果
for i, pred in enumerate(predictions, start=1):
pred_date = start_pred_date + datetime.timedelta(days=i - 1)
tdays += [pred[0]]
all_pre1+=[tdays]
all_pre1 = np.array(all_pre1)
# In[21]:
all_pre = []
def create_dataset(data, look_back=1):
X, Y = [], []
for i in range(len(data) - look_back):
X.append(data[i:(i + look_back), 0])
Y.append(data[i + look_back, 0])
return np.array(X), np.array(Y)
for i in range(lines.shape[0]):
y = d1[i]
y[y==0]=y.mean()
# 将数据划分为训练集和测试集
train_size = int(len(y) * 0.8)
train, test = y[:train_size], y[train_size:]
# 数据归一化
scaler = MinMaxScaler()
train = scaler.fit_transform(train.reshape(-1, 1))
test = scaler.transform(test.reshape(-1, 1))
# 创建数据生成器
look_back = 7
X_train, y_train = create_dataset(train, look_back)
X_test, y_test = create_dataset(test, look_back)
# 重塑数据以适应LSTM模型的输入格式
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 创建LSTM模型
model = Sequential()
model.add(LSTM(50, input_shape=(look_back, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X_train, y_train, epochs=20, batch_size=1, verbose=1)
# 预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 将预测结果转换回原始尺度
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 计算预测准确性,例如使用均方误差(MSE)作为评估指标
train_mse = np.mean((train_predict - y_train) ** 2)
test_mse = np.mean((test_predict - y_test) ** 2)
# 计算预测日期与最后一个训练日期之间的天数
last_train_date = datetime.date(2019, 4, 17)
start_pred_date = datetime.date(2019, 4, 18)
end_pred_date = datetime.date(2019, 4, 20)
days_to_predict = (end_pred_date-start_pred_date).days
# 使用训练数据的最后一部分来开始预测
input_data = train[-look_back:]
predictions = []
# 预测每一天的货量
for i in range(days_to_predict):
input_data_reshaped = input_data.reshape(1, look_back, 1)
pred = model.predict(input_data_reshaped)
predictions.append(pred[0, 0])
# 更新输入数据,用预测值替换最早的值
input_data = np.roll(input_data, -1)
input_data[-1] = pred
# 将预测值转换回原始尺度
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1))
tdays = []
# 打印预测结果
for i, pred in enumerate(predictions, start=1):
pred_date = start_pred_date + datetime.timedelta(days=i - 1)
tdays += [pred[0]]
all_pre+=[tdays]
all_pre = np.array(all_pre)
# In[23]:
all_pre1[all_pre1>0.5]=1
# In[25]:
all_pre1[all_pre1<=0.5]=0
# In[30]:
p2 = all_pre*all_pre1
# In[36]:
#pd.DataFrame(np.c_["1",lines,all_pre1,p2],columns=["起点","终点","28号是否开通","29号是否开通","28号预测值","29号预测值"]).to_excel(r"C:\Users\Desktop\第三问结果.xlsx")
# In[ ]:
第四问:
4(23)
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
import pandas as pd
# In[4]:
for i in range(1,82):
pd.DataFrame([]).to_excel(r"C:\Users\Desktop\23\{}.xlsx".format(i))
# In[9]:
data = pd.read_excel(r"C:\Users\MATH_MGD\Desktop\23\{}.xlsx".format(1),index_col=0).values.copy()
for i in range(2,82):
data+=pd.read_excel(r"C:\Users\MATH_MGD\Desktop\23\{}.xlsx".format(i),index_col=0).values.copy()
# In[11]:
pd.DataFrame(data).to_excel(r"C:\Users\Desktop\23\{}.xlsx".format("总"))
# In[17]:
R = pd.read_excel(r"C:\Users\Desktop\23\额定装货量R.xlsx",index_col=0).values
F = pd.read_excel(r"C:\Users\Desktop\23\固定成本F.xlsx",index_col=0).values
# In[19]:
np.sum((1+(data/R)**3)*F)
# In[ ]:
4(24)
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
import pandas as pd
# In[2]:
# for i in range(1,82):
# pd.DataFrame([]).to_excel(r"C:\Users\Desktop\23\{}.xlsx".format(i))
# In[7]:
data = pd.read_excel(r"C:\Users\Desktop\24\{}.xlsx".format(1),index_col=0).values.copy()
for i in range(2,81):
data+=pd.read_excel(r"C:\Users\Desktop\24\{}.xlsx".format(i),index_col=0).values.copy()
# In[8]:
pd.DataFrame(data).to_excel(r"C:\Users\Desktop\24\{}.xlsx".format("总"))
# In[9]:
R = pd.read_excel(r"C:\Users\Desktop\24\额定装货量R.xlsx",index_col=0).values
F = pd.read_excel(r"C:\Users\Desktop\24\固定成本F.xlsx",index_col=0).values
# In[10]:
np.sum((1+(data/R)**3)*F)
# In[ ]:
# 16432.059402286315
# 22715.650305793395
4(25)
#!/usr/bin/env python
# coding: utf-8
# In[11]:
import numpy as np
import pandas as pd
# In[12]:
# for i in range(1,82):
# pd.DataFrame([]).to_excel(r"C:\Users\Desktop\23\{}.xlsx".format(i))
# In[13]:
data = pd.read_excel(r"C:\Users\Desktop\25\{}.xlsx".format(1),index_col=0).values.copy()
for i in range(2,81):
data+=pd.read_excel(r"C:\Users\Desktop\25\{}.xlsx".format(i),index_col=0).values.copy()
# In[14]:
pd.DataFrame(data).to_excel(r"C:\Users\Desktop\25\{}.xlsx".format("总"))
# In[15]:
R = pd.read_excel(r"C:\Users\Desktop\24\额定装货量R.xlsx",index_col=0).values
F = pd.read_excel(r"C:\Users\Desktop\24\固定成本F.xlsx",index_col=0).values
# In[16]:
np.sum((1+(data/R)**3)*F)
# In[ ]:
# 16432.059402286315
# 22715.650305793395
4(26)4(27)文章来源:https://www.toymoban.com/news/detail-602761.html
第五问:文章来源地址https://www.toymoban.com/news/detail-602761.html
#!/usr/bin/env python
# coding: utf-8
# In[68]:
import numpy as np
import pandas as pd
from sklearn.neighbors import KernelDensity
import matplotlib.pyplot as plt
# 中文的使用
import matplotlib as mpl
mpl.rcParams["font.sans-serif"]=["kaiti"] # 设置中文字体
mpl.rcParams["axes.unicode_minus"]=False # 设置减号不改变
# In[69]:
data = pd.read_excel(r"C:\Users\Desktop\22(7-9).xlsx").values
date = np.unique(data[:,0])
lines = np.unique([i[0]+i[1]for i in data[:,[1,2]]])
lines = np.array([[i[0],i[1]] for i in lines])
line_mean = []
line_min = []
xu = []
f_mean = []
f_std = []
mt = np.zeros(shape=(lines.shape[0],date.shape[0]))
for i in range(lines.shape[0]):
d1 = data[np.logical_and(data[:,1]==lines[i,0],data[:,2]==lines[i,1])][:,-1]
rq = data[np.logical_and(data[:,1]==lines[i,0],data[:,2]==lines[i,1])][:,0]
line_mean+=[d1.mean()]
line_min +=[d1.min()]
gd =d1.mean()-2*d1.std()
gd=0 if gd<0 else gd
xu +=[gd]
d2 = d1-(gd)
f_mean += [d2.mean()]
f_std += [d2.std()]
for j in range(rq.shape[0]):
mt[i,date==rq[j]] = d2[j]
xu = np.array(xu)
print("22年3季度固定需求",np.c_["1",lines,np.round(xu)])
print("22年3季度非固定需求均值标准差\n",np.c_["1",lines,np.round(f_mean,4),np.round(f_std,4)])
# In[70]:
pd.DataFrame(np.c_["1",lines,np.round(xu)],columns=["起点","终点","固定需求"]).to_excel(r"C:\Users\Desktop\第五问_固定需求(22年3季度).xlsx")
# In[71]:
pd.DataFrame(np.c_["1",lines,np.round(f_mean,4),np.round(f_std,4)],columns=["起点","终点","均值","标准差"]).to_excel(r"C:\Users\Desktop\第五问_非固定需求(均值与标准差)(22年3季度).xlsx")
# In[72]:
pd.DataFrame(np.c_["1",lines,mt],columns=np.r_["0",["起点","终点"],date]).to_excel(r"C:\Users\Desktop\第五问_非固定需求(22年3季度).xlsx")
# In[73]:
sc = np.array([["V","N"],["V","Q"],["J","I"],["O","G"]])
# In[74]:
i=0
for i in range(2):
d1 = data[np.logical_and(data[:,1]==sc[i,0],data[:,2]==sc[i,1])][:,-1]
d2 = d1-(d1.mean()-d1.min())
# 示例数据(请用实际非固定需求数据替换)
sample_data = d2.reshape(-1, 1)
# KDE模型实例化
kde = KernelDensity(kernel='gaussian', bandwidth=5).fit(sample_data)
# 指定评估点(根据实际需求调整范围和间隔)
evaluation_points = np.linspace(d2.min(), d2.max(), num=300).reshape(-1, 1)
# 评估KDE模型
log_density = kde.score_samples(evaluation_points)
density = np.exp(log_density)
# 绘制KDE结果和直方图
fig, ax = plt.subplots()
ax.plot(evaluation_points, density, label='KDE')
ax.hist(sample_data, bins=5, density=True, alpha=0.5, color='blue', label='直方图')
ax.set_xlabel(f'{sc[i,0]}->{sc[i,1]}(非固定需求)',fontsize=14)
ax.set_ylabel('概率密度',fontsize=14)
ax.legend(fontsize=14)
plt.show()
pd.DataFrame(np.c_["1",evaluation_points,density[:,None]],columns=["非固定需求量","概率密度"]).to_excel(r"C:\Users\Desktop\{}_{}(非固定需求).xlsx".format(sc[i,0],sc[i,1]))
# In[75]:
data = pd.read_excel(r"C:\Users\Desktop\23(1-3).xlsx").values
date = np.unique(data[:,0])
lines = np.unique([i[0]+i[1]for i in data[:,[1,2]]])
lines = np.array([[i[0],i[1]] for i in lines])
line_mean = []
line_min = []
xu = []
f_mean = []
f_std = []
mt = np.zeros(shape=(lines.shape[0],date.shape[0]))
for i in range(lines.shape[0]):
d1 = data[np.logical_and(data[:,1]==lines[i,0],data[:,2]==lines[i,1])][:,-1]
rq = data[np.logical_and(data[:,1]==lines[i,0],data[:,2]==lines[i,1])][:,0]
line_mean+=[d1.mean()]
line_min +=[d1.min()]
gd =d1.mean()-2*d1.std()
gd=0 if gd<0 else gd
xu +=[gd]
d2 = d1-(gd)
f_mean += [d2.mean()]
f_std += [d2.std()]
for j in range(rq.shape[0]):
mt[i,date==rq[j]] = d2[j]
xu = np.array(xu)
print("23年1季度固定需求",np.c_["1",lines,np.round(xu)])
print("23年1季度非固定需求均值标准差\n",np.c_["1",lines,np.round(f_mean,4),np.round(f_std,4)])
# In[76]:
pd.DataFrame(np.c_["1",lines,np.round(xu)],columns=["起点","终点","固定需求"]).to_excel(r"C:\Users\Desktop\第五问_固定需求(23年第1季度).xlsx")
# In[77]:
pd.DataFrame(np.c_["1",lines,np.round(f_mean,4),np.round(f_std,4)],columns=["起点","终点","均值","标准差"]).to_excel(r"C:\Users\Desktop\第五问_非固定需求(均值与标准差)(23年1季度).xlsx")
# In[78]:
pd.DataFrame(np.c_["1",lines,mt],columns=np.r_["0",["起点","终点"],date]).to_excel(r"C:\Users\Desktop\第五问_非固定需求(23年1季度).xlsx")
# In[79]:
for i in range(2,4):
d1 = data[np.logical_and(data[:,1]==sc[i,0],data[:,2]==sc[i,1])][:,-1]
d2 = d1-(d1.mean()-d1.min())
# 示例数据(请用实际非固定需求数据替换)
sample_data = d2.reshape(-1, 1)
# KDE模型实例化
kde = KernelDensity(kernel='gaussian', bandwidth=5).fit(sample_data)
# 指定评估点(根据实际需求调整范围和间隔)
evaluation_points = np.linspace(d2.min(), d2.max(), num=300).reshape(-1, 1)
# 评估KDE模型
log_density = kde.score_samples(evaluation_points)
density = np.exp(log_density)
# 绘制KDE结果和直方图
fig, ax = plt.subplots()
ax.plot(evaluation_points, density, label='KDE')
ax.hist(sample_data, bins=5, density=True, alpha=0.5, color='blue', label='直方图')
ax.set_xlabel(f'{sc[i,0]}->{sc[i,1]}(非固定需求)',fontsize=14)
ax.set_ylabel('概率密度',fontsize=14)
ax.legend(fontsize=14)
plt.show()
pd.DataFrame(np.c_["1",evaluation_points,density[:,None]],columns=["非固定需求量","概率密度"]).to_excel(r"C:\Users\Desktop\{}_{}(非固定需求).xlsx".format(sc[i,0],sc[i,1]))
# In[ ]:
# In[ ]:
# In[ ]:
到了这里,关于2023五一数模b题思路分享2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!