一、Switch语句
语法规则:
①语句中的变量类型可以是byte、short、int或者char;从javaSE5开始支持枚举类型; javaSE7开始,switch支持String。
②没有break时,后续case的语句都会执行
二、修饰符
访问修饰符
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
public : 对所有类可见。使用对象:类、接口、变量、方法
protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。
非访问修饰符
static: 可以使用classname.variablename 和classname.methodname的方式访问
final: final方法可以被子类继承,但不能被子类重写
abstract:抽象类的唯一目的是为了将来对该类进行扩充
synchronized:修饰的方法同一时间只能被一个线程访问
transient:序列化的对象包含被transient修饰的变量时,JVM跳过该特定的变量。
(transient单词含义:转瞬即逝的,短暂的;暂住的,(工作)临时的)
持久化:持久化是将程序数据在持久状态和瞬时状态间转换的机制。 持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备。
所以被transient修饰的变量不会被持久化处理。
volatile: 翻译 – >易变的,动荡不定的,反复无常的;(情绪)易变的,易怒的,突然发作的;(液体或固体)易挥发的,易气化的;(计算机内存)易失的。
volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
三、HDFS
HDFS(Hadoop distribute file system)是一个分布式的文件管理系统。文件上传之后就无法修改,适合一次写入,多次读出的场景。
1 优缺点
优点
- 高容错性:某一个副本丢失以后,他可以自动恢复
- 适合处理大数据:无论是文件很大,还是文件数量很大,都可以处理。
- 可以构建在廉价机器上,通过多副本机制,提供可靠性。
缺点
- 不适合低延时数据访问:做不到毫秒级的存储数据
- 无法高效对大量的小文件进行存储:会占用NameNode大量的内存来存储文件目录和块信息。小文件存储的寻址时间会超过读取时间,违反了HDFS的设计目标。
- 不支持并发写入、文件随机修改:仅仅支持数据追加,不支持文件随机修改。
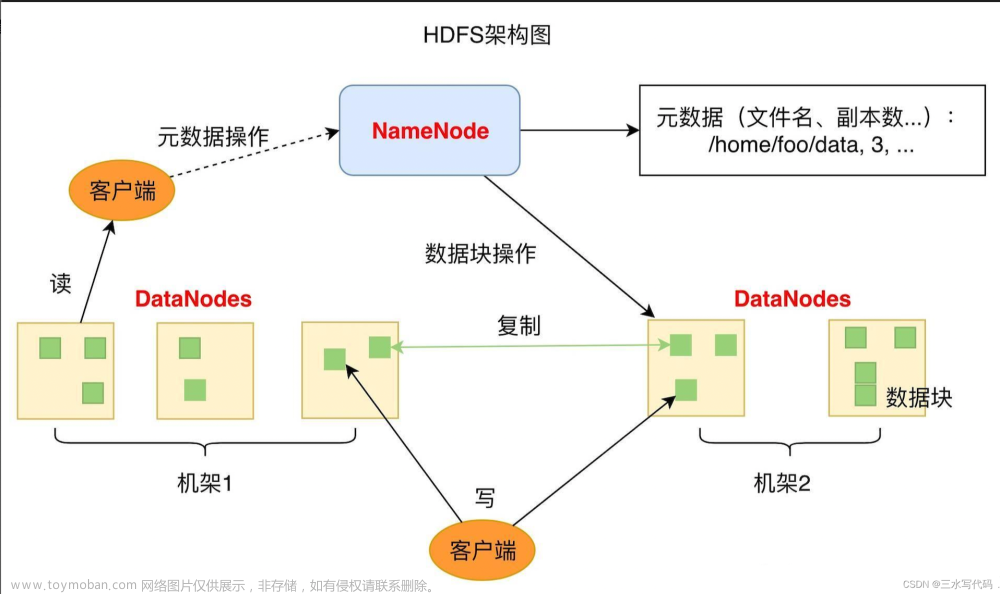
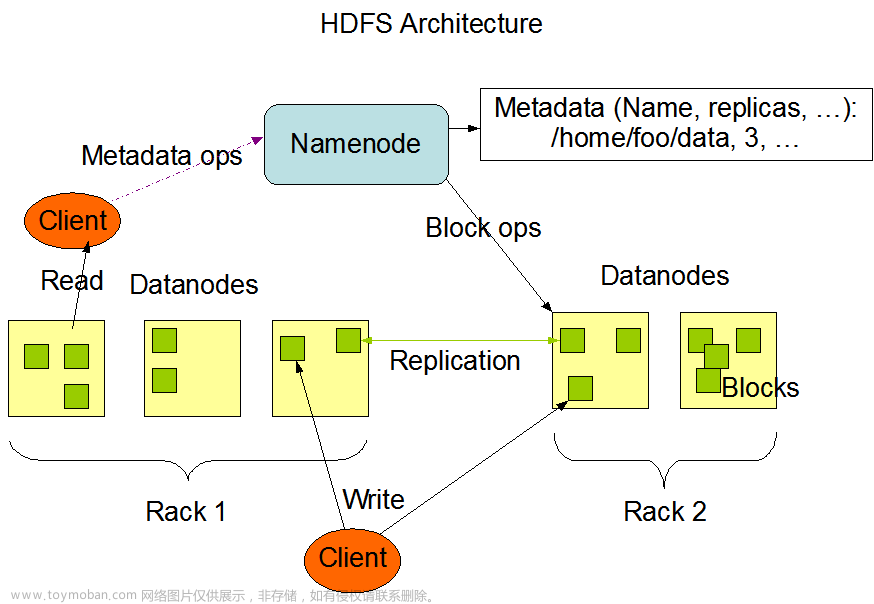
2 HDFS架构
①NameNode: 就是Master,它是一个主管,管理者
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端的读写请求
②DataNode: 就是Slave. NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作;
③客户端
(1)文件切分:根据NameNode的文件大小进行切分,Hadoop2.x/3.x默认为128MB,1.x版本为64M;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,增删改查相关操作;
④Secondary NameNode: 并非NameNode的热备。当NameNode挂掉的时候,并不能马上替换NameNode并提供服务。
(1)辅助NameNode, 分担其工作量,比如定期合并Fsimage和Edits, 并推送给NameNode;
(2)在紧急情况下,可辅助恢复NameNode; 文章来源:https://www.toymoban.com/news/detail-602890.html
文章来源:https://www.toymoban.com/news/detail-602890.html
3 文件块
寻址时间为传输时间的1%时,为最佳状态。机械硬盘建议128MB,固态硬盘建议256MB。文章来源地址https://www.toymoban.com/news/detail-602890.html
- 文件块太小,会增加寻址时间,程序一直在找块的开始位置。
- 文件块太大,从磁盘传输数据的时间会明显大于定位这个块位置所需的时间,导致处理这块数据时,会非常慢。
到了这里,关于Hadoop中HDFS的架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!