前言
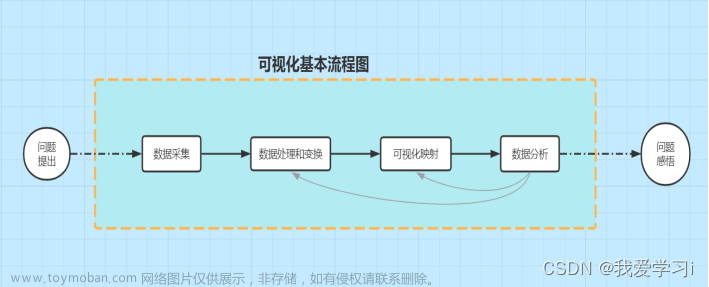
前面我们已经学习了如何使用 python 的 pyecharts 模块来实现数据可视化,将数据经过处理后以折线图、地图以及柱状图的形式展现出来,那么这篇文章我将以一个例子为大家分享如何结合 面向对象 的思想来实现数据可视化。
实现数据可视化的过程
-
收集数据:收集需要进行可视化的数据,并确保数据的准确性和完整性。数据可以来源于各种渠道,如数据库、日志文件、API等。
-
清洗和整理数据:对收集到的数据进行清洗和整理,包括去除重复值、处理缺失数据、处理异常值等。确保数据的质量和一致性。
-
选择合适的可视化工具:根据数据的类型和需求,选择合适的可视化工具。常见的可视化工具包括Tableau、Power BI、matplotlib、D3.js等。
-
选择可视化类型:根据数据的特点和表达需求,选择合适的可视化类型。常见的可视化类型包括条形图、折线图、散点图、饼图、雷达图等。
-
设计可视化界面:根据数据的特点和可视化类型,设计出合适的可视化界面。界面应该简洁明了,注重重点数据的展示和对比。
-
绘制图表:使用选择的可视化工具,绘制出设计好的可视化图表。根据需求,添加合适的图例、标签、标题等,以增加图表的可读性和易理解性。
-
数据交互和分析:为可视化界面添加交互功能,如鼠标悬停显示数据详情、点击图表元素进行筛选等。通过交互功能,用户可以进行数据的进一步分析和探索。
-
调整和优化:根据用户反馈和需求变化,对可视化界面进行调整和优化。可以修改图表样式、改进交互功能、添加新的数据维度等。
-
分享和发布:将完成的可视化结果分享和发布,可以通过导出静态图片、生成报告、嵌入网页等方式进行展示和共享。
-
监控和更新:定期监控可视化结果,及时更新数据和调整可视化界面,保持可视化结果的时效性和准确性。
我们实现的是简单的数据可视化,今天主要针对收集数据、清洗和整理数、选择可视化类型、绘制图表几个方面来讲解。
实现数据可视化


我们以两个月的销售额来举例,将两个月的销售额以图像的形式展现出来。
读取数据
这里我们已经将数据打包放进了文件中,所以我们需要做的就是将数据从文件中读取出来。由于两个文件的格式是不同的,一种是 csv 格式,一个是 JSON 格式,所以读取和处理数据的方式也是不同的,这里分两个方法来分别读取和处理不同的数据。
这里提供一个接口来方便后面两个类的使用。
class FileReader():
def reader(self) -> list[Record]:
pass
什么是接口?接口是指类当中的方法都没有具体的方法体,用 pass 来表示方法体,而具体的方法实现由继承他的子类来实现。
读取文件的方式基本相同,但是为了后面的处理数据操作,我们还是分两个类来实现。
读取csv格式文件数据
class TestFileReader(FileReader):
def __init__(self,path):
self.path = path
def reader(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF8")
data_lines = f.readlines()
f.close()
读取JSON格式文件数据
class JsonFileReader(FileReader):
def __init__(self,path):
self.path = path
def reader(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF8")
data_lines = f.readlines()
f.close()
创建对象
将每一条销售信息当作对象。
class Record():
def __init__(self,data,order_id,money,province):
self.data = data
self.order_id = order_id
self.money = money
self.province = province
def __str__(self):
return f'{self.data},{self.order_id},{self.money},{self.province}'
__ init __ 构造方法来对属性进行初始化。__ str __ 方法来方便我们的打印。
处理数据
我们将数据数据都转换为对象,每个对象代表一条销售信息,然后将这些对象都存储在列表中。
TestFileReader 类
class TestFileReader(FileReader):
def __init__(self,path):
self.path = path
def reader(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF8")
data_lines = f.readlines()
f.close()
list1 : list[Record] = []
for line in data_lines:
line = line.strip() # strip方法用来处理每一行数据后面的 \n
data_list = line.split(",")
record = Record(data_list[0],data_list[1],int(data_list[2]),data_list[3])
list1.append(record)
return list1
JsonFileReader 类
class JsonFileReader(FileReader):
def __init__(self,path):
self.path = path
def reader(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF8")
data_lines = f.readlines()
f.close()
list1 : list[Record] = []
for line in data_lines:
line = line.strip()
data_dict = json.loads(line) # JSON类型数据转换为python数据类型
record = Record(data_dict["date"],data_dict["order_id"],int(data_dict["money"]),data_dict["province"])
list1.append(record)
return list1
数据分析
将同一天的销售额累加在一起,并且使用字典这种数据类型来存储,为什么要使用字典呢?因为字典的key值不允许出现重复,这也就对应了我们的日期,而值就对应了我们的销售额。
test_file = TestFileReader("D:/桌面/2011年1月销售数据.txt")
json_file = JsonFileReader("D:/桌面/2011年2月销售数据JSON.txt")
list1 = test_file.reader()
list2 = json_file.reader()
data_list = list1 + list2 # 将两天的数据综合到一起
data_dict = {}
for record in data_list:
if record.data in data_dict.keys(): # 如果该日期已经存储了,那么我们将存储的值与当前值相加之后再存入
data_dict[record.data] += record.money
else: # 如果没有出现,那么就直接存入数据
data_dict[record.data] = record.money
绘制柱状图
这个例子我们使用柱状图最能显示出数据的差异,随意我们选择柱状图。
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys()))
bar.add_yaxis("销售额",list(data_dict.values()),label_opts=LabelOpts(is_show=False)) # 设置系列配置项来取消柱状图中数据的显示
bar.set_global_opts(
title_opts=TitleOpts(title="2011年1、2月销售情况")
)
bar.render("2021年1、2月销售情况.html")
整体代码及效果展示
data_define.py 文件
class Record():
def __init__(self,data,order_id,money,province):
self.data = data
self.order_id = order_id
self.money = money
self.province = province
def __str__(self):
return f'{self.data},{self.order_id},{self.money},{self.province}'
file_define.py 文件
from data_define import Record
import json
class FileReader():
def reader(self) -> list[Record]:
pass
class TestFileReader(FileReader):
def __init__(self,path):
self.path = path
def reader(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF8")
data_lines = f.readlines()
f.close()
list1 : list[Record] = []
for line in data_lines:
line = line.strip()
data_list = line.split(",")
record = Record(data_list[0],data_list[1],int(data_list[2]),data_list[3])
list1.append(record)
return list1
class JsonFileReader(FileReader):
def __init__(self,path):
self.path = path
def reader(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF8")
data_lines = f.readlines()
f.close()
list1 : list[Record] = []
for line in data_lines:
line = line.strip()
data_dict = json.loads(line)
record = Record(data_dict["date"],data_dict["order_id"],int(data_dict["money"]),data_dict["province"])
list1.append(record)
return list1
main.py 文件文章来源:https://www.toymoban.com/news/detail-603058.html
from data_define import Record
from file_define import *
from pyecharts.charts import Bar
from pyecharts.options import TitleOpts,LabelOpts,InitOpts
from pyecharts.globals import ThemeType
test_file = TestFileReader("D:/桌面/2011年1月销售数据.txt")
json_file = JsonFileReader("D:/桌面/2011年2月销售数据JSON.txt")
list1 = test_file.reader()
list2 = json_file.reader()
data_list = list1 + list2
data_dict = {}
for record in data_list:
if record.data in data_dict.keys():
data_dict[record.data] += record.money
else:
data_dict[record.data] = record.money
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys()))
bar.add_yaxis("销售额",list(data_dict.values()),label_opts=LabelOpts(is_show=False))
bar.set_global_opts(
title_opts=TitleOpts(title="2011年1、2月销售情况")
)
bar.render("2021年1、2月销售情况.html")
 文章来源地址https://www.toymoban.com/news/detail-603058.html
文章来源地址https://www.toymoban.com/news/detail-603058.html
到了这里,关于数据可视化——结合面向对象的思想实现数据可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!