在预测分析领域,决策树是可应用于回归和分类任务的算法之一
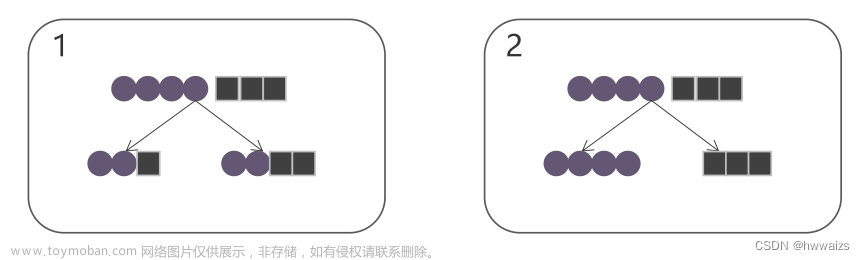
决策树背后的想法是,根据数据集中的特征对当时响应变量的贡献方式,递归地构建一个颠倒的树状结构。
在每次迭代中,将以使得所得模型最小化成本函数的方式选择特征。
该结构从顶部的根节点开始,然后分支并连接到其他节点,最终通向树的终端节点或叶子。
树中的每个节点代表一个特征;每个链接或分支代表一个决策,每个叶子代表一个结果(响应变量的类别或连续值)
优点缺点
决策树背后的简单性在于通过确定任何给定点最重要的特征来创建模型的方式。
由于它不假设变量之间存在线性或任何关系,因此它不仅限于线性或其他相关变量 - 它可以应用于任何数据集。
此外,与许多其他算法不同,在应用决策树之前不需要进行大量的数据操作
它有时被称为贪婪算法,因为它在每一点都试图最大程度地最小化成本函数。
这种过度尝试最小化成本函数可能会导致训练数据的过度拟合,从而导致在测试数据上进行预测时出现高方差。通常采用剪枝或装袋等技术来解决这一问题
决策树的类型
根据所使用的成本最小化技术,决策树可以有多种分类,其中重要的几个是:
CART(分类和回归树)— 使用基尼杂质测量来计算每次迭代的信息增益
ID3(迭代二分器 3)— 使用熵函数计算信息增益指标
在这里,我们将研究 ID3 决策树的熵函数并设计一种算法来计算任何迭代的熵
熵与信息增益
每个特征的每个唯一值的熵计算如下:
该特征的信息增益计算如下:
其中,E(T) 是响应变量的熵
执行
我们将在这里使用 UCI 数据存储库中的 Balloons 数据集。它代表实验的不同条件
根据 4 个预测特征确定响应变量“膨胀”:颜色、大小、行为和年龄
# data = Balloons 数据集
# N = 列数
# target = 响应变量
# en = 目标变量的熵
# cats = 响应变量的唯一值计数字典
# vals = 当前特征的唯一值计数字典
for i in range(0,N-1):
x=data.columns[i]
ig=0
for k, v in vals.items():
ent=0
for k1 in cats.keys():
n=data.loc[(data[target]==k1) & (data[x]==k), x].count() prob = -(n/v) * np.log(n
/v) #计算概率
ent= ent + prob #计算熵
info = info + ((v/total)*ent) #计算信息
gain = en - ig #计算信息增益
第一次迭代的背后 让我们看看如何使用上述函数计算第一次迭代的熵和信息增益
Calculate Entropy & Information Gain w.r.t. “Inflated”
Column “color”:
‘YELLOW’: 32, ‘PURPLE’: 28
“Color” YELLOW with “Inflated” TRUE — 19
“Color” YELLOW with “Inflated” FALSE — 13
“Color” PURPLE with “Inflated” TRUE — 12
“Color” PURPLE with “Inflated” FALSE — 16
E(YELLOW) = (-19/32)*log(19/32) + (-13/32)*log(13/32) = 0.675
E(PURPLE) = (-12/28)*log(12/28) + (-16/28)*log(16/28) = 0.682
I(Color) = (32/60) * 0.675 + (28/60) * 0.682= 0.678
IG(Color) = I(Inflated) — I(Color) = 0.693–0.678= 0.0149
同样,计算剩余列的熵和信息增益:
IG(Size) = 0.0148
IG(Act) = 0.131
IG(Age) = 0.130
选择列“Act”作为根节点,因为它具有最高的信息增益
下一步 然后,该算法将递归执行以下步骤来构建决策树(超出了本文的范围):
具有最高信息增益的特征将被指定为该迭代的节点
该节点的分支将由该节点可能的每个唯一值(条件/决策)形成
分支将通向其他节点,具体取决于后续特征和条件
如果没有进一步可能的特征或条件,将创建叶节点并且不会进行进一步的分支
这样,就可以递归地构建决策树。
然后可以应用该模型来预测响应变量的值或类别
UCI机器学习数据集仓库中的Balloons数据集:
-
数据集信息
-
数据集名称:Balloons -
数据样本数:76个 -
特征数:4个 -
目标变量:1个,气球的颜色(Yellow或Purple)
-
特征信息
-
Color:气球的颜色(Yellow,Purple) -
Size:气球的大小(小,中,大) -
Act:气球的行为(向上漂浮,向下坠落) -
Age:气球的年龄(新,中,老)
-
数据集结构
每行表示一个气球样本,包含Color目标变量和其他3个特征。
-
数据集用途
这个数据集可以用于分类任务,以气球的其他特征预测其颜色。可以建立分类模型对颜色进行预测。
-
数据分析
可以计算信息熵、信息增益等,为分类模型选择最优特征。也可以绘制特征分布,了解样本之间的相关性。
以上简要概述了这个小数据集的基本情况。它提供了一个使用真实数据进行分类建模练习的良好 starters例子。文章来源:https://www.toymoban.com/news/detail-603322.html
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-603322.html
到了这里,关于信息熵和决策树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[架构之路-251/创业之路-82]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 商业智能、决策支持系统、知识管理](https://imgs.yssmx.com/Uploads/2024/02/741538-1.png)